

SchemaLogic Profile Available
December 3, 2013
A new profile is available on the Xenky site today. SchemaLogic is a controlled vocabulary management system. The system combines traditional vocabulary management with an organization wide content management system specifically for indexing words and phrases. The analysis provides some insight into how a subsystem can easily boost the cost of a basic search system’s staff and infrastructure.
Taxonomy became a chrome trimmed buzzword almost a decade ago. Indexing has been around a long time, and indexing has a complete body of practices and standards for the practitioner to use when indexing content objects.
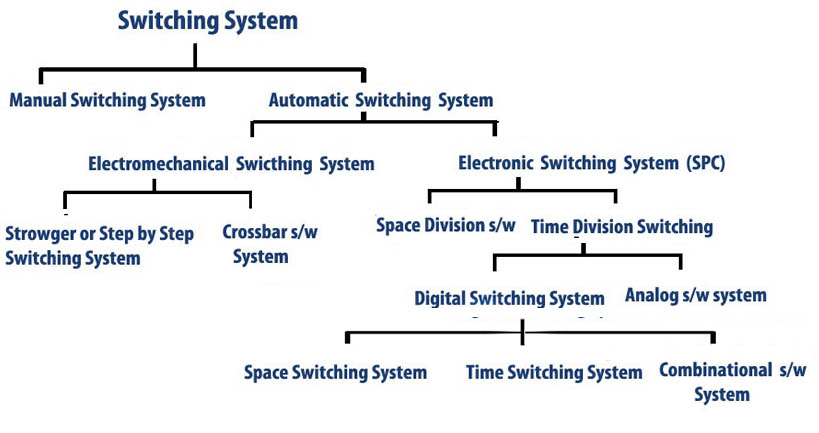
Just what an organization needs to make sense of its text, images, videos, and other digital information/data. At a commercial database publsihing company, more than a dozen people can be involved in managing a controlled term list and classification coding scheme. When a term is misapplied, finding a content object can be quite a challenge. If audio or video are misindexed, the content object may require a human to open, review, and close files until the required imnage or video can be located. Indexing is important, but many MBAs do not understand the cost of indexing until a needed content object cannot be found; for example, in a legal discovery process related to a patent matter. A happy quack to http://swissen.in/swictingsys.php for the example of a single segment of a much larger organization centric taxonomy. Consider managing a controlled term list with more than 20,000 terms and a 400 node taxononmy across a Fortune 500 company or for the information stored in your laptop computer.
Even early birds in the search and content processing sector like Fulcrum Technologies and Verity embraced controlled vocabularies. A controlled term list contains forms of words and phrases and often the classification categories into which individual documents can be tagged.
The problem was that lists of words had to be maintained. Clever poobahs and mavens created new words to describe allegedly new concepts. Scientists, engineers, and other tech types whipped up new words and phrases to help explain their insights. And humans, often loosey goosey with language, shifted meanings. For example, when I was in college a half century ago, there was a class in “discussion.” Today that class might be called “collaboration.” Software often struggles with these language realities.
What happens when “old school” search and content processing systems try to index documents?
The systems can “discover” terms and apply them. Vendors with “smart software” use a range of statistical and linguistic techniques to figure out entities, bound phrases, and concepts. Other approaches include sucking in dictionaries and encyclopedias. The combination of a “knowledgebase” like Wikipedia and other methods works reasonably well.
Somewhere along the line, the behavior of humans and the algorithms have to bump up against one another. At that point, the word lists have to be maintained. The idea is that “language drift” can lead “smart software” astray. The static lists have to be updated. I am not sure how many 20 somethings know what the “cat’s pajamas” means.
The surprise for those who license search and content processing systems is that maintaining, mapping, tuning, and editing term lists is expensive work. Humans with special skills are needed.
Then add the challenge of making sure that a term is related in a meaningful, appropriate way to another term. When a researcher discoveries a new species of cat, that animal must be plugged into the type of biological hierarchy taught in my former high school. The notions of genus and species have an impact on how indexing systems work for the benefit or detriment of a lowly human users of a search or content processing system.
Finally, figuring out word and term definitions and relationships is difficult. What terms is used to index an electric vehicle, a vehicle with electric and gasoline engines, a vehicle with a hydrogen propulsion system? Who figures this out for the organization’s search and retrieval system? What mapping must take place to index an article about alternative fuel vehicles in the engineering department and the marketing department? Get the term wrong and some system users may not be able to find the information required to do a job.
If this type of description of indexing and classification seems unfamiliar, you would not have licensed the SchemaLogic system. SchemaLogic was one of the high profile companies that offered a master control room to manage metadata.
The idea, as an expert indexer will tell you, is a good one. Humans cannot manage tens of thousands of index terms and classifications without some type of support system. For Samuel Johnson, slips of paper and assistants worked reasonably well but not fast enough for his publisher.
In today’s zip zip world, manual methods are expensive and too slow. SchemaLogic’s system provided a way to manage the index terms and help a licensee make sure that these controlled terms were used in other enterprise software systems.
As it turned out, SchemaLogic followed the fate of many other search and content processing companies. The firm had smart people. The company had some initial funding. The early clients were those who understood that a system was needed to manage index terms. Then the need for revenue caused the momentum to slow. The company sold out to another, presumably more capable firm.
In 2005 or so, I prepared a couple of analyses of SchemaLogic. I took a draft of one of the early reports I did and posted it on the Xenky Vendor Profile page. The description and analysis are not the most current, but for a person who wants to get a sense of what’s involved in metadata management, the write up may be helpful.
An interesting point is evident in the write ups now on the Xenky Web site. Each of the companies moves from inception to demise taking a somewhat similar journey. The technology is fascinating but the marketing becomes increasingly important. When the magnetism of the marketing pitch fades, the companies either go out of business like Delphes or end up in the hands of another firm. The technologies get absorbed and the “brand” begins to fade into the background.
Indexing is quite complex. The SchemaLogic system is an excellent example of how one small component of an information retrieval system reveals even more startling complexity. Indexing, when carried to an extreme, can require as many resources to implement as the retrieval system itself. Needless to say, the sticker shock of managing index terms can surprise some licensees. Few accountants working out SharePoint costs for one year are able to get their arms around the costs of an ANSI compliant index management system with their first encounter with the process. Accountants do learn, however. Understanding can come quickly.
Do humans index in accordance with the controlled terms? Usually not. Excitement and confusion often accompany ANSI standard indexing methods. In many organizations, “good enough” indexing becomes the norm. Little wonder than humans looking for information resort to sticky notes, work arounds, and cursory searches in the course of solving a business problem. Humans and indexing combine in interesting ways.
Remember if you want to correct, add to, or comment on the profile, please, use the Beyond Search comments form on this page. As with the other profiles, I am providing these free draft analyses on an as is basis. None of these profiles will be updated. These are provided as a historical record, primarily for myself. If you find a profile useful, good. If not, well, no one forced you to read a draft of an early report.
You can find the SchemaLogic analysis here. The index page for the growing list of profiles is at www.xenky.com/vendor-profiles.
Stephen E Arnold, December 3, 2013
Comments
-

- Subscribe to Beyond Search
Feature archive
News archive

-