

HP Autonomy: Marketing Collateral from 2011
December 20, 2013
One of the ArnoldIT goslings called to my attention a 2011 PDF white paper with the title (I kid you not):
Human inFormation (sic): Cloud, pan enterprise search, automation, video search, audio search, discovery, infrastructure platfo9rm, Big Data, business process management, mobile search, OEMs, and advanced analytics.
I checked on December 19, 2013, and this PDF was available at http://bit.ly/19Vwkqg.
That covers a lot of ground even for HP with or without Autonomy. The analysis includes some “factoids”; for example:
- Unstructured data represents 85% of all information but structure information is growing at 22% CAGR
- Unstructured information is growing at 62% CAGR.
- Users upload 35 hours of video every minute
- Unstructured data will grow to over 35 zettabytes by 2020
- Videos on YouTube were viewed 2 billion times per day, 20 times more than in 2006.
You get the idea. With lots of data, information is a problem. I need to pause a moment and catch my breath.
Well, “it’s not just about search.” Again, I must pause. One Mississippi, two Mississippi, and three Mississippi. Okay.
Fundamentally, the ability to understand meaning and automatically process information is all about distance, probabilities, relativeness (sic), definitions, slang, and more. It is an overwhelming and continually growing problem that requires advanced technology to solve.
One technique is to use structured data methods to solve the unstructured problem. (Wasn’t this the approach taken by Fulcrum Technologies, what? 25 or 30 years ago? I just read a profile of Fulcrum that suggested Fulcrum did this first and continues chugging along within the OpenText product line up which competes directly with HP in information archiving.
HP points out, “People are Lazy.” More interesting is this observation, “People are stupid.” I thought about HP’s write off of billions after owning a company for a couple of years, but I assume that HP means “other people” are stupid, not HP people.
Big Data: Is Grilling Better with Math?
December 16, 2013
Is there a connection between Big Data and grilling? Is there a connection between Big Data and your business?
I read “Big Data Beyond Business Intelligence: Rise Of The MBAs.” The write up is chock full of statements about large data sets and the numerical recipes required to tame them. But none of the article’s surprising comments matches one point I noticed.
Here’s the quote:
Software automation can’t improve without reorganizing a company around its data. Consider it organizational self-reflection, learning from every interaction humans have with work-related machines. Collaborative, social software is at the heart of this interaction. Software must find innovative ways to interface data with employees, visualization being the most promising form of data democratization.
I will be the first to admit that the economic revolution has left some businesses reeling, particularly in rural Kentucky. Other parts of the country are, according to some pundits, bursting with health.
Is a business reorganization better with Big Data?

Will Big Data deliver better grilled meat? Buy a copy of this book by Lilly and Gibson and see if there are ways to reorganize the business of grilling around self reflection. Big Data cannot deliver a sure fire winning steak? Will Big Data deliver for other businesses?
But for the business that is working hard to make sales, meet payroll, and serve its customers, Big Data as a concept is one facet of senior managers’ work. Information is important to a business. The idea that more information will contribute to better decisions is one of the buttons that marketers enjoy mashing. Software is useful, but it is by itself not a panacea. Software can sink a business as well as float it.
However, figuring out the nuances buried within Big Data, a term that is invoked, not defined, is difficult. The rise of the data scientist is a reminder that having volumes of data to review requires skills many do not possess. Data integrity is one issue. Another is the selection of mathematical tools to use. Then there is the challenge of configuring the procedures to deliver outputs that make sense.
Elsevier: A Fresh Approach to Work for Hire
December 8, 2013
I do work for hire. The idea, as I implement it, requires someone to pay me; for example, a publisher like Galatea, IDC, or Pandia Press. I then submit written information for that money. The publisher can do with the information whatever the purchaser wants. Some publishers have spotty records of payment, but after working for “real” journalism and publishing outfits for years, slow pay or in some cases no pay is more common than I thought. I like to reflect on my naive understanding of the information business in 1954 when I wrote for money “Burger Boat Drive In” for the St Louis Post Dispatch. Think of it: That time span covers 60 years.
I read “Academia.edu Slammed with Takedown Notices from Journal Publisher Elsevier.” I found the write up amusing. I thought that “real” publishers had cracked down on tricky PhDs and “experts” who posted their research on their blogs or on silly academic or public-service-type Web sites a long time ago.
I was dead wrong. It seems that Elsevier, a renowned scientific and technical publisher, was asleep at the switch. Elsevier owns part of Reed Elsevier, another top flight information outfit. If anyone could locate duplicate content, it would be the experts at Elsevier. After all, at their fingertips were duplicate busting online search tools like LexisNexis text mining and search systems. A mouse click away is Google’s outstanding search system. For the more sophisticated investigator, Elsevier can use tools from Dassault or Yandex to locate improper use of content Elsevier owns.

A happy quack to Wikipedia at http://bit.ly/1d3pH7l
The write up tells me:
“In the past, Elsevier has sent out one or two DMCAs a week,” Price [Academia.edu’s top dog] wrote. “Then, a few weeks ago, Elsevier started sending Academia.edu DMCA take-down notices in batches of a thousand for papers that academics had uploaded to the site. This is what has caused the recent outcry in the blogosphere and Twitter.”
So what’s the big deal?
The article tries to answer my question:
Still, Elsevier’s ramping up of take-down requests is reminiscent of the shake-up happening as a result of the rise of massively open online courses, which have enabled millions to learn at a high level — for free. It could be that the basic premise of Academia.edu will throw things off kilter for publishers and cause them to react. And it even has a bit of the flavor of Aaron Swartz’s efforts to liberate academic papers from the premium site JSTOR.
I am not sure but I don’t think Mr. Swartz weathered the “free content” storm particularly well.
SchemaLogic Profile Available
December 3, 2013
A new profile is available on the Xenky site today. SchemaLogic is a controlled vocabulary management system. The system combines traditional vocabulary management with an organization wide content management system specifically for indexing words and phrases. The analysis provides some insight into how a subsystem can easily boost the cost of a basic search system’s staff and infrastructure.
Taxonomy became a chrome trimmed buzzword almost a decade ago. Indexing has been around a long time, and indexing has a complete body of practices and standards for the practitioner to use when indexing content objects.
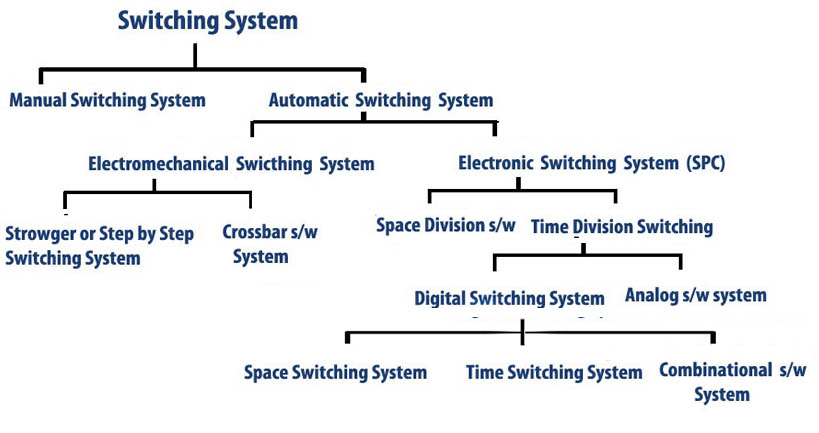
Just what an organization needs to make sense of its text, images, videos, and other digital information/data. At a commercial database publsihing company, more than a dozen people can be involved in managing a controlled term list and classification coding scheme. When a term is misapplied, finding a content object can be quite a challenge. If audio or video are misindexed, the content object may require a human to open, review, and close files until the required imnage or video can be located. Indexing is important, but many MBAs do not understand the cost of indexing until a needed content object cannot be found; for example, in a legal discovery process related to a patent matter. A happy quack to http://swissen.in/swictingsys.php for the example of a single segment of a much larger organization centric taxonomy. Consider managing a controlled term list with more than 20,000 terms and a 400 node taxononmy across a Fortune 500 company or for the information stored in your laptop computer.
Even early birds in the search and content processing sector like Fulcrum Technologies and Verity embraced controlled vocabularies. A controlled term list contains forms of words and phrases and often the classification categories into which individual documents can be tagged.
The problem was that lists of words had to be maintained. Clever poobahs and mavens created new words to describe allegedly new concepts. Scientists, engineers, and other tech types whipped up new words and phrases to help explain their insights. And humans, often loosey goosey with language, shifted meanings. For example, when I was in college a half century ago, there was a class in “discussion.” Today that class might be called “collaboration.” Software often struggles with these language realities.
What happens when “old school” search and content processing systems try to index documents?
The systems can “discover” terms and apply them. Vendors with “smart software” use a range of statistical and linguistic techniques to figure out entities, bound phrases, and concepts. Other approaches include sucking in dictionaries and encyclopedias. The combination of a “knowledgebase” like Wikipedia and other methods works reasonably well.
A Novelist Helps Explain Search Software Erosion
November 29, 2013
Orson Scott Card turned up in a Hacker News item this morning. I followed the link because I was curious about a sci-fi novelist’s views about the death of software companies. As I scanned the short essay, I realized that Mr. Card had touched on several points germane to search, content processing, and analytics companies. I recommend you read the essay that is available on a Carnegie Mellon Web site.
The main idea is:
The environment that nurtures creative programmers kills management and marketing types – and vice versa.
The essay concludes with a passage that is particularly thought provoking:
He [the programmer] suddenly finds that alien creatures control his life. Meetings, Schedules, Reports. And now someone demands that he PLAN all his programming and then stick to the plan, never improving, never tweaking, and never, never touching some other team’s code. The lousy young programmer who once worshiped him is now his tyrannical boss, a position he got because he played golf with some sphincter in a suit. The hive has been ruined. The best coders leave. And the marketers, comfortable now because they’re surrounded by power neckties and they have things under control, are baffled that each new iteration of their software loses market share as the code bloats and the bugs proliferate.
The essay edges up to one of the characteristics of search, content processing, and analytics companies. A talented individual may have a great idea and there may be one, two, or a handful of others who convert capability into creation.
My team and I are reviewing profiles— actually case studies — of search and content processing vendors we have assembled over the last 20 or so years. Most of the vendors begin with a passion to solve a particular problem. For example, the Fulcrum Technologies company in Ottawa, Ontario. A group of innovators left one company, set up another, and then proceeded to bedevil the then market leader Verity.
Fulcrum opened in 1983. The product appears to be available today as a component in an OpenText enterprise solution. But who thinks about Fulcrum today? I am not sure if many, if any, of the original programmers are still working at the company 30 years later. Who runs the Fulcrum unit? What are the innovations it offers? Where is the tension and excitement of the Fulcrum – Verity face offs. Verity has been absorbed into Autonomy and Autonomy has been gobbled by Hewlett Packard. Fulcrum Ful/Text and the WAIS-based SearchServer migrated through an Italian outfit, PC Docs, then Hummingbird, and finally into OpenText.

Image from Cranberry Township. http://bit.ly/180M1il
Several observations:
- The vendors offering search and content processing solutions seem to have a very distinct trajectory that follows Mr. Card’s essay. I can’t think of many search and content processing vendor that has avoided some type of Gravity’s Rainbow trajectory
- Search technology seems to be resistant to innovation. The assertions of Fulcrum and Verity are as fresh and buzzwordy today as they were decades ago.
Vocus Hits the Big Time: The New York Times That Is
November 25, 2013
Who cares about news releases? Apparently quite a few folks do. I read “Swatting at a Swarm of Public Relations Spam.” I thought the write up was interesting, but it seemed short on facts. Here’s the key passage in my opinion:
Woo-hoo.
I liked this part. Also interesting was this passage:
But this one step seemed insufficient. P.R. spam is fed by companies that hire P.R. companies that pay database companies like Vocus, or their handful of competitors. So if you want to focus on root causes, you must ask: Why would any company spend money to blanket reporters with email they didn’t ask for and almost surely don’t want?
We have tested one of the Vocus systems and discovered some interesting factoids. Keep in mind that your mileage may vary:
ITEM. I did a story for Citizentekk.com based on my research for an uptown investment back. We submitted a short news release to PR Web, a Vocus “property.” The publicity professional I use reported that PR Web told her that I was not a recognized authority to PR Web. Furthermore, the information about Google’s investments in synthetic biology were not known so the news release would not be distributed. I found this interesting because the investment bank who commissioned the initial research published a report and the Citizentekk story generated some buzz and follow on commentary.

Is PR spam a food? Image source: http://goo.gl/kSKJEZ
ITEM. One of the editors for the Search Wizards Speak series of interviews tracked down the co founder of Silobreaker. This is an intelligence oriented online system that has a very strong following among the police and intelligence services in the European Community. We were told that my publicity person had to verify who she was and then provide two phone numbers for me and a valid email address. This was after PR Web had my Visa card and the short news release highlighting two key points in the interview.,
ITEM: Vocus pays its president $5 million per year. (Source: Hoover’s Company Records). At the same time, the October 23, 2013 quarterly financial results reported declining revenue ($45.217 millio0n against $46.615 million a year earlier). The net loss was $3.85 million against a net loss of 3.851 a year earlier. (You will need a subscription to Reportlinker to view other details or you can dig out the numbers at http://goo.gl/VeAH6g)
ITEM: Vocus is involved in a legal matter with an outfit called BWP Media USA doing business as Pacific Coast News. I am no attorney so the matter may be without merit. The dispute seems to involve copyright violations. Source: US District Court, Maryland, Case 8:13-cv-03322-RWT. I would reproduce the image attached to the legal document I saw but I found it unsettling.
Search Boundaries. Explode.
November 14, 2013
I read a quite remarkable news release. The title? Grab your blood pressure medicine because you may “explode.”
Expertmaker: Artificial Intelligence (AI) Explodes the Boundaries of Enterprise Search
I expect a sign to warn me off. Was it safe to read about such a potentially powerful technology?

Expertmaker Info
Straightaway I poked through my information about search vendors. I did not recall the name “Expertmaker.” I think it is catchy, echoing the Italian outfit Expert System.
Expertmaker is located at www.expertmaker.com. The company offers the following products:
-
Consulting
-
Products that are “an online solution and/or mobile solution.”
-
Big Data Anti Churn. I am not exactly sure what this means, and I did not want to contact Expertmaker to learn more.
-
Flow, a virtual assistant platform.
The technology is positioned as “artificial intelligence.” The description of the company’s technology is located at this link. I scanned the information on the Expertmaker Web site. I noted some points that struck me as interesting, particularly in relation to the news release that triggered my interest. (Who says news releases are irrelevant? Expertmaker has my attention. I suppose that is a good thing, but there are other possible viewpoints too. My attention can be annoying, but, hey, this is a free blog about going “beyond search.”)
First, the label “artificial intelligence” is visible in the description. The AI angle is “machine learning and evolutionary computing.” The point is that the system performs functions that would be difficult using an old fashioned database like DB2, Oracle, or SQL Server. (I assume that the owners of these traditional databases will have some counter arguments to offer.)
Second, the system makes it possible to build search-based applications. (Dassault Exalead has been beating this tom tom for six or seven years. I presume that the Cloud 360 technology is relegated to the user car lot because Expertmaker has rolled into the search dealership.)
Third, a development environment is available, including a “Desktop Artificial Intelligence Toolkit.” There are “solvers.” There are various AI technologies. There is knowledge discovery. There is a “published solution.” And there is this component:
Semantic, value based, meta-data structures allow high precision understanding and value based searches. With the solution you can create your own semantic structures for handling complex solutions.
Okay, this is pretty standard fare for search start ups. I am not sure what the system does, but I looked at examples, including screenshots.
Amazon and Its Money Losing Model
October 27, 2013
I read “Amazon and the Profitless Business Model Fallacy.” The article was the work of a person who once worked at Amazon, departing in 2004. I assume that some of Amazon’s processes are unchanged, but nine years is a long time, even for an addled 70-year-old goose like me.
The main point of the write up is that many people assume that Amazon is a charity. Amazon, the article points out, is “a classic fixed cost business model.” The company uses the Internet:
to get maximum leverage out of its fixed assets, and once it achieves enough volume of sales, the sum total of profits from all those sales exceed its fixed cost base, and it turns a profit. It already has exceeded this hurdle in its past.

Get your T shirt from Zazzle at http://goo.gl/GTm71a
The article asks:
Does Amazon lose money on sales of some individual items? For sure. The first Kindle ebooks that were priced at $9.99 when Amazon had to pay more than that per copy to publisher were one example. Giant, heavy electronics items that Amazon sometimes ships for free when the shipping cost is clearly non-trivial and cost more than the usual thin margins on such goods are another.
The Bezos brilliance takes this approach:
Amazon has decided to continue to invest to arm itself for a much larger scale of business. If it were purely a software business, its fixed cost investments for this journey would be lower, but the amount of capital required to grow a business that has to ship millions of packages to customers all over the world quickly is something only a handful of companies in the world could even afford.
On the subject of Amazon’s interesting financial report, the article states what is obvious to most analysts who have tried to figure out where the money comes from and where the money goes:
The irony of all this is that while Amazon’s public financial statements make it extremely difficult to parse out its various businesses, it is extremely forthright and honest about its business plans and strategy. It’s the reason Jeff continues to reprint its first ever letter to shareholders from 1997 in its annual report every year. The plan is right there before our eyes, but so many continue to refuse to take it at face value. As a reporter, it must be so boring to parrot the same thing from Jeff and his team year after year, so different narratives must be spun when the overall plan has not changed.
The former employee then offers this observation or is it a threat?
If I were an Amazon competitor, I’d actually regard Amazon’s current run of quarterly losses as a terrifying signal. It means Amazon is arming itself to take the contest to higher ground. The retail game is about to become more, not less, punishing.
Several observations:
Amazon is a giant company with customers, cash, and clout. Those who try to get in its way find out that the Amazon business model is not much less forgiving than Google’s. Google has made little headway in online shopping and that suggests some bright folks have bumped into one or two of Amazon’s pointy parts.
Second, price cutting is a great business tactic. Once the competition is gone, then it is pretty easy to move forward. A number of moguls figured this out decades ago. In today’s regulation-soft environment, commercial enterprisers are functioning more or less like nation states. Different economic rules apply to nation states. Individuals who shop at the company store have fewer options.
Third, Amazon is one of the firms developing a monoculture for its customers. Once one gets into the Prime, one-click, personalization approach to online activities, an old adage kicks in:
Like a soft bed, a bad habit is easy to get into and hard to get out of.
Now my interest—now a hobby, not a job—is search and retrieval. How does the Amazon approach work in search. Amazon offers what I call “corset search.” If you want to get into the darned thing, be prepared to experience some push and pull. If you want a cloud based search system, Amazon is, as I wrote in one of my for-fee columns, a “search lazy Susan.” Just dial up an alternative running on the Amazon system.
Easy. Cheap at least at the outset. Mostly reliable. What more could a vendor want? What more would a user want?
That in my view is the problem with the WalMart approach to technology. Amazon is one of the manifestations of the deep divides that continue to fracture behaviors. I am okay with making my way through an increasingly medieval landscape.
I suppose Wall Street is learning that what look like losses may be something else. We have entered the Dimonization Era. Money is not what it seems perhaps?
Stephen E Arnold, October 27, 2013
Oracle and Open Source
October 21, 2013
I will be giving my last public talk in 2013 at the upcoming Search Summit. I am revealing some data about the trajectory of commercial search versus free and open source search. My focus is not just on costs. I will address the elephant in the room that few of the sleek search poobahs elect to ignore—management.
As part of my preparation, I read an interesting public relations and positioning white paper from Oracle. The essay is “The Department of Defense (DoD) and Open Source Software.” You should be able to locate a copy at the Oracle Middleware Web page. But maybe not. Well, take that up with Oracle, Google, and whoever indexes public Web pages.
The argument in the white paper is that open source is useful within the context of commercial software. The premise is that a commercial company develops robust products like Oracle’s database and then rigorously engineers that product to meet the tough standards imposed by the US government. Then, canny engineers will integrate some open source software into that commercial solution. The client—in this case the Microsoft loving Department of Defense—will be able to get the support it needs to handle the demands of global war fighting.
There are three fascinating rhetorical flourishes in the white paper. These are directly germane to the direction some of the discussions of commercial and proprietary versus free and open source software have been moving. I will give a couple of case examples in my talk in early November 2013, and I assume that the slide deck for my talk will find its way into one or more indexing services. I won’t plow that ground again. Below are some new thoughts.
First, the notion that commercial and proprietary software is better than open source software is amusing. I think that any enterprise software is rife with bugs and problems that can never be fixed because there is neither time, money, or appetite to ameliorate the problems. I was at a meeting at the world’s largest software company when one executive said, “There are a couple thousand bugs in Word. Numbering is one issue. We will maybe get around to fixing the problem.” That was six years ago. Guess what? Numbering is still an interesting challenge in a long document. Is Oracle like the world’s largest software company? Oracle has some interesting features in its products? Check out this sample page. Make your own decision. Software has been, is, and will be complicated stuff. The fact that people correlate clicking a hot link with “simple” just adds impetus to the “this is easy” view of modern systems. No software is better. Some works within specific parameters. Push outside the parameters and you find darned exciting things.
Second, the idea that a large bureaucracy can make decisions based on cost benefits is crazy. Worldwide bean counters and lawyers work to nail down assumptions and statements of work that are designed to minimize costs and deliver specific functionality. How is that working out? If I read one more after the fact analysis of the flawed heath insurance Web site, I may unplug my computer and revert to paper and printed books. I did a major study of a government site in 2007. Guess what? The system did not work and still does not work. Are there analyses, reports, and Web pages explaining the issue? Sure. What’s the fix? People either go to a government office and talk to a human or make a phone call in the hope that the human on the other end of the line can address the issue. The computer system? Unchanged. My report? Probably still in a drawer somewhere.
Third, the idea that a publicly traded company cares about open source is amusing. Open source is simply a vehicle to reduce costs to the publicly traded company and generate consulting revenue. The fact is that most of the folks who embrace open source need some help from firms specializing in that open source product. I can name two companies, each with more than $30 million in venture funding, that have a business model built on selling proprietary software, consulting, and engineering services. Open source sure looks like a Trojan horse to me. Why does IBM embrace Lucene yet sell branded products and services? Maybe to eliminate some software acquisition costs and sell consulting.

A happy quack to http://goo.gl/lxKb6I
On one hand, Oracle is correct in pointing out that free and open source software looks cheaper than commercial and proprietary software in terms of licensing fees. Oracle is also correct that the major cost of software has little to do with the license fee.
On the other hand, Oracle adds some mist to the fog surrounding open source. When open source vendors have to generate revenue to pay back investors or build out their commercial business, the costs are likely to be high.
Open source software begins as a public spirited effort, a way to demonstrate programming skills, and a marketing effort. There are other reasons as well. But in today’s world, software is the weak link in most businesses. Systems are getting less reliable, despite the long string of nines that some companies use to prove their systems are wonderful. But like the optical character recognition program that is 99 percent accurate, the more content pushed through these system, the more the errors mount. Xerox continues to struggle with error rates in a technology that was supposed to be a slam dunk.
Net net: Read the Oracle white paper. Then when you work out a budget, focus less on the sizzle of open source and more on the basic management skills it takes to make something work on time and on budget. Remember. Publicly traded companies and open source companies that have taken money from venture capitalists have to generate a profit or they disappear.
The basics are important. The Oracle white paper skips over some of these in its effort to put open source in perspective. Any software project requires attention to detail, pragmatism, technical expertise, and money.
Stephen E Arnold, October 21, 2013
Yandex App Service: More Evidence Search Is Not Enough
October 17, 2013
I have been sifting through decades of reports about search vendors. As my team and I review versions of reports we have sold to azure chip outfits, slick MBAs, and the generally confused management teams—one stark “truth” emerged. You can follow our free analyses of search vendors on Xenky at www.xenky.com/vendor-profiles.
Search is not enough. Not enough magnetism to generate revenue sufficient to maintain the most complex service in the world. Not enough profit to satisfy even the most patient and deep pocketed mother or venture firm. Not enough sizzle to keep the folks turning up for uninspected chicken. Just not enough. Chasing big money with search may be one of those quests some undertake without broader awareness of the difficulty ahead.

The search entrepreneur can triumph over search. A happy quack to http://www.donquijote.cc/.
I read “Search Engine Giant Yandex Launches Cocaine, A Cloud Service To Compete With Google App Engine” and realized that Yandex is more evidence supporting the “truth.” I assume that the story is accurate, but in the world of search and analytics, reality is—shall I say—malleable.
The point of the write up is:
Russian search giant Yandex has launched an open-source platform as a service (PaaS) … that the company says allows developers to build out their own app engines. Yandex, in its documentation, describes [the platform] … as an open-source PaaS system for creating custom cloud-hosting apps that are similar to Google App Engine or Heroku. It supports C++, Python and JavaScript. It is now developing support for Java and Racket.
Observations:
- Search—enterprise flavor and public Web flavor–needs help. The help is apps and advertising.
- Search by itself is not a driver of growth. If it were, why get into the “more than search” business. Apps are not search. Search is no longer precision and recall. It is a weird fantasy land for some dreamers.
- Search does not produce big money. If the big money were available, certain decisions about Yandex’s home country building its own search system and countering Google’s ambitions in Russia would not be a problem. If search were big money, Google would not be an advertising system. Search is just an enabler of other, more lucrative activities.
I am not concerned about Yandex. What interests me is the obviousness of the “truth” that search revenue is a windmill. Language is too slippery. I watched a video on the MIT Video site of a learned panel of search experts. You can give it a whirl at http://goo.gl/tZm0j7. I had to be on my toes. There were some folks charging at search windmills at full gallop.
What’s this Yandex move mean for companies pitching search as the source of limitless revenue?
Interesting question. Some search experts will be saddling up and heading off to attack a windmill. Are there many left in Kentucky? I wager there are some in the Boston area, Silicon Valley, and Moscow.
Stephen E Arnold, October 17, 2013
-

- Subscribe to Beyond Search
Feature archive
News archive

-