

IntelTrax Top Stories: September 7 to September 13
September 17, 2012
This week the IntelTrax advanced intelligence blog published articles on current trends related to big data, fraud detection, and analytics solutions that will help both of the previously stated problems.
“Real Time Analytics Makes an Impact” discusses how companies have spent the last couple of years making it so that their analytics solutions have zero lag time.
The article states:
“Operational Intelligence, basically, is real-time analytics over operational and social data. Operational intelligence, or OI as we like to call it, provides three important capabilities. First is real-time visibility over a wide variety of data. Second is real-time insight using real-time continuous analytics, and third is what we call right-time action, which means being able to take action in time to make a measurable difference in the business. We decided to focus on Operational Intelligence because it addresses some very important business problems that we felt were not well served by traditional software products today. These problems include service assurance in telco, social analytics for dynamic selling and brand management, real-time supply chain management, smart grid management in electrical utilities, and dynamic pricing in retail. These are just some of the examples.”
One way that analytics solutions have positively impacted a variety of industries is through the detection of fraud. “Fraud Analytics Deliver on Fine Art Forgeries” explains a new niche in fraud analytics that helps prevent substantial losses from individuals and museums.
The article informs:
“Just as with credit card fraud detection, the data sets created by digital authentication are quite large. Similarly, the modeling tools are extremely sophisticated, looking for patterns that would be unlikely from the painter just as a given purchase would be unlikely for a credit card holder. Zeroing in on the fraud can save an enterprise millions of dollars. Digital authentication is not real-time — it took two days to identify the fake Van Gogh. But in the world of art, that’s more than fast enough.”
When discussing advancements made in the industry, the information is often more well received when it comes from experts in the field. “Analytic News is Best From the Experts” showcases on experts opinion on the topic:
“Werner Vogels, a data guru as chief technology officer for Amazon Web Services, has been touting his interpretation of big data for almost two years. For him, managing a behemoth like Amazon, it’s not exactly what big data is, but what can be done with it.
“Big data is the collection and analysis of large amounts of data to create a competitive advantage,” he told a conference earlier this year.
“I am an infrastructure guy and for me big data is when your data sets become so large that you have to start innovating how to collect, store, organise, analyse and share it.”
Since technology is continuing to progress at rapid rates it is important the companies seek out a data analytics provider that evolves with the times. Digital Reasoning’s solutions, not only will protect your business from fraud, but its automated understanding for Big Data allows companies to find the necessary information they need to stay ahead of the competition.
Jasmine Ashton, September 17, 2012
Sponsored by ArnoldIT.com, developer of Augmentext.
What Can Big Data Do for You?
September 1, 2012
We all know big data has been at the top of the buzzword heap for many moons now. But how does all that hype translate into practical use? ZDNet examines the matter in “How is Big Data Faring in the Enterprise?”
Writer Dion Hinchcliffe begins by identifying three big changes he says are emerging within the big data field. First is the growth of “data-first” thinking; rather than hunting for data that supports an already formed decision, this approach strives to pull insight from the best raw data available. Next is the significant move away from the relational data model which has long held sway. Finally, Hinchcliffe writes:
“The third change is the move towards making big data a more operational component of the way organizations work and how externally-facing products function. While data scientists are often required to get the best outcomes, the results of their work are often applications or data appliances that are usable by just about anyone. Just like Google enabled the layperson to query the entire contents of the Web with a few keywords, the next generation of enterprise big data seems to be about connecting workers with the data landscape of their organizations in a way that doesn’t typically require IT wizards in white robes.”
How practical. And the fate of big data in the enterprise hinges on practicality; CFOs don’t usually like to spend a lot of money simply for hipster credibility. Hinchcliffe looks at several reports on what real businesses are, and are not, doing with this technology. For example, a recent report from Novarica shows just 15 to 20 percent of insurance companies preparing to embrace big data. See the article for more.
The word is out that this technology can provide a competitive advantage, but it seems most businesses are unsure how, or how soon, to grasp it. They need industry-specific solutions, and they need to know how these solutions will integrate with their existing business processes.
It looks like big data has some more marketing to do.
Cynthia Murrell, September 01, 2012
Sponsored by ArnoldIT.com, developer of Augmentext
IntelTrax Top Stories August 10 to August 16
August 20, 2012
This week the IntelTrax blog published some excellent articles on data analytics and search technologies.
One of the most notable analytics developers for Web sites is the search giant Google. “eGoogle Analytics Is No Longer the Only Game in Town” discusses some other options for those companies that are not satisfied with what Google is offering.
The article explains:
“If you operate your own website, analytic software can be crucial in order to track exactly how well your site is doing. Without this software, you can do whatever you want with your site, but you will never know if it is getting more visitors, aside from the amount of comments. When you look at the possible options you have for analytic software, the most popular choice is Google Analytics. However, if you’re not a fan of Google or its Analytics package, there’s no need to fear. There are still a handful of options for you to try out.”
Another article of note discusses the recent dramatic increase of unstructured data in almost every industry. “Growth of Text Analytics in Response to Unstructured Data” discusses the fact that there has also been an explosion of data analytics solution to make sense of all this new data.
When discussing some great solutions available, the article states:
“The Text Analytics market is rapidly consolidating with numerous mergers and acquisitions over the past year. Oracle purchased Endeca for its technology to mash up unstructured data from many different data sources. HP acquired similar technology from Autonomy. IBM picked up Vivisimo and Lexmark for their rich search features. Popularity of Big Data is driving huge interest in the area of text analytics, and that interest is causing the technology to evolve quickly. Text analytics techniques, for example, are becoming increasingly richer and more sophisticated in the information and insight which they can provide.”
While there are a lot of amazing data analytics solutions on the market, many companies are also feeling the effects of a downtrodden economy, so choosing an affordable solution is a very important part of their decision making process. “CFOs Demand a Reduction in Costs and Increase in Competitive Edge” argues that companies are utilizing data analytics solutions as a way to cut costs and create new growth opportunities.
Here are some qualities that companies in New Zealand and Australia are looking for in their products:
“As a discrete process, like CRM, corporate performance management is particularly well suited to a cloud delivery model. It provides organizations greater flexibility, lower capital costs and fast implementations that take weeks rather than six plus months. The end result is customers fast-track uncovering business opportunity. We’re excited about partnering with Host Analytics as it provides our clients a unique value proposition at a time when CFOs and CIOs are telling us that their number one priority is to reduce costs and gain competitive advantage with business analytics.”
The three articles that I have highlighted drive the point home that companies, regardless of their industry, are looking for text analytics solutions that will efficiently make the most of their limited resources and time. Digital Reasoning is a relatively young provider that understand the unique needs of small and midsized companies and offer their Synthesys platform as a solution that provides all the necessary data crunching tools and apps needed for most industries.
Jasmine Ashton, August 20, 2012
Sponsored by ArnoldIT.com, developer of Augmentext
Toast to CMO or CMO Toast
August 17, 2012
Once upon a time, CMO’s were company heroes. They were known to roam about the region promoting business via merit and word of mouth with their merry band of quality sales staff. However, Reuters’ article “CMOs Could Be Extinct, Says Strategic Marketing Growth Expert Lisa Nirell” tells us that times have changed.
Marketing is done via the web now. Merit is gained by comments and testimonies and companies move up the open search ladder to popularity. So, what exactly do today’s marketing personal do?
It appears the CMO’s chair has been replaced by a hard drive:
“Their current perceived role is limiting them from reaching their true potential. When I reflect on the traditionally sought after competencies for a CMO, an image of ‘order taker and service provider’ emerges. Unfortunately, that perception has three limitations: it has become outdated, if not extinct; it restricts Marketing’s true potential; and finally, it perpetuates the belief that anyone can be a marketing expert.”
Thus, CMOs are struggling with career threatening market shifts for these reasons:
- Budgets are shifting.
- Social media exacerbates cross-departmental and customer tensions.
- Pressure to demonstrate a return on investment with Marketing has reached a fever pitch.
- Lines of responsibility across marketing sales are disintegrating.
Who would have thought that chief marketing officers would go from being the toast of the town to just plain toast? Marketing is more important than quality, the service, the product—everything except revenue. Maybe traditional marketing no longer works but this is not the end of the story. It is simply the start of a new chapter.
Jennifer Shockley, August 17, 2012
Sponsored by ArnoldIT.com, developer of Augmentext
IntelTrax Top Stories: August 3 to August 9
August 13, 2012
This week, the IntelTrax blog delivered some informative posts that discuss the issues surrounding big data analytics technology in today’s workforce.
While many articles discuss the prevalence of analytics technology in various industries, “Troubling News for the Analytics Needy” looks at those that are not using it.
A recent survey found:
“Fifty-six percent of respondents indicated they will not be deploying big data analytics applications even beyond 2013, the survey of 255 IT professionals found. Half of those surveyed were data storage professionals at the analyst level; the other half comprised IT managers, vice presidents and CIOs…Survey respondents with no plans to roll out Hadoop or other big data analytics software said doing so requires a specific business case, and in most instances they didn’t see a need for it, according to Marco Coulter, managing director of TheInfoPro’s Cloud Computing Practice.”
Another interesting piece is “Big Data Law Might Be Changing.” It discusses the fear that many have of data analytics technology falling into the wrong hands. One suggestion has been to grant the legal right to accessing personal information of third parties as a way to incentivize transparency.
Writer Patrick Roland concludes:
“This is promising news for a population concerned with the potentially invasive nature of data mining and analytics. After last year’s surprising Supreme Court ruling that basically let Vermont sales reps mine doctors’ patient lists, we are pleased to see reasonable thought return to the table. We can only hope they further find ways that help us utilize this strong technology, while still keeping wrongdoers away.”
One industry that is already seeing lucrative returns on its investment in data analytics technology is Wall Street Investors. “Big Data Promises Big Returns for Stock Investors”
references an article that discusses why savvy stock traders should pay attention to the latest analytics technology.
The article states:
“At the heart of the feed from ORATS is the use of “implied dividends” – the dividend levels implied by prices within the options markets. In the case of equities that have both dividends and exchange-traded options on their stock, the dividend price is a major component in the calculation that traders use to compute a fair price for those options. ORATS runs that calculation backwards to compute “implied dividends”, a measure that reveals the broad consensus of all players in the options market about how much a company will pay as a dividend along the entire option expiration calendar”.
All three of these stories provide different avenues to get to the same conclusion. Investing in data analytics technology is an integral way for companies to make the most out of the unstructured data that is being put out on a daily basis. It is important that you find a reputable company with affordable solutions like Digital Reasoning.
Jasmine Ashton, August 13, 2012
Sponsored by ArnoldIT.com, developer of Augmentext.
Research and Development Innovation: A New Study from a Search Vendor
August 3, 2012
I received message from LinkedIn about a news item called “What Are the Keys to Innovation in R&D?” I followed the links and learned that the “study” was sponsored by Coveo, a search vendor based in Canada. You can access similar information about the study by navigating to the blog post “New Study: The Keys to Innovation for R&D Organizations – Their Own, Unused Knowledge.” (You will also want to reference the news release about the study as well. It is on the Coveo News and Events page.

Engineers need access to the drawings and those data behind the component or subsystem manufactured by their employer. Text based search systems cannot handle this type of specialized data without some additional work or the use of third party systems. A happy quack to PRLog: http://www.prlog.org/10416296-mechanical-design-drawing-services.jpg
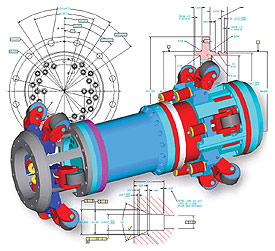{kind=link}
The main of the study, as I interpret it, is marketing Coveo as a tool to facilitate knowledge management. Even though I write a monthly column for the print and online publication KMWorld, I do not have a definition of knowledge management with which I am comfortable. The years I spent at Booz, Allen & Hamilton taught me that management is darned tough to define. Management as a practice is even more difficult to do well. Managing research and development is one of the more difficult tasks a CEO must handle. Not even Google has an answer. Google is now buying companies to have a future, not inventing its future with existing staff.
The unhappy state of many search and content processing companies is evidence that those with technological expertise may not be able to generate consistent and growing revenues. Innovation in search has become a matter of jazzing up interfaces and turning up the marketing volume. The $10 billion paid for Autonomy, the top dog in the search and content processing space, triggered grousing by Hewlett Packard’s top executives. Disappointing revenues may have contributed to the departure of some high profile Autonomy Corporation executives. Not even the HP way can make traditional search technology pay off as expected, hoped, and needed. Search vendors are having a tough time growing fast enough to stay ahead of spiking technical and support costs.
When I studied for a year at the Jesuit-run Duquesne University, I encountered Dr. Frances J. Chivers. The venerable PhD was an expert in epistemology with a deep appreciation for the lively St. Augustine and the comedian Johann Gottlieb Fichte. I was indexing medieval Latin sermons. I had to take “required” courses in “knowledge.” In the mid 1960s, there were not too many computer science departments in the text indexing game, so I assume that Duquesne’s administrators believed that sticking me in the epistemology track would improve the performance of my mainframe indexing software. Well, let me tell you: Knowledge is a tough nut to crack.
Now you can appreciate my consternation when the two words are juxtaposed and used by search vendors to sell indexing. Dr. Chivers did not have a clue about what I was doing and why. I tried to avoid getting involved in discussions that referenced existentialism, hermeneutics, and related subjects. Hey, I liked the indexing thing and the grant money. To this day, I avoid talking about knowledge.
Selected Findings
Back to the study. Coveo reports:
We recently polled R&D teams about how they use and share innovation across offices and departments, and the challenges they face in doing so. Because R&D is a primary creator and consumer of knowledge, these organizations should be a model for how to utilize and share it. However, as we’ve seen in the demand for our intelligent indexing technology, and as revealed in the study, we found that R&D teams are more apt to duplicate work, lose knowledge and operate in soloed, “tribal” environments where information isn’t shared and experts can’t be found. This creates a huge opportunity for those who get it right—to out-innovate and out-perform their competition.
The question I raised to myself was, “How were the responses from Twitter verified as coming from qualified respondents?” And, “How many engineers with professional licenses versus individuals who like Yahoo’s former president just arbitrarily awarded themselves a particular certification were in the study?” Also, “What statistical tests were applied to the results to validate the the data met textbook-recommended margins of error?”
I may have the answers to these questions in the source documents. I have written about “number shaping” at some of the firms with which I have worked, and I have addressed the issue more directly in my opt in, personal news service Honk. (Honk, a free weekly newsletter, is a no-holds-barred look at one hot topic in search and content processing. Those with a propensity to high blood pressure should not subscribe.)
Document Management Is Ripe For eDiscovery
July 18, 2012
If you work in any aspect related to the legal community, you should be aware that eDiscovery generates a great deal of chatter. Like most search and information retrieval functions, progress is erratic.
While eDiscovery, according to the marketers who flock to Legal Tech and other conferences, will save clients and attorneys millions of dollars in the long run, there will still be some associated costs with it. Fees do not magically disappear and eDiscovery will have its own costs that can accrue, even if they may be a tad lower than the regular attorney’s time sheets.
One way to keep costs down is to create a document management policy, so if you are ever taken to court it will reduce the amount of time and money spent in the litigation process. We have mixed feelings about document management. The systems are often problematic because the management guidance and support are inadequate. Software cannot “fix” this type of issue. Marketers, however, suggest software may be up to the task.
JD Supra discusses the importance of a document management plan in “eDiscovery and Document Management.” The legal firm of Warner, Norcross, and Judd wrote a basic strategy guide for JD Supra for people to get started on a document management plan. A plan’s importance is immeasurable:
“With proper document management, you’ll have control over your systems and records when a litigation hold is issued and the eDiscovery process begins, resulting in reduced risk and lower eDiscovery costs. This is imperative because discovery involving electronically stored data — including e-mail, voicemail, calendars, text messages and metadata — is among the most time-consuming and costly phases of any dispute. Ultimately, an effective document management policy is likely to contribute to the best possible outcome of litigation or an investigation.”
The best way to start working on a plan is to outline your purpose and scope—know what you need and want the plan to do. Also specify who will be responsible for each part of the plan—not designating proper authority can leave the entire plan in limbo. Never forget a records retention policy—it is legally require to keep most data for seven years or permanently, but some data can be deleted. Do not pay for data you do not have to keep. Most important of all, provide specific direction for individual tasks, such as scanning, word management, destruction schedule, and observing litigation holds. One last thing, never under estimate the importance of employee training and audit schedules, the latter will sneak up on you before you know it.
If, however, you still are hesitant in drafting a plan can carry some hefty consequences:
- “Outdated and possibly harmful documents might be available and subject to discovery.
- Failure to produce documents in a timely fashion might result in fines and jail time: one large corporation was charged with misleading regulators and not producing evidence in a timely matter and was fined $10 million.
- Destroying documents in violation of federal statutes and regulations may result in fines and jail time: one provision of the Sarbanes-Oxley Act specifies a prison sentence of up to 20 years for someone who knowingly destroys documents with the intent to obstruct a government investigation.”
A document management plan is a tool meant to guide organizations in managing their data, outlining the tasks associated with it, and preparing for eventual audits and litigation procedures. Having a document management plan in place will make the eDiscovery process go quicker, but another way to make the process even faster and more accurate is using litigation support technology and predictive coding, such as provided by Polyspot.
Here at Beyond Search we have a healthy skepticism for automated content processing. Some systems perform quite well in quite specific circumstances. Examples include Digital Reasoning and Ikanow. Other systems are disappointing. Very disappointing. Who are the disappointing vendors? Not in this free blog. Sign up for Honk!, our no holds barred newsletter, and get that opt-in, limited distribution information today.
Whitney Grace, July 18, 2012
Sponsored by Polyspot
LinkedIn and Desperation Marketing: The State Farm Case
July 13, 2012
I am all for making sales. What I found interesting this week (July 8 to July 12, 2012) was a flurry of four spam emails from what I believe to be LinkedIn’s marketing operation. I poked around a little and realized that I had signed up for a Louisville (Kentucky) sales discussion group. When I say “I”, one of the goslings who manages my social presence on LinkedIn joined the group. We are researching the local market for a project, and I assume joining a LinkedIn group of local businesses was a good idea. Wrong.

Is this State Farm’s favorite marketing department lunch meat? Yummy, spam.
The sender was a person who believed that I would be interested in an “Entrepreneurial Career Opportunity” with State Farm Insurance. Now anyone who runs a query for me on Bing, Google, or Yandex will be able to conclude that I probably am a long shot for this type of work:
After reviewing your LinkedIn profile, I was impressed with the experiences you’ve had in your career and would love the chance to chat with you regarding our career opportunities!I am expecting several openings in 2012/2013 in Louisville and surrounding areas. I am looking for qualified candidates to become our next State Farm Agents. We offer a 7 month paid training program at your current salary (subject to a cap of $144K). Following your training you would earn renewable income from an existing book of business, $30,000 in signing bonuses, retirement benefits, worldwide travel incentives, office set-up assistance and more. We are not a franchise, so there is NO franchise fee to start a business with State Farm. We have an 85% success rate on all new agents and the support system that we offer to our agents is the best in the industry. This is a great business opportunity!I’m not necessarily looking for someone who is looking for a job; I’m looking for highly successful individuals…
The job is to earn six figures selling insurance in Louisville. Okay. Now Louisville is in my view wallowing in the economic hog slop. There are quite a few people out of work. I know because we are adding staff to Augmentext, so I have a pretty good sense of the level of desperation in the job market. I don’t understand why State Farm is having such a tough time finding door to door, hammer dialing, bright white teeth and big smile workers. Unemployment is about 15 percent, maybe as high as 20 percent around Harrod’s Creek. What’s up?
I did some poking around and the sender is a State Farm insurance person is based in Nashville and has a colleague named Jerry D. I wrote Ms. Swing, suggesting she do a better job of screening her spam. I also requested that she not spam me with four identical emails in a span of minutes. One works just fine, thank you. She apparently told her boss, “Jerry”, whom I had a tough time understanding on his panting and nerve-tinged voice mail. Jerry wanted me to call him so he could explain the process used by State Farm. He gave me a phone number to call too: 615 692 6149. I did not call. You feel free to call.
The Huber Affair: Demining Now Underway
June 26, 2012
Google is working overtime to keep attention focused on technical issues. You can wallow in the smart software encomium in the New York Times. (See “How Many Computers to Identify a Cat? 16,000” in the June 27, 2012, environmentally unfriendly newspaper or you can give the newspaper’s maybe here, maybe gone link at http://goo.gl/Twl9I.) The Google I/O Conference fast approaches, so there are the concomitant write ups about a Google hardware and news in “Google’s I/O Conference: New Operating System, Tablet”.
But there are two personnel stories which seem to haunt the company at what is the apex of the Google techno-promo machine: Larry Page’s minor voice problem and a person few people outside of Google have heard about. Both of these are potential “information minefields.” Google does not, as far as I know, have an effective demining system in place.

I have avoided commenting directly on the health thing. You can get the story or what passes for a story in “Google CEO Larry Page and the Healthy Way to Answer, ‘What’s Wrong?’” But I do have an opinion about the wizard responsible for Local Search, Maps, Earth, Travel, Payments, Wallet, Offers, and Shopping. I read more about about one Google executive than I expected in “This Exec May Have The Hardest Job At Google, And His Colleagues Are Tired Of Seeing Him Get Trashed In The Press.”
The basic idea, as I understand it, is:
Last week, we [Business Insider] published a story headlined: “Depending On Whom You Ask, This Google Exec Is Either ‘Weak’ Or He Just Drew The Short Straw?
The publication did some digging and learned from “senior sources”:
Their view is that Huber is a top-notch Google executive who asked for the hardest challenge his boss could give him and he got it – in the form of nascent, unproven products and an executive reporting to him that ended up being vastly under-qualified for her job.
The weak link in the Google brain mesh was a person from PayPal. Yikes. A female goofed with some PayPal type projects. The story wraps up:
Smart Folks Found to Think Like the Addled Goose
June 25, 2012
After reading the New Yorker’s “Why Smart People are Stupid,” our publisher Stephen E. Arnold is delighted that he is an addled goose living in rural Kentucky. Must be because his IQ is 70, which is dull normal for a human but okay for a water fowl. (I say that with the greatest respect, Steve.)
[Editor’s note: The guy’s IQ is closer to 50 on a good day and with the wind behind his tailfeatures! Sure, he was mentioned in the Barron’s blog here, but that was obviously a fluke.]
The blog post discusses findings from a recent study in the Journal of Personality and Social Psychology led by Richard West at James Madison University and Keith Stanovich at the University of Toronto. The study builds on the work of Nobel Laureate Daniel Kahneman, who has been studying the human thought process, including when, why, and how it can fail us, for decades.
Researchers posed classic bias problems to almost 500 subjects and studied the results. Like Kahneman, they found that most people usually take the easiest route to an answer rather than the most logical. We refuse to actually do the math. Most of us are also susceptible to “anchor” bias, where we are likely to base our answers on a factor supplied within the question. See the post for examples (and a more extensive discussion), and try the bat-and-ball and lily pad problems for yourself.
The researchers went beyond Kahneman’s work to study the ways in which such thinking errors are linked to intelligence. They found that they are indeed linked—but perhaps not in the way one would expect. Blogger Jonah Lehrer writes:
“The scientists gave the students four measures of ‘cognitive sophistication.’ As they report in the paper, all four of the measures showed positive correlations, ‘indicating that more cognitively sophisticated participants showed larger bias blind spots.’ This trend held for many of the specific biases, indicating that smarter people (at least as measured by S.A.T. scores) and those more likely to engage in deliberation were slightly more vulnerable to common mental mistakes. Education also isn’t a savior; as Kahneman and Shane Frederick first noted many years ago, more than fifty per cent of students at Harvard, Princeton, and M.I.T. gave the incorrect answer to the bat-and-ball question.”
So why are smarties so dumb? No one knows just yet, but I theorize it has to do with the sort of laziness smart kids learn in elementary school—they can get top marks without fully engaging their brains. Perhaps that means when they come across a slippery question as an adult, they fall right into the trap.
Cynthia Murrell, June 25, 2012
Sponsored by PolySpot
-

- Subscribe to Beyond Search
Feature archive
News archive

-