

DarkCyber, March 29, 2022: An Interview with Chris Westphal, DataWalk
March 29, 2022
Chris Westphal is the Chief Analytics Officer of DataWalk, a firm providing an investigative and analysis tool to commercial and government organizations. The 12-minute interview covers DataWalk’s unique capabilities, its data and information resources, and the firm’s workflow functionality. The video can be viewed on YouTube at this location.
Stephen E Arnold, March 29, 2022
DarkCyber for June 9, 2020, Is Now Available: AI and Music Composition
June 9, 2020
The DarkCyber for June 9, 2020, presents a critical look at music generated by artificial intelligence. The focus is the award-winning song in the Eurovision AI 2020 competition. The interview discusses the characteristics of AI-generated music, its impact on music directors, how professional musicians deal with machine-created music, and the implications of non-numan music. The program is a criticism of the state-of-the-art for smart software. Instead of focusing on often over-hyped start ups and large companies making increasingly exaggerated claims, the Australian song and the two musicians make clear that AI is a work in progress. You can view the video at https://vimeo.com/427227666.
Kenny Toth, June 9, 2020
Exclusive: DataWalk Explained by Chris Westphal
July 9, 2019
“An Interview with Chris Westphal” provides an in-depth review of a company now disrupting the analytic and investigative software landscape.
DataWalk is a company shaped by a patented method for making sense of different types of data. The technique is novel and makes it possible for analysts to extract high value insights from large flows of data in near real time with an unprecedented ease of use.
DarkCyber interviewed in late June 2019 Chris Westphal, the innovator who co-founded Visual Analytics. That company’s combination of analytics methods and visualizations was acquired by Raytheon in 2013. Now Westphal is applying his talents to a new venture DataWalk.
Westphal, who monitors advanced analytics, learned about DataWalk and joined the firm in 2017 as the Chief Analytics Officer. The company has grown rapidly and now has client relationships with corporations, governments, and ministries throughout the world. Applications of the DataWalk technology include investigators focused on fraud, corruption, and serious crimes.
Unlike most investigative and analytics systems, users can obtain actionable outputs by pointing and clicking. The system captures these clicks on a ribbon. The actions on the ribbon can be modified, replayed, and shared.
In an exclusive interview with Mr. Westphal, DarkCyber learned:
The [DataWalk] system gets “smarter” by encoding the analytical workflows used to query the data; it stores the steps, values, and filters to produce results thereby delivering more consistency and reliability while minimizing the training time for new users. These workflows (aka “easy buttons”) represent domain or mission-specific knowledge acquired directly from the client’s operations and derived from their own data; a perfect trifecta!
One of the differentiating features of DataWalk’s platform is that it squarely addresses the shortage of trained analysts and investigators in many organizations. Westphal pointed out:
…The workflow idea is one of the ingredients in the DataWalk secret sauce. Not only do these workflows capture the domain expertise of the users and offer management insights and metrics into their operations such as utilization, performance, and throughput, they also form the basis for scoring any entity in the system. DataWalk allows users to create risk scores for any combination of workflows, each with a user-defined weight, to produce an overall, aggregated score for every entity. Want to find the most suspicious person? Easy, just select the person with the highest risk-score and review which workflows were activated. Simple. Adaptable. Efficient.
Another problem some investigative and analytic system developers face is user criticism. According to Westphal, DataWalk takes a different approach:
We listen carefully to our end-user community. We actively solicit their feedback and we prioritize their inputs. We try to solve problems versus selling licenses… DataWalk is focused on interfacing to a wide range of data providers and other technology companies. We want to create a seamless user experience that maximizes the utility of the system in the context of our client’s operational environments.
For more information about DataWalk, navigate to www.datawalk.com. For the full text of the interview, click this link. You can view a short video summary of DataWalk in the July 2, 2019, DarkCyber Video available on Vimeo.
Stephen E Arnold, July 9, 2019
Bitext: Exclusive Interview with Antonio Valderrabanos
April 11, 2017
On a recent trip to Madrid, Spain, I was able to arrange an interview with Dr. Antonio Valderrabanos, the founder and CEO of Bitext. The company has its primary research and development group in Las Rosas, the high-technology complex a short distance from central Madrid. The company has an office in San Francisco and a number of computational linguists and computer scientists in other locations. Dr. Valderrabanos worked at IBM in an adjacent field before moving to Novell and then making the jump to his own start up. The hard work required to invent a fundamentally new way to make sense of human utterance is now beginning to pay off.

Dr. Antonio Valderrabanos, founder and CEO of Bitext. Bitext’s business is growing rapidly. The company’s breakthroughs in deep linguistic analysis solves many difficult problems in text analysis.
Founded in 2008, the firm specializes in deep linguistic analysis. The systems and methods invented and refined by Bitext improve the accuracy of a wide range of content processing and text analytics systems. What’s remarkable about the Bitext breakthroughs is that the company support more than 40 different languages, and its platform can support additional languages with sharp reductions in the time, cost, and effort required by old-school systems. With the proliferation of intelligent software, Bitext, in my opinion, puts the digital brains in overdrive. Bitext’s platform improves the accuracy of many smart software applications, ranging from customer support to business intelligence.
In our wide ranging discussion, Dr. Valderrabanos made a number of insightful comments. Let me highlight three and urge you to read the full text of the interview at this link. (Note: this interview is part of the Search Wizards Speak series.)
Linguistics as an Operating System
One of Dr. Valderrabanos’ most startling observations addresses the future of operating systems for increasingly intelligence software and applications. He said:
Linguistic applications will form a new type of operating system. If we are correct in our thought that language understanding creates a new type of platform, it follows that innovators will build more new things on this foundation. That means that there is no endpoint, just more opportunities to realize new products and services.
Better Understanding Has Arrived
Some of the smart software I have tested is unable to understand what seems to be very basic instructions. The problem, in my opinion, is context. Most smart software struggles to figure out the knowledge cloud which embraces certain data. Dr. Valderrabanos observed:
Search is one thing. Understanding what human utterances mean is another. Bitext’s proprietary technology delivers understanding. Bitext has created an easy to scale and multilingual Deep Linguistic Analysis or DLA platform. Our technology reduces costs and increases user satisfaction in voice applications or customer service applications. I see it as a major breakthrough in the state of the art.
If he is right, the Bitext DLA platform may be one of the next big things in technology. The reason? As smart software becomes more widely adopted, the need to make sense of data and text in different languages becomes increasingly important. Bitext may be the digital differential that makes the smart applications run the way users expect them to.
Snap In Bitext DLA
Advanced technology like Bitext’s often comes with a hidden cost. The advanced system works well in a demonstration or a controlled environment. When that system has to be integrated into “as is” systems from other vendors or from a custom development project, difficulties can pile up. Dr. Valderrabanos asserted:
Bitext DLA provides parsing data for text enrichment for a wide range of languages, for informal and formal text and for different verticals to improve the accuracy of deep learning engines and reduce training times and data needs. Bitext works in this way with many other organizations’ systems.
When I asked him about integration, he said:
No problems. We snap in.
I am interested in Bitext’s technical methods. In the last year, he has signed deals with companies like Audi, Renault, a large mobile handset manufacturer, and an online information retrieval company.
When I thanked him for his time, he was quite polite. But he did say, “I have to get back to my desk. We have received several requests for proposals.”
Las Rosas looked quite a bit like Silicon Valley when I left the Bitext headquarters. Despite the thousands of miles separating Madrid from the US, interest in Bitext’s deep linguistic analysis is surging. Silicon Valley has its charms, and now it has a Bitext US office for what may be the fastest growing computational linguistics and text analysis system in the world. Worth watching this company I think.
For more about Bitext, navigate to the firm’s Web site at www.bitext.com.
Stephen E Arnold, April 11, 2017
Yippy Revealed: An Interview with Michael Cizmar, Head of Enterprise Search Division
August 16, 2016
In an exclusive interview, Yippy’s head of enterprise search reveals that Yippy launched an enterprise search technology that Google Search Appliance users are converting to now that Google is sunsetting its GSA products.
Yippy also has its sights targeting the rest of the high-growth market for cloud-based enterprise search. Not familiar with Yippy, its IBM tie up, and its implementation of the Velocity search and clustering technology? Yippy’s Michael Cizmar gives some insight into this company’s search-and-retrieval vision.
Yippy ((OTC PINK:YIPI) is a publicly-trade company providing search, content processing, and engineering services. The company’s catchphrase is, “Welcome to your data.”
The core technology is the Velocity system, developed by Carnegie Mellon computer scientists. When IBM purchased Vivisimio, Yippy had already obtained rights to the Velocity technology prior to the IBM acquisition of Vivisimo. I learned from my interview with Mr. Cizmar that IBM is one of the largest shareholders in Yippy. Other facets of the deal included some IBM Watson technology.
This year (2016) Yippy purchased one of the most recognized firms supporting the now-discontinued Google Search Appliance. Yippy has been tallying important accounts and expanding its service array.

John Cizmar, Yippy’s senior manager for enterprise search
Beyond Search interviewed Michael Cizmar, the head of Yippy’s enterprise search division. Cizmar found MC+A and built a thriving business around the Google Search Appliance. Google stepped away from on premises hardware, and Yippy seized the opportunity to bolster its expanding business.
I spoke with Cizmar on August 15, 2016. The interview revealed a number of little known facts about a company which is gaining success in the enterprise information market.
Cizmar told me that when the Google Search Appliance was discontinued, he realized that the Yippy technology could fill the void and offer more effective enterprise findability. He said, “When Yippy and I began to talk about Google’s abandoning the GSA, I realized that by teaming up with Yippy, we could fill the void left by Google, and in fact, we could surpass Google’s capabilities.”
Cizmar described the advantages of the Yippy approach to enterprise search this way:
We have an enterprise-proven search core. The Vivisimo engineers leapfrogged the technology dating from the 1990s which forms much of Autonomy IDOL, Endeca, and even Google’s search. We have the connector libraries THAT WE ACQUIRED FROM MUSE GLOBAL. We have used the security experience gained via the Google Search Appliance deployments and integration projects to give Yippy what we call “field level security.” Users see only the part of content they are authorized to view. Also, we have methodologies and processes to allow quick, hassle-free deployments in commercial enterprises to permit public access, private access, and hybrid or mixed system access situations.
With the buzz about open source, I wanted to know where Yippy fit into the world of Lucene, Solr, and the other enterprise software solutions. Cizmar said:
I think the customers are looking for vendors who can meet their needs, particularly with security and smooth deployment. In a couple of years, most search vendors will be using an approach similar to ours. Right now, however, I think we have an advantage because we can perform the work directly….Open source search systems do not have Yippy-like content intake or content ingestion frameworks. Importing text or an Oracle table is easy. Acquiring large volumes of diverse content continues to be an issue for many search and content processing systems…. Most competitors are beginning to offer cloud solutions. We have cloud options for our services. A customer picks an approach, and we have the mechanism in place to deploy in a matter of a day or two.
Connecting to different types of content is a priority at Yippy. Even through the company has a wide array of import filters and content processing components, Cizmar revealed that Yippy is “enhanced the company’s connector framework.”
I remarked that most search vendors do not have a framework, relying instead on expensive components licensed from vendors such as Oracle and Salesforce. He smiled and said, “Yes, a framework, not a widget.”
Cizmar emphasized that the Yippy IBM Google connections were important to many of the company’s customers plus we have also acquired the Muse Global connectors and the ability to build connectors on the fly. He observed:
Nobody else has Watson Explorer powering the search, and nobody else has the Google Innovation Partner of the Year deploying the search. Everybody tries to do it. We are actually doing it.
Cizmar made an interesting side observation. He suggested that Internet search needed to be better. Is indexing the entire Internet in Yippy’s future? Cizmar smiled. He told me:
Yippy has a clear blueprint for becoming a leader in cloud computing technology.
For the full text of the interview with Yippy’s head of enterprise search, Michael Cizmar, navigate to the complete Search Wizards Speak interview. Information about Yippy is available at http://yippyinc.com/.
Stephen E Arnold, August 16, 2016
Exclusive Interview: Danny Rogers, Terbium Labs
August 11, 2015
Editor’s note: The full text of the exclusive interview with Dr. Daniel J. Rogers, co-founder of Terbium Labs, is available on the Xenky Cyberwizards Speak Web service at www.xenky.com/terbium-labs. The interview was conducted on August 4, 2015.
Significant innovations in information access, despite the hyperbole of marketing and sales professionals, are relatively infrequent. In an exclusive interview, Danny Rogers, one of the founders of Terbium Labs, has developed a way to flip on the lights to make it easy to locate information hidden in the Dark Web.
Web search has been a one-trick pony since the days of Excite, HotBot, and Lycos. For most people, a mobile device takes cues from the user’s location and click streams and displays answers. Access to digital information requires more than parlor tricks and pay-to-play advertising. A handful of companies are moving beyond commoditized search, and they are opening important new markets such as secret and high value data theft. Terbium Labs can “illuminate the Dark Web.”
In an exclusive interview, Dr. Danny Rogers, one of the founders of Terbium Labs with Michael Moore, explained the company’s ability to change how data breaches are located. He said:
Typically, breaches are discovered by third parties such as journalists or law enforcement. In fact, according to Verizon’s 2014 Data Breach Investigations Report, that was the case in 85% of data breaches. Furthermore, discovery, because it is by accident, often takes months, or may not happen at all when limited personnel resources are already heavily taxed. Estimates put the average breach discovery time between 200 and 230 days, an exceedingly long time for an organization’s data to be out of their control. We hope to change that. By using Matchlight, we bring the breach discovery time down to between 30 seconds and 15 minutes from the time stolen data is posted to the web, alerting our clients immediately and automatically. By dramatically reducing the breach discovery time and bringing that discovery into the organization, we’re able to reduce damages and open up more effective remediation options.
Terbium’s approach, it turns out, can be applied to traditional research into content domains to which most systems are effectively blind. At this time, a very small number of companies are able to index content that is not available to traditional content processing systems. Terbium acquires content from Web sites which require specialized software to access. Terbium’s system then processes the content, converting it into the equivalent of an old-fashioned fingerprint. Real-time pattern matching makes it possible for the company’s system to locate a client’s content, either in textual form, software binaries, or other digital representations.
One of the most significant information access innovations uses systems and methods developed by physicists to deal with the flood of data resulting from research into the behaviors of difficult-to-differentiate sub atomic particles.
One part of the process is for Terbium to acquire (crawl) content and convert it into encrypted 14 byte strings of zeros and ones. A client such as a bank then uses the Terbium content encryption and conversion process to produce representations of the confidential data, computer code, or other data. Terbium’s system, in effect, looks for matching digital fingerprints. The task of locating confidential or proprietary data via traditional means is expensive and often a hit and miss affair.
Terbium Labs changes the rules of the game and in the process has created a way to provide its licensees with anti-fraud and anti-theft measures which are unique. In addition, Terbium’s digital fingerprints make it possible to find, analyze, and make sense of digital information not previously available. The system has applications for the Clear Web, which millions of people access every minute, to the hidden content residing on the so called Dark Web.

Terbium Labs, a start up located in Baltimore, Maryland, has developed technology that makes use of advanced mathematics—what I call numerical recipes—to perform analyses for the purpose of finding connections. The firm’s approach is one that deals with strings of zeros and ones, not the actual words and numbers in a stream of information. By matching these numerical tokens with content such as a data file of classified documents or a record of bank account numbers, Terbium does what strikes many, including myself, as a remarkable achievement.
Terbium’s technology can identify highly probable instances of improper use of classified or confidential information. Terbium can pinpoint where the compromised data reside on either the Clear Web, another network, or on the Dark Web. Terbium then alerts the organization about the compromised data and work with the victim of Internet fraud to resolve the matter in a satisfactory manner.
Terbium’s breakthrough has attracted considerable attention in the cyber security sector, and applications of the firm’s approach are beginning to surface for disciplines from competitive intelligence to health care.
Rogers explained:
We spent a significant amount of time working on both the private data fingerprinting protocol and the infrastructure required to privately index the dark web. We pull in billions of hashes daily, and the systems and technology required to do that in a stable and efficient way are extremely difficult to build. Right now we have over a quarter trillion data fingerprints in our index, and that number is growing by the billions every day.
The idea for the company emerged from a conversation with a colleague who wanted to find out immediately if a high profile client list was ever leaded to the Internet. But, said Rogers, “This individual could not reveal to Terbium the list itself.”
How can an organization locate secret information if that information cannot be provided to a system able to search for the confidential information?
The solution Terbium’s founders developed relies on novel use of encryption techniques, tokenization, Clear and Dark Web content acquisition and processing, and real time pattern matching methods. The interlocking innovations have been patented (US8,997,256), and Terbium is one of the few, perhaps the only company in the world, able to crack open Dark Web content within regulatory and national security constraints.
Rogers said:
I think I have to say that the adversaries are winning right now. Despite billions being spent on information security, breaches are happening every single day. Currently, the best the industry can do is be reactive. The adversaries have the perpetual advantage of surprise and are constantly coming up with new ways to gain access to sensitive data. Additionally, the legal system has a long way to go to catch up with technology. It really is a free-for-all out there, which limits the ability of governments to respond. So right now, the attackers seem to be winning, though we see Terbium and Matchlight as part of the response that turns that tide.
Terbium’s product is Matchlight. According to Rogers:
Matchlight is the world’s first truly private, truly automated data intelligence system. It uses our data fingerprinting technology to build and maintain a private index of the dark web and other sites where stolen information is most often leaked or traded. While the space on the internet that traffics in that sort of activity isn’t intractably large, it’s certainly larger than any human analyst can keep up with. We use large-scale automation and big data technologies to provide early indicators of breach in order to make those analysts’ jobs more efficient. We also employ a unique data fingerprinting technology that allows us to monitor our clients’ information without ever having to see or store their originating data, meaning we don’t increase their attack surface and they don’t have to trust us with their information.
For more information about Terbium, navigate to the company’s Web site. The full text of the interview appears on Stephen E Arnold’s Xenky cyberOSINT Web site at http://bit.ly/1TaiSVN.
Stephen E Arnold, August 11, 2015
Recorded Future: The Threat Detection Leader
April 29, 2015
The Exclusive Interview with Jason Hines, Global Vice President at Recorded Future
In my analyses of Google technology, despite the search giant’s significant technical achievements, Google has a weakness. That “issue” is the company’s comparatively weak time capabilities. Identifying the specific time at which an event took place or is taking place is a very difficult computing problem. Time is essential to understanding the context of an event.
This point becomes clear in the answers to my questions in the Xenky Cyber Wizards Speak interview, conducted on April 25, 2015, with Jason Hines, one of the leaders in Recorded Future’s threat detection efforts. You can read the full interview with Hines on the Xenky.com Cyber Wizards Speak site at the Recorded Future Threat Intelligence Blog.
Recorded Future is a rapidly growing, highly influential start up spawned by a team of computer scientists responsible for the Spotfire content analytics system. The team set out in 2010 to use time as one of the lynch pins in a predictive analytics service. The idea was simple: Identify the time of actions, apply numerical analyses to events related by semantics or entities, and flag important developments likely to result from signals in the content stream. The idea was to use time as the foundation of a next generation analysis system, complete with visual representations of otherwise unfathomable data from the Web, including forums, content hosting sites like Pastebin, social media, and so on.
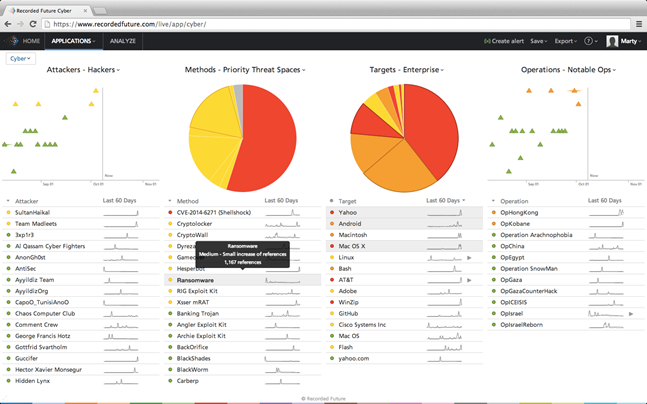
A Recorded Future data dashboard it easy for a law enforcement or intelligence professionals to identify important events and, with a mouse click, zoom to the specific data of importance to an investigation. (Used with the permission of Recorded Future, 2015.)
Five years ago, the tools for threat detection did not exist. Components like distributed content acquisition and visualization provided significant benefits to enterprise and consumer applications. Google, for example, built a multi-billion business using distributed processes for Web searching. Salesforce.com integrated visualization into its cloud services to allow its customers to “get insight faster.”
According to Jason Hines, one of the founders of Recorded Future and a former Google engineer, “When our team set out about five years ago, we took on the big challenge of indexing the Web in real time for analysis, and in doing so developed unique technology that allows users to unlock new analytic value from the Web.”
Recorded Future attracted attention almost immediately. In what was an industry first, Google and In-Q-Tel (the investment arm of the US government) invested in the Boston-based company. Threat intelligence is a field defined by Recorded Future. The ability to process massive real time content flows and then identify hot spots and items of interest to a matter allows an authorized user to identify threats and take appropriate action quickly. Fueled by commercial events like the security breach at Sony and cyber attacks on the White House, threat detection is now a core business concern.
The impact of Recorded Future’s innovations on threat detection was immediate. Traditional methods relied on human analysts. These methods worked but were and are slow and expensive. The use of Google-scale content processing combined with “smart mathematics” opened the door to a radically new approach to threat detection. Security, law enforcement, and intelligence professionals understood that sophisticated mathematical procedures combined with a real-time content processing capability would deliver a new and sophisticated approach to reducing risk, which is the central focus of threat detection.
In the exclusive interview with Xenky.com, the law enforcement and intelligence information service, Hines told me:
Recorded Future provides information security analysts with real-time threat intelligence to proactively defend their organization from cyber attacks. Our patented Web Intelligence Engine indexes and analyzes the open and Deep Web to provide you actionable insights and real-time alerts into emerging and direct threats. Four of the top five companies in the world rely on Recorded Future.
Despite the blue ribbon technology and support of organizations widely recognized as the most sophisticated in the technology sector, Recorded Future’s technology is a response to customer needs in the financial, defense, and security sectors. Hines said:
When it comes to security professionals we really enable them to become more proactive and intelligence-driven, improve threat response effectiveness, and help them inform the leadership and board on the organization’s threat environment. Recorded Future has beautiful interactive visualizations, and it’s something that we hear security administrators love to put in front of top management.
As the first mover in the threat intelligence sector, Recorded Future makes it possible for an authorized user to identify high risk situations. The company’s ability to help forecast and spotlight threats likely to signal a potential problem has obvious benefits. For security applications, Recorded Future identifies threats and provides data which allow adaptive perimeter systems like intelligent firewalls to proactively respond to threats from hackers and cyber criminals. For law enforcement, Recorded Future can flag trends so that investigators can better allocate their resources when dealing with a specific surveillance task.
Hines told me that financial and other consumer centric firms can tap Recorded Future’s threat intelligence solutions. He said:
We are increasingly looking outside our enterprise and attempt to better anticipate emerging threats. With tools like Recorded Future we can assess huge swaths of behavior at a high level across the network and surface things that are very pertinent to your interests or business activities across the globe. Cyber security is about proactively knowing potential threats, and much of that is previewed on IRC channels, social media postings, and so on.
In my new monograph CyberOSINT: Next Generation Information Access, Recorded Future emerged as the leader in threat intelligence among the 22 companies offering NGIA services. To learn more about Recorded Future, navigate to the firm’s Web site at www.recordedfuture.com.
Stephen E Arnold, April 29, 2015
Cyber Wizards Speak Publishes Exclusive BrightPlanet Interview with William Bushee
April 7, 2015
Cyber OSINT continues to reshape information access. Traditional keyword search has been supplanted by higher value functions. One of the keystones for systems that push “beyond search” is technology patented and commercialized by BrightPlanet.
A search on Google often returns irrelevant or stale results. How can an organization obtain access to current, in-depth information from Web sites and services not comprehensively indexed by Bing, Google, ISeek, or Yandex?
The answer to the question is to turn to the leader in content harvesting, BrightPlanet. The company was one of the first, if not the first, to develop systems and methods for indexing information ignored by Web indexes which follow links. Founded in 2001, BrightPlanet has emerged as a content processing firm able to make accessible structured and unstructured data ignored, skipped, or not indexed by Bing, Google, and Yandex.
In the BrightPlanet seminar open to law enforcement, intelligence, and security professionals, BrightPlanet said the phrase “Deep Web” is catchy but it does not explain what type of information is available to a person with a Web browser. A familiar example is querying a dynamic database, like an airline for its flight schedule. Other types of “Deep Web” content may require the user to register. Once logged into the system, users can query the content available to a registered user. A service like Bitpipe requires registration and a user name and password each time I want to pull a white paper from the Bitpipe system. BrightPlanet can handle both types of indexing tasks and many more. BrightPlanet’s technology is used by governmental agencies, businesses, and service firms to gather information pertinent to people, places, events, and other topics
In an exclusive interview, William Bushee, the chief executive officer at BrightPlanet, reveals the origins of the BrightPlanet approach. He told Cyber Wizards Speak:
I developed our initial harvest engine. At the time, little work was being done around harvesting. We filed for a number of US Patents applications for our unique systems and methods. We were awarded eight, primarily around the ability to conduct Deep Web harvesting, a term BrightPlanet coined.
The BrightPlanet system is available as a cloud service. Bushee noted:
We have migrated from an on-site license model to a SaaS [software as a service] model. However, the biggest change came after realizing we could not put our customers in charge of conducting their own harvests. We thought we could build the tools and train the customers, but it just didn’t work well at all. We now harvest content on our customers’ behalf for virtually all projects and it has made a huge difference in data quality. And, as I mentioned, we provide supporting engineering and technical services to our clients as required. Underneath, however, we are the same sharply focused, customer centric, technology operation.
The company also offers data as a service. Bushee explained:
We’ve seen many of our customers use our Data-as-a-Service model to increase revenue and customer share by adding new datasets to their current products and service offerings. These additional datasets develop new revenue streams for our customers and allow them to stay competitive maintaining existing customers and gaining new ones altogether. Our Data-as-a-Service offering saves time and money because our customers no longer have to invest development hours into maintaining data harvesting and collection projects internally. Instead, they can access our harvesting technology completely as a service.
The company has accelerated its growth through a partnering program. Bushee stated:
We have partnered with K2 Intelligence to offer a full end-to-end service to financial institutions, combining our harvest and enrichment services with additional analytic engines and K2’s existing team of analysts. Our product offering will be a service monitoring various Deep Web and Dark Web content enriched with other internal data to provide a complete early warning system for institutions.
BrightPlanet has emerged as an excellent resource to specialized content services. In addition to providing a client-defined collection of information, the firm can provide custom-tailored solutions to special content needs involving the Deep Web and specialized content services. The company has an excellent reputation among law enforcement, intelligence, and security professionals. The BrightPlanet technologies can generate a stream of real-time content to individuals, work groups, or other automated systems.
BrightPlanet has offices in Washington, DC, and can be contacted via the BrightPlanet Web site atwww.brightplanet.com.
The complete interview is available at the Cyber Wizards Speak web site at www.xenky.com/brightplanet.
Stephen E Arnold, April 7, 2015
Blog: www.arnoldit.com/wordpress Frozen site: www.arnoldit.com Current site: www.xenky.com
Interview with Dave Hawking Offers Insight into Bing, FunnelBack and Enterprise Search
December 9, 2014
The article titled To Bing and Beyond on IDM provides an interview with Dave Hawking, an award-winner in the field of information retrieval and currently a Partner Architect for Bing. In the somewhat lengthy interview, Hawking answers questions on his own history, his work at Bing, natural language search, Watson, and Enterprise Search, among other things. At one point he describes how he arrived in the field of information retrieval after studying computer science at the Australian National University, where he the first search engine he encountered was the library’s card catalogue. He says,
“I worked in a number of computer infrastructure support roles at ANU and by 1991 I was in charge of a couple of supercomputers…In order to do a good job of managing a large-scale parallel machine I thought I needed to write a parallel program so I built a kind of parallel grep… I wrote some papers about parallelising text retrieval on supercomputers but I pretty soon decided that text retrieval was more interesting.”
When asked about the challenges of Enterprise Search, Hawking went into detail about the complications that arise due to the “diversity of repositories” as well as issues with access controls. Hawking’s work in search technology can’t be overstated, from his contributions to the Text Retrieval Conferences, CSIRO, FunnelBack in addition to his academic achievements.
Chelsea Kerwin, December 09, 2014
Sponsored by ArnoldIT.com, developer of Augmentext
Elasticsearch: A Platform for Third Party Revenue
July 2, 2014
Making money from search and content processing is difficult. One company has made a breakthrough. You can learn how Mark Brandon, one of the founders of QBox, is using the darling of the open source search world to craft a robust findability business.
I interviewed Mr. Brandon, a graduate of the University of Texas as Austin, shortly after my return from a short trip to Europe. Compared with the state of European search businesses, Elasticsearch and QBox are on to what diamond miners call a “pipe.”
In the interview, which is part of the Search Wizards Speak series, Mr. Brandon said:
We offer solutions that work and deliver the benefits of open source technology in a cost-effective way. Customers are looking for search solutions that actually work.
Simple enough, but I have ample evidence that dozens and dozens of search and content processing vendors are unable to generate sufficient revenue to stay in business. Many well known firms would go belly up without continual infusions of cash from addled folks with little knowledge of search’s history and a severe case of spreadsheet fever.
Qbox’s approach pivots on Elasticsearch. Mr. Brandon said:
When our previous search product proved to be too cumbersome, we looked for an alternative to our initial system. We tested Elasticsearch and built a cluster of Elasticsearch servers. We could tell immediately that the Elasticsearch system was fast, stable, and customizable. But we love the technology because of its built-in distributed nature, and we felt like there was room for a hosted provider, just as Cloudant is for CouchDB, Mongolab and MongoHQ are for MongoDB, Redis Labs is for Redis, and so on. Qbox is a strong advocate for Elasticsearch because we can tailor the system to customer requirements, confident the system makes information more findable for users.
When I asked where Mr. Brandon’s vision for functional findablity came from, he told me about an experience he had at Oracle. Oracle owns numerous search systems, ranging from the late 1980s Artificial Linguistics’ system to somewhat newer systems like the late 1990s Endeca system, and the newer technologies from Triple Hop. Combine these with the SES technology and the hybrid InQuira formed from two faltering NLP systems, and Oracle has some hefty investments.
Here’s Mr. Brandon’s moment of insight:
During my first week at Oracle, I asked one of my colleagues if they could share with me the names of the middleware buyer contacts at my 50 or so named accounts. One colleague said, “certainly”, and moments later an Excel spreadsheet popped into my inbox. I was stunned. I asked him if he was aware that “Excel is a Microsoft technology and we are Oracle.” He said, “Yes, of course.” I responded, “Why don’t you just share it with me in the CRM System?” (the CRM was, of course, Siebel, an Oracle product). He chortled and said, “Nobody uses the CRM here.” My head exploded. I gathered my wits to reply back, “Let me get this straight. We make the CRM software and we sell it to others. Are you telling me we don’t use it in-house?” He shot back, “It’s slow and unusable, so nobody uses it.” As it turned out, with around 10 million corporate clients and about 50 million individual names, if I had to filter for “just middleware buyers”, “just at my accounts”, “in the Northeast”, I could literally go get a cup of coffee and come back before the query was finished. If I added a fourth facet, forget it. The CRM system would crash. If it is that bad at the one of the world’s biggest software companies, how bad is it throughout the enterprise?
You can read the full interview at http://bit.ly/1mADZ29. Information about QBox is at www.qbox.com.
Stephen E Arnold, July 2, 2014
-

- Subscribe to Beyond Search
Feature archive
News archive

-