
Sprylogics
An Interview with Alex Zivkovic
|
|
In spring 2008, a colleague told me about the Web search system Cluuz.com. I tested the system on several occasions and found its hyperbolic display of relationships among entities in the results set quite useful. I wrote about the company in my Web log. That write up is here. When I revisited the system in late July 2008, I noticed that the interface had been tweaked. The principal changes made it easier for me to point and click my way through the results for my query. The major change, however, was that Cluuz.com makes use of the Yahoo index under the BOSS service. |

BOSS means "Build Your Own Search Engine."
I met with Sprylogics' chief technical officer, Alex Zivkovic, in North York, a suburb of Toronto. We talked at Mezza Notte Trattoria for about one hour before the noon rush arrived. The conversation was as filling as the chef's cheese ravioli.
The full text of my interview with Mr. Zivkovic appears below:
Thanks for meeting me. Would you give me the elevator pitch description of Sprylogics?
Sure, but I am an engineer, not really a marketing person. I can tell you what we typically tell people about our firm. If this goes on too long, stop me.
As I said, I am an engineer and the chief technology officer for Sprylogics International Corp. Sprylogics develops advanced search, analysis, and information display tools and services.
We talk a lot about solutions. We want to help our licensees and customers search large amounts of unstructured data on the Web and in internal corporate databases, and convert it into actionable intelligence.
The core technologies driving Sprylogics' solutions are embedded in the Analyst and Evidens analytical workflow and Cluuz Search Engine platform which enables both consumers and corporate users to search the Internet and internal corporate resources.
Our Cluuz search results are visually displayed through patent pending semantic graphs and result in improved decision making capabilities.
Sprylogics is publicly traded on the Toronto Venture exchange under the symbol TSXV:SPY.
In late 2007 Sprylogics formed a wholly owned US subsidiary to acquire the assets and IP of Devesys, Inc. Now called Devesys Technologies Inc. or DTI – pronounced like "devices" – this wholly owned subsidiary develops case management, tracking and reporting systems. Devesys' clients are mostly Fortune 500-type companies, and we have had good results with companies looking for compliance tools.
There's a Web page on our Sprylogics.com Web site that lists our products. [Editor's note: the link is http://www.sprylogics.com/Solutions.aspx]
What's the origin of Sprylogics?
The founder Avi Shachar was keenly interested in business intelligence. He reviewed most of the tools available to analyze text, and he concluded that he could offer a system that was tailored to the needs of a business professional.
What's your background?
I was one of the founding partners and also the CEO of Intellimerce Inc. I directed the design, development and deployment of custom software solutions in various fields for international clients such as Dun & Bradstreet Canada, LMI and Marsh & McLennan.
I have been associated with some open source business intelligence tools that are currently used by thousands of developers worldwide and by various large companies. As Intellimerce founder I worked on the XML/A council with Microsoft, SAS and Hyperion.
I think you can think of me as a computer scientist and manager.
What brought you to Sprylogics?
Avi is very sound technically, but when you are talking about building a robust and easy-to-use intelligence system, some special expertise is required. My background is in artificial intelligence, although some prefer the term computational intelligence.
We have a very capable management team, and we are focused on exactly what our company slogan says, "Seeing beyond the obvious." Most of the business and competitive intelligence systems require specialized training to use. Some requests require a programmer/ analyst to build a data set. Then the manager must find a way to extract the needed information from the data set. We wanted to provide an intelligence system that could be used by any professional. If the person has only five minutes, then we wanted to provide useful, actionable information within that time parameter.
Technology should reduce the amount a work a busy professional must do, not add to that work.
Didn't the firm receive an infusion of capital earlier this year?
Yes, in April 2008, we entered into an agreement to raise about $2 million through institutional investors and individual shareholders. We are tapping that investment to accelerate our marketing and research and development activities.
Where does Cluuz.com fit in?
We have a number of Web sites of which Cluuz.com is one. [Editor's note: Other Sprylogics Web sites are: Sprylogics, EVIDENS, IntegraDB, and Devesys.]
The Cluuz.com public Web site, which is using the Yahoo index and our proprietary query and intelligence software, is a demonstration of some of our technology. Cluuz.com allows a user to enter a query and get much more useful information than a list of hits in a result set.
For example, in your write up about Cluuz.com, you showed some of our clustering technology.
What caused you to shift to the Yahoo BOSS tie up?
We looked at the Yahoo API, and we decided that the Search BOSS service could level the playing field in the search space for us. We see Yahoo providing an unprecedented level of access to its algorithmic search infrastructure. This, combined with Cluuz's named entity extraction, and patent pending semantic graph technologies, help position us as an innovative solution for those looking for next generation search engine technologies.''
Yes, I also illustrated the entity extraction function. What other features are available on the Cluuz.com site?
So, we have clustering. We have entity extraction. We have a relational ship analysis in a graph format.
I want to point out that for enterprise applications, the Cluuz.com functions are significantly more rich. For example, a query can be run across internal content and external content. The user sees that the internal information is useful but not exactly on point. Our graph technology makes it easy for the user to spot useful information from an external source such as the Web in conjunction with the internal information. With a single click, the user can be looking into those information objects.
We think we have come up with a very useful way to allow an organization to give its professionals an efficient way to search for content that is behind the firewall and on the Web.
The main point, however, is that user does not have to be trained. Our graphical interface makes it obvious what information is available from which source. Instead of formulating complex queries, the person doing the search can scan, click, and browse. Trips back to the search box are options, not mandatory.
Key word search is not meeting the needs of the users in many organizations. What's the feedback you have about your approach?
I'm not visiting customers every day like some of my colleagues. What I hear is that our licensees are pleased with the system. Information retrieval takes less time than some of the previous systems our clients have used. I also hear that training time and engineering support are greatly reduced. From my point of view, I think this is what I as an engineer want to hear.
My team and I are concentrating on some enhancements. The use of graph technology is still somewhat new. We are tracking innovations reported in the technical literature, and, of course, we are working on some features that we think may be useful and somewhat new.
I can't say too much, but with the increasing interest in mobile devices, we think our technology can add some new functionality to these devices.
I look at several new search and content processing systems each week. Recently, I am hearing about real-time content processing. What's Sprylogics' position in the push to real-time indexing?
We know from our licensees that time delays in updating the index often become the main criticism of some systems. Our technology is designed to process content quickly. We try to avoid the term "real time" because latency exists in most systems, even ours.
Our engineers have worked hard to perform multiple text processing operations in an optimized way. Our technology can, in most cases, process content and update the indexes in a minute or less. We keep the details of our method close to the vest. I can say that we use some of the techniques that you and others have identified as characteristic of high-speed systems like those at Google, for example.
We have a number of solutions where rapid information processing is essential. We offer specialized, intelligence-based risk mitigation software solutions which includes the capability to conduct searches of both internal databases and external Web sources where speed of content processing and indexing is essential.
What's your take on the semantic search craze?
I think it's okay for me to say that Sprylogics is part of this semantic search activity. We pay close attention to what companies like Hakia and Powerset are doing. Excuse me, were doing. Powerset was purchased by Microsoft.
We use some semantic techniques in our systems. Semantic technologies can be very useful. One person labeled Cluuz.com a semantic search engine. That's true up to a point. Cluuz.com includes a number of technical methods of which semantic processes are one operation.
One of our technical strengths are the semantic graphs like those you included in your first write up about our company.
[Editor's note: A semantic graph appears below.]
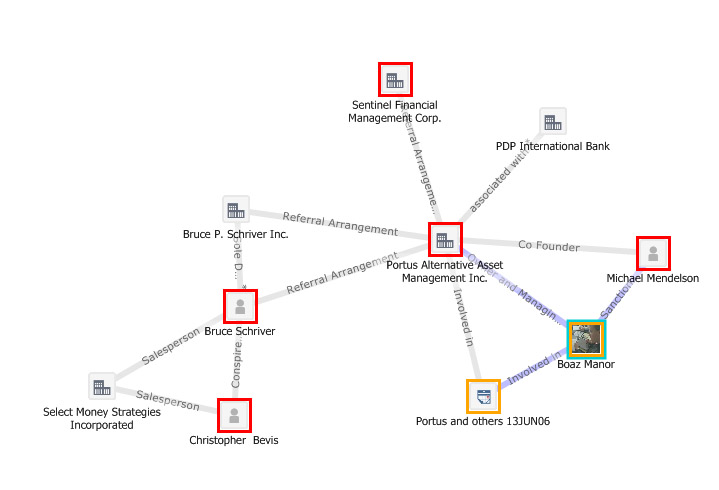
What are the major trends in search in the next six to nine months?
That's a tough question. I think that mobile search will be of more and more interest. Also, the semantic search wave is continuing to build. We think that finding meaning and making information available in more intuitive ways will gain importance as well.
Can you foreshadow some of the innovations in Sprylogics' products?
I can't talk about specifics. We are working to shape our various technologies into more vertical solutions. We have had a number of inquiries from law enforcement professionals about our software. I think you will see us follow these markets and their needs. We will also be implementing some new features in the Cluuz.com technology. Beyond that, I can't say too much.
ArnoldIT Comment
Cluuz.com, like Silobreaker.com, moves well beyond the laundry list approach used by Google. Even the Cuil.com "magazine like" display of results pales in comparison with the results presentation from Cluuz.com. The company's technology seems to be well suited for business and competitive intelligence, law enforcement, and financial content analysis. Unlike the tools from SAS Institute and SPSS, Sprylogics has put usability front and center. But even more important than interface is Sprylogics' effort to make powerful search and relationship analysis functions available without requiring specialized training or any intermediation by a programmer/analyst. The company's technology and solutions warrant a closer look.
Stephen E. Arnold, August 4, 2008