

Hoping to End Enterprise Search Inaccuracies
May 1, 2015
Enterprise search is limited to how well users tag their content and the preloaded taxonomies. According Tech Target’s Search Content Management blog, text analytics might be the key to turning around poor enterprise search performance: “How Analytics Engines Could Finally-Relieve Enterprise Pain.” Text analytics turns out to only be part of the solution. Someone had the brilliant idea to use text analytics to classification issues in enterprise search, making search reactive to user input to proactive to search queries.
In general, analytics search engines work like this:
“The first is that analytics engines don’t create two buckets of content, where the goal is to identify documents that are deemed responsive. Instead, analytics engines identify documents that fall into each category and apply the respective metadata tags to the documents. Second, people don’t use these engines to search for content. The engines apply metadata to documents to allow search engines to find the correct information when people search for it. Text analytics provides the correct metadata to finally make search work within the enterprise.”
Supposedly, they are fixing the tagging issue by removing the biggest cause for error: humans. Microsoft caught onto how much this could generate profit, so they purchased Equivio in 2014 and integrated the FAST Search platform into SharePoint. Since Microsoft is doing it, every other tech company will copy and paste their actions in time. Enterprise search is gull of faults, but it has improved greatly. Big data trends have improved search quality, but tagging continues to be an issue. Text analytics search engines will probably be the newest big data field for development. Hint for developers: work on an analytics search product, launch it, and then it might be bought out.
Whitney Grace, May 1 2015
Sponsored by ArnoldIT.com, publisher of the CyberOSINT monograph
Recorded Future: The Threat Detection Leader
April 29, 2015
The Exclusive Interview with Jason Hines, Global Vice President at Recorded Future
In my analyses of Google technology, despite the search giant’s significant technical achievements, Google has a weakness. That “issue” is the company’s comparatively weak time capabilities. Identifying the specific time at which an event took place or is taking place is a very difficult computing problem. Time is essential to understanding the context of an event.
This point becomes clear in the answers to my questions in the Xenky Cyber Wizards Speak interview, conducted on April 25, 2015, with Jason Hines, one of the leaders in Recorded Future’s threat detection efforts. You can read the full interview with Hines on the Xenky.com Cyber Wizards Speak site at the Recorded Future Threat Intelligence Blog.
Recorded Future is a rapidly growing, highly influential start up spawned by a team of computer scientists responsible for the Spotfire content analytics system. The team set out in 2010 to use time as one of the lynch pins in a predictive analytics service. The idea was simple: Identify the time of actions, apply numerical analyses to events related by semantics or entities, and flag important developments likely to result from signals in the content stream. The idea was to use time as the foundation of a next generation analysis system, complete with visual representations of otherwise unfathomable data from the Web, including forums, content hosting sites like Pastebin, social media, and so on.
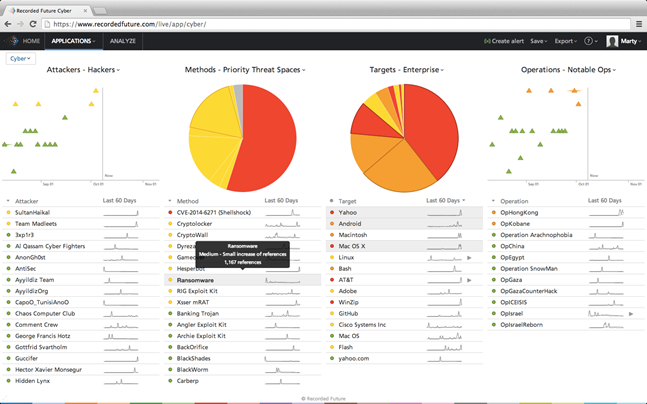
A Recorded Future data dashboard it easy for a law enforcement or intelligence professionals to identify important events and, with a mouse click, zoom to the specific data of importance to an investigation. (Used with the permission of Recorded Future, 2015.)
Five years ago, the tools for threat detection did not exist. Components like distributed content acquisition and visualization provided significant benefits to enterprise and consumer applications. Google, for example, built a multi-billion business using distributed processes for Web searching. Salesforce.com integrated visualization into its cloud services to allow its customers to “get insight faster.”
According to Jason Hines, one of the founders of Recorded Future and a former Google engineer, “When our team set out about five years ago, we took on the big challenge of indexing the Web in real time for analysis, and in doing so developed unique technology that allows users to unlock new analytic value from the Web.”
Recorded Future attracted attention almost immediately. In what was an industry first, Google and In-Q-Tel (the investment arm of the US government) invested in the Boston-based company. Threat intelligence is a field defined by Recorded Future. The ability to process massive real time content flows and then identify hot spots and items of interest to a matter allows an authorized user to identify threats and take appropriate action quickly. Fueled by commercial events like the security breach at Sony and cyber attacks on the White House, threat detection is now a core business concern.
The impact of Recorded Future’s innovations on threat detection was immediate. Traditional methods relied on human analysts. These methods worked but were and are slow and expensive. The use of Google-scale content processing combined with “smart mathematics” opened the door to a radically new approach to threat detection. Security, law enforcement, and intelligence professionals understood that sophisticated mathematical procedures combined with a real-time content processing capability would deliver a new and sophisticated approach to reducing risk, which is the central focus of threat detection.
In the exclusive interview with Xenky.com, the law enforcement and intelligence information service, Hines told me:
Recorded Future provides information security analysts with real-time threat intelligence to proactively defend their organization from cyber attacks. Our patented Web Intelligence Engine indexes and analyzes the open and Deep Web to provide you actionable insights and real-time alerts into emerging and direct threats. Four of the top five companies in the world rely on Recorded Future.
Despite the blue ribbon technology and support of organizations widely recognized as the most sophisticated in the technology sector, Recorded Future’s technology is a response to customer needs in the financial, defense, and security sectors. Hines said:
When it comes to security professionals we really enable them to become more proactive and intelligence-driven, improve threat response effectiveness, and help them inform the leadership and board on the organization’s threat environment. Recorded Future has beautiful interactive visualizations, and it’s something that we hear security administrators love to put in front of top management.
As the first mover in the threat intelligence sector, Recorded Future makes it possible for an authorized user to identify high risk situations. The company’s ability to help forecast and spotlight threats likely to signal a potential problem has obvious benefits. For security applications, Recorded Future identifies threats and provides data which allow adaptive perimeter systems like intelligent firewalls to proactively respond to threats from hackers and cyber criminals. For law enforcement, Recorded Future can flag trends so that investigators can better allocate their resources when dealing with a specific surveillance task.
Hines told me that financial and other consumer centric firms can tap Recorded Future’s threat intelligence solutions. He said:
We are increasingly looking outside our enterprise and attempt to better anticipate emerging threats. With tools like Recorded Future we can assess huge swaths of behavior at a high level across the network and surface things that are very pertinent to your interests or business activities across the globe. Cyber security is about proactively knowing potential threats, and much of that is previewed on IRC channels, social media postings, and so on.
In my new monograph CyberOSINT: Next Generation Information Access, Recorded Future emerged as the leader in threat intelligence among the 22 companies offering NGIA services. To learn more about Recorded Future, navigate to the firm’s Web site at www.recordedfuture.com.
Stephen E Arnold, April 29, 2015
Digital Reasoning Goes Cognitive
April 16, 2015
A new coat of paint is capturing some tire kickers’ attention.
IBM’s Watson is one of the dray horses pulling the cart containing old school indexing functions toward the airplane hanger.
There are assorted experts praising the digital equivalent of a West Coast Custom’s auto redo. A recent example is Digital Reasoning’s embrace of the concept of cognitive computing.
Digital Reasoning is about 15 years old and has provided utility services to the US government and some commercial clients. “Digital Reasoning Goes cognitive: CEO Tim Estes on Text, Knowledge, and Technology” explains the new marketing angle. The write up reported:
Cognitive is a next computing paradigm, responding to demand for always-on, hyper-aware data technologies that scale from device form to the enterprise. Cognitive computing is an approach rather than a specific capability. Cognitive mimics human perception, synthesis, and reasoning capabilities by applying human-like machine-learning methods to discern, assess, and exploit patterns in everyday data. It’s a natural for automating text, speech, and image processing and dynamic human-machine interactions.
If you want to keep track of the new positioning text processing companies are exploring, check out the write up. Will cognitive computing become the next big thing? For vendors struggling to meet stakeholder expectations, cognitive computing sounds more zippy that customer support services or even the hyperventilating sentiment analysis positioning.

Lego blocks are pieces that must be assembled.
Indexing never looked so good. Now the challenge is to take the new positioning and package it in a commercial product which can generate sustainable, organic revenues. Enterprise search positioning has not been able to achieve this goal with consistency. The processes and procedures for cognitive computing remind me of Legos. One can assemble the blocks in many ways. The challenge will be to put the pieces together so that a hardened, saleable product can be sold or licensed.

Is there a market for Lego airplane assembled by hand? Vendors of components may have to create “kits” in order to deliver a solution a customer can get his or her hands around.
An unfamiliar function with a buzzword can be easy to sell to those organizations with money and curiosity. Jargon is often not enough to keep stakeholders and in the case of IBM shareholders smiling. A single or a handful of Lego blocks may not satisfy those who want to assemble a solution that is more than a distraction. Is cognitive computing a supersonic biplane or a historical anomaly?
This is worth watching because many companies are thrashing for a hook which will lead to significant revenues, profits, and sustainable growth, not just a fresh paint job.
Stephen E Arnold, April 16, 2015
Medical Search: A Long Road to Travel
April 13, 2015
Do you want a way to search medical information without false drops, the need to learn specialized vocabularies, and sidestep Boolean? Apparently the purveyors of medical search systems have left a user scratch without an antihistamine within reach.
Navigate to Slideshare (yep, LinkedIn) and flip through “Current Advances to Bridge the Usability Expressivity Gap in biomedical Semantic Search.” Before reading the 51 slide deck, you may want to refresh yourself with Quertle, PubMed, MedNar, or one of the other splendiferous medical information resources for researchers.
The slide deck identifies the problems with the existing search approaches. I can relate to these points. For example, those who tout question answering systems ignore the difficulty of passing a question from medicine to a domain consisting of math content. With math the plumbing in many advanced medical processes, the weakness is a bit of a problem and has been for decades.
The “fix” is semantic search. Well, that’s the theory. I interpreted the slide deck as communicating how a medical search system called ReVeaLD would crack this somewhat difficult nut. As an aside: I don’t like the wonky spelling that some researchers and marketers are foisting on the unsuspecting.
I admit that I am skeptical about many NGIA or next generation information access systems. One reason medical research works as well as it does is its body of generally standardized controlled term words. Learn MeSH and you have a fighting chance of figuring out if the drug the doctor prescribed is going to kill off your liver as it remediates your indigestion. Controlled vocabularies in scientific, technology, engineering, and medical domains address the annoying ambiguity problems encounter when one mixes colloquial words with quasi consultant speak. A technical buzzword is part of a technical education. It works, maybe not too well, but it works better than some of the wild and crazy systems which I have explored over the years.
You will have to dig through old jargon and new jargon such as entity reconciliation. In the law enforcement and intelligence fields, an entity from one language has to be “reconciled” with versions of the “entity” in other languages and from other domains. The technology is easier to market than make work. The ReVeaLD system is making progress as I understand the information in the slide deck.
Like other advanced information access systems, ReVeaLD has a fair number of moving parts. Here’s the diagram from Slide 27 in the deck:

There is also a video available at this link. The video explains that Granatum Project uses a constrained domain specific language. So much for cross domain queries, gentle reader. What is interesting to me is the similarity between the ReVeaLD system and some of the cyber OSINT next generation information access systems profiled in my new monograph. There is a visual query builder, a browser for structured data, visualization, and a number of other bells and whistles.
Several observations:
- Finding relevant technical information requires effort. NGIA systems also require the user to exert effort. Finding the specific information required to solve a time critical problem remains a hurdle for broader deployment of some systems and methods.
- The computational load for sophisticated content processing is significant. The ReVeaLD system is likely to such up its share of machine resources.
- Maintaining a system with many moving parts when deployed outside of a research demonstration presents another series of technical challenges.
I am encouraged, but I want to make certain that my one or two readers understand this point: Demos and marketing are much easier to roll out than a hardened, commercial system. Just as the EC’s Promise program, ReVeaLD may have to communicate its achievements to the outside world. A long road must be followed before this particular NGIA system becomes available in Harrod’s Creek, Kentucky.
Stephen E Arnold, April 13, 2015
Spelling Suggestions via the Bisect Module
April 13, 2015
I know that those who want to implement their own search and retrieval systems learn that some features are tricky to implement. I read “Typos in Search Queries at Khan Academy.”
The author states:
The idea is simple. Store a hash of each word in a sorted array and then do binary search on that array. The hashes are small and can be tightly packed in less than 2 MB. Binary search is fast and allows the spell checking algorithm to service any query.
What is not included in the write up is detail about the time required and the frustration experienced to implement what some senior managers assume is trivial. Yep, search is not too tough when the alleged “expert” has never implemented a system.
With education struggling to teach the three Rs, the need for software that caulks the leaks in users’ ability to spell is a must have.
Stephen E Arnold, April 13, 2015
The Challenge of Synonyms
April 12, 2015
I am okay with automated text processing systems. The challenge is for software to keep pace with the words and phrases that questionable or bad actors use to communication. The marketing baloney cranked out by vendors suggests that synonyms are not a problem. I don’t agree. I think that words used to reference a subject can fool smart software and some humans as well. For an example of the challenge, navigate to “The Euphemisms People Use to Pay Their Drug Dealer in Public on Venmo.” The write up presents some of the synonyms for controlled substances; for example:
- Kale salad thanks
- Columbia in the 1980s
- Road trip groceries
- Sanity 2.0
- 10 lbs of sugar
The synonym I found interesting was an emoji, which most search and content processing systems cannot “understand.”

and

Attensity asserts that it can “understand” emojis. Sure, if there is a look up list hard wired to a meaning. What happens if the actor changes the emoji? Like other text processing systems, the smart software may become less adept than the marketers state.
But why rain on the hype parade and remind you that search is difficult? Moving on.
Stephen E Arnold, April 12, 2015
Twitter Plays Hard Ball or DataSift Knows the End Is in Sight
April 11, 2015
I read “Twitter Ends its Partnership with DataSift – Firehose Access Expires on August 13, 2015.” DataSift supports a number of competitive and other intelligence services with its authorized Twitter stream. The write up says:
DataSift’s customers will be able to access Twitter’s firehose of data as normal until August 13th, 2015. After that date all the customers will need to transition to other providers to receive Twitter data. This is an extremely disappointing result to us and the ecosystem of companies we have helped to build solutions around Twitter data.
I found this interesting. Plan now or lose that authorized firehose. Perhaps Twitter wants more money? On the other hand, maybe DataSift realizes that for some intelligence tasks, Facebook is where the money is. Twitter is a noise machine. Facebook, despite its flaws, is anchored in humans, but the noise is increasing. Some content processes become more tricky with each business twist and turn.
Stephen E Arnold, April 11, 2015
Search Is Simple: Factoid Question Answering Made Easy
April 10, 2015
I know that everyone is an expert when it comes to search. There are the Peter Principle managers at Fortune 100 companies who know so much about information retrieval. There are the former English majors who pontificate about next generation systems. There are marketers who have moved from Best Buy to the sylvan manses of faceted search and clustering.
But when one gets into the nitty gritty of figuring out how to identify information that answers a user’s question, the sunny days darkens, just like the shadows in a furrowed brow.
Navigate to “A Neural Network for Factoid Question Answering Over Paragraphs.” Download the technical paper at this link. What we have an interesting discussion of a method for identifying facts that appear in separate paragraphs. The approach makes use of a number of procedures, including a helpful vector space visualization to make evident the outcome of the procedures.
Now does the method work?
There is scant information about throughput, speed of processing, or what has to be done to handle multi-lingual content, blog type information, and short strings like content in WhatsApp.
One thing is known: Answering user questions is not yet akin to nuking a burrito in a microwave.
Stephen E Arnold, April 10, 2015
Predicting Plot Holes Isn’t So Easy
April 10, 2015
According to The Paris Review’s blog post “Man In Hole II: Man In Deeper Hole” Mathew Jockers created an analysis tool to predict archetypal book plots:
A rough primer: Jockers uses a tool called “sentiment analysis” to gauge “the relationship between sentiment and plot shape in fiction”; algorithms assign every word in a novel a positive or negative emotional value, and in compiling these values he’s able to graph the shifts in a story’s narrative. A lot of negative words mean something bad is happening, a lot of positive words mean something good is happening. Ultimately, he derived six archetypal plot shapes.”
Academics, however, found some problems with Jockers’s tool, such as is it possible to assign all words an emotional variance and can all plots really take basic forms? The problem is that words are as nuanced as human emotion, perspectives change in an instant, and sentiments are subjective. How would the tool rate sarcasm?
All stories have been broken down into seven basic plots, so why can it not be possible to do the same for book plots? Jockers already identified six basic book plots and there are some who are curiously optimistic about his analysis tool. It does beg the question if will staunch author’s creativity or if it will make English professors derive even more subjective meaning from Ulysses?
Whitney Grace, April 10, 2015
Stephen E Arnold, Publisher of CyberOSINT at www.xenky.com
Attensity Adds Semantic Markup
April 3, 2015
You have been waiting for more markup. I know I have, and that is why I read “Attensity Semantic Annotation: NLP-Analyse für Unternehmensapplikationen.”
So your wait and mine—over.
Attensity, a leading in figuring out what human discourse means, has rolled out a software development kit so you can do a better job with customer engagement and business intelligence. Attensity offers Dynamic Data Discovery. Unlike traditional analysis tools, Attensity does not focus on keywords. You know, what humans actually use to communicate.
Attensity uses natural language processing in order to identify concepts and issues in plain language. I must admit that I have heard this claim from a number of vendors, including long forgotten systems like DR LINK, among others.
The idea is that the SDK makes it easier to filter data to evaluate textual information and identify issues. Furthermore the SDK performs fast content fusion. The result is, as other vendors have asserted, insight. There was a vendor called Inxight which asserted quite similar functions in 1997. At one time, Attensity had a senior manager from Inxight, but I assume the attribution of functions is one of Attensity’s innovations. (Forgive me for mentioning vendors with which some 20 somethings know quite well.)
If you are dependent upon Java, Attensity is an easy fit. I assume that if you are one of the 150 million plus Microsoft SharePoint outfits, Attensity integration may require a small amount of integration work.
According the Attensity, the benefits of Attensity’s markup approach is that the installation is on site and therefore secure. I am not sure about this because security is person dependent, so cloud or on site, security remains an “issue” different from the one’s Attensity’s system identifies.
Attensity, like Oracle, provides a knowledge base for specific industries. Oracle made term lists available for a number of years. Maybe since its acquisition of Artificial Linguistics in the mid 1990s?
Attensity supports five languages. For these five languages, Attensity can determine the “tone” of the words used in a document. Presumably a company like Bitext can provide additional language support if Attensity does not have these ready to install.
Vendors continue to recycle jargon and buzzwords to describe certain core functions available from many different vendors. If your metatagging outfit is not delivering, you may want to check out Attensity’s solution.
Stephen E Arnold, April 3, 2015
-

- Subscribe to Beyond Search
Feature archive
News archive

-