

More Content Processing Brand Confusion
September 7, 2012
On a call with a so-so investment outfit once spawned from JP Morgan’s empire, the whiz kids on the call with me asked me to name some interesting companies I was monitoring. I spit out two or three. One name created a hiatus. The spiffy young MBA asked me, “Are you tracking a pump company?”
I realized that when one names search and content processing firms, the name of the company and its brand are important. I was referring to an outfit called “Centrifuge”, a firm along with dozens if not hundreds of others in the pursuit of the big data rainbow. The company has an interesting product, and you can read about the firm at www.centrifugesystems.com.
Now the confusion. Google thinks Centrifuge business intelligence is the same as centrifuge coolant sludge systems. Interesting.
 |
 |
There is a pump and valve outfit called Centrifuge at www.centrisys.us. This outfit, it turns out, has a heck of a marketing program. Utilizing YouTube, a search for “centrifuge systems” returns a raft of information timber about viscosity, manganese phosphate, and lead dust slurry.
I have commented on the “findability” problem in the search, analytics, and content processing sector in my various writings and in my few and far between public speaking engagements. My 68 years weigh heavily on me when a 20-something pitches a talk in some place far from Harrod’s Creek, Kentucky.
The semantic difference between analytics and lead dust slurry is obvious to me. To the indexing methods in use at Baidu, Bing, Exalead, Google, Jike, and Yandex—not so much.
How big of a problem is this? You can see that Brainware, Sinequa, Thunderstone, and dozens of other content-centric outfits are conflated with questionable videos, electronic games, and Latin phrases. When looking for these companies and their brands via mobile devices, the findability challenge gets harder, not easier. The constant stream of traditional news releases, isolated blog posts, white papers which are much loved by graduate students in India, and Web collateral miss their intended audiences. I prefer “miss” to the blunt reality of “unread content.”
I am going to start a file in which to track brand confusion and company name erosion. Search, analytics, and content processing vendors should know that preserving the semantic “magnetism” of a word or phrase is important. Surprising it is to me that I can run a query and get links to visual network analytics along side high performance centrifuges. Some watching robots pay close attention to the “centrifuge” concept I assume.
Brand management is important.
Stephen E Arnold, September 7, 2012
Sponsored by Augmentext
Can Brainware and ISYS Search Get Lexmark Back on Track
September 5, 2012
I was surprised to learn that Lexmark in Lexington, Kentucky, was getting into the search and retrieval, content processing, and indexing business. I had a meeting at a Lexmark facility a couple of years ago, and I was struck by the absence of activity in what was and probably still is a very large building. The meeting was held in the “library” for one of the firm’s units. Quiet. Search was a challenge. I left the meeting wondering how the employees found repair data, training manuals, proposals, and technical reference information.
When I learned that in a short span of time in early 2012, Lexmark purchased Brainware. You may know that Brainware was originally a search vendor. The technology which worked the firm’s retrieval magic was based on trigrams or three letter sequences. The query terms were parsed into three letter groups. Documents with the query’s three letter groups were identified and rank order by trigram match. There are numerous technical details associated with the patented technology. The point is that Brainware got into back office processing and took off. The search and retrieval business supported the paper-to-digital-to-index business. Brainware landed some juicy accounts. I assumed that Oracle would acquire the company, but I was wide of the mark. Heck, I wasn’t even in the same county. You can get some details about the deal in the Brainware news release, “Lexmark Acquires Brainware.” To beef up Brainware’s back office capabilities, Lexmark also bought Nolij.
A few days later, Lexmark purchased the ISYS Search Software company. Like IBM’s magical repositioning of Vivisimo, Lexmark described ISYS as being more than search. Okay. According to the news release about the deal, ISYS’s technology dates from 1988. That works out to almost a quarter century. The ISYS technology will complement Lexmark’s Perceptive Software business. The idea is Perceptive will be better able to compete in process and content management solutions.
With the closing of the ink jet business, Lexmark is going to have to find a way to generate significant revenues from its search enabled applications and its search based businesses.
The question becomes, “Will Lexmark be able to generate significant revenue from search?”
In the annual report for 2005, Lexmark said:
Lexmark makes it easier for businesses and consumers to move information between the digital and paper worlds. Since its inception in 1991, Lexmark has become a leading developer, manufacturer and supplier of printing and imaging solutions for offices and homes. Lexmark’s products include laser printers, inkjet printers, multifunction devices, associated supplies, services and solutions. Lexmark develops and owns most of the technology for its laser and inkjet products and associated supplies, and that differentiates the company from many of its major competitors, including Hewlett-Packard, which purchases its laser engines and cartridges from third-party suppliers. Lexmark also sells dot matrix printers for printing single and multi-part forms by business users and develops, manufactures and markets a broad line of other office imaging products. The company operates in the office products industry. The company is primarily managed along business and consumer market segments.
With this shift, Lexmark is going in a different direction; that is, buying technology instead of developing it. The announcement that Lexmark was terminating more than 1,000 employees with about half located less than an hour from my goose pond in Harrod’s Creek, Kentucky, was bad news in a state with lots of bad
How will that work out?
My view is that Lexmark is likely to experience some unwelcome surprises. As you may recall, Hewlett Packard was shocked at Autonomy’s performance once the company was on board. With the departure of a number of key Autonomy executives, including Mike Lynch, Hewlett Packard has become quiet about Autonomy. I assume that the massive write off of the EDS business is occupying the senior managers. Lexmark may be headed for some cost surprises; for example:
- Brainware incurs some labor costs with its back office sales. Oracle and other companies want to get into this “old fashioned” business, so the marketing costs are likely to go up. How much of a spike will be determined by the appetite of hospitals and other paper centric operations in a lousy economy and the uncontrollable actions of companies like Oracle.
- ISYS costs are likely to be a shock as well. ISYS is similar to Fast Search & Transfer, just older. As a result, the cost to keep the system current are likely to grow over time. The fancy new features like text mining are easy to talk about. To build out systems which can compete with services from Digital Reasoning and Quid is another level of investment entirely.
- Support costs in the search enable applications sector are tough to control. A major company may not tolerate a filtering call handled in India and then a wait for an engineer to get involved. Perhaps Lexmark will use ISYS for customer support?
But what could Lexmark do?
Printing is environmentally unacceptable to many people. In addition, a PDF file can be emailed more quickly and cheaply than sending a document via FedEx. With iPads in the hands of executives, a digital version of a document is good enough.
Like HP, Lexmark is going to have to work some marketing, cost control, and management miracles to get back on the growth path with generous margins. Is it too late for Lexmark to return to revenue glory in the Bluegrass State? Well, I am not willing to go out a limb. Let’s just watch.
Stephen E Arnold, September 5, 2012
Sponsored by Augmentext
Ohloh Code Enhances Koders.com Search Technology
September 4, 2012
Big news from Black Duck brought to you by the goose pond: Ohloh has enhanced Koders.com.
Ohloh Code, a publicly available, free code search site, has made it possible for users to immediately browse the code of projects, search for particular methods, and see Ohloh commit and LOC information all in the same place. This is an improvement upon Koders.com, which lacked an automated way to let users add and update projects or view sources and parent projects. An announcement post made on Ohloh, “Ohloh + Code = Ohloh Code,” informs us of the changes:
“The Ohloh Code search database is populated and updated from a new, automated integration with Ohloh’s project list. We’ve rebuilt the code search engine (also available for private code search: Code Sight) as an upgrade from Koders.com. We’ve migrated the entire code base from .NET to Java (our team’s language of choice).[…]
To sum up…
Ohloh (ohloh.net) + Ohloh Code (code.ohloh.net) = our vision to create the most comprehensive and free resource for developers to find and explore open source projects and code.”
We think code searchers will be pleased with Ohloh Code’s results and the enhanced technology. Kudos to the team for integrating more languages, filtering and faceting search results, including preservation of the underscore in search results, and enhancing scalability for indexing and searching. Head on over to Ohloh to learn about more of the changes.
Andrea Hayden, September 04, 2012
Sponsored by ArnoldIT.com, developer of Augmentext
Google Updates the Portal from 1996: Info on Multiple Devices
August 30, 2012
The portal never really died. AOL and Yahoo have kept the 1990s “next big thing” despite the financial penalties the approach has imposed on stakeholders. There are other portals which are newer versions of the device which slices, dices, and chops. Examples I have looked at include:
- NewsIsFree, which delivers headlines, alerts, and allows me to find “sources”
- WebMD, which is a consumer “treat thyself” and aggregation information portal
- AutoTrader, which provides a vehicle research, loan, and purchasing portal.
Google when it rolled out 13 years ago took advantage of search systems’ desire to go “beyond search.” The reasons were easy to identify. Over the years, I have enumerated them many times. Google’s surge was due to then-search giants looking for a way to generate enough revenue to pay for the cost of indexing content. Now there are some crazy ideas floating around “real” consultant cubicles that search is cheap and easy.

Next Generation Portals: Gate to Revenue Hell?
Fear not, lads and lasses.
Search is brutally expensive and—guess what?—the costs keep on rising. The principal reasons are that systems need constant mothering and money. No, let’s not forget the costs which MBAs often trivialize. These include people who can make the system work, run faster, remain online, and keep pace with technology. Telecommunications, power, hardware, and a number of other “trivial” items gobble money like a 12 year old soccer player after practice chowing down on junk food.

Next Generation Portals: Gate to Revenue Heaven?
Portals promised to be “sticky”, work like magnets and pull more users, and provide a platform for advertising. Portals were supposed to make money when search generated modest amounts of money. First Overture, then Yahoo, and finally Google realized that the pursuit of objectivity was detrimental to selling traffic. Thus, online pay-to-play programs took off. The portals with a lead like Yahoo fumbled the ball. The more clever Googlers grabbed the melon and kept going back to the farmer’s garden for more. Google had, it appeared, figured out how to remain a search system and make lots of money.
No more.
Do we now witness the portalization of Google? Is the new twist is that the Google portal will require the user to have multiple devices? Will each device connects to Google to show more portal advertising goodness?
There is a popular impression among some MBAs on Wall Street and “real” consultants that Google is riding the same old money rocket in did in 2004 to 2006. My view is different.
Search: A Persistent Disconnect between Reality and Innovation
August 17, 2012
Two years ago I wrote The New Landscape of Search. Originally published by Pandia in Norway, the book is now available without charge when you sign up for our new “no holds barred” search newsletter Honk!. In the discussion of Microsoft’s acquisition of Fast Search & Transfer SA in 2008, I cite documents which describe the version of Fast Search which the company hoped to release in 2009 or 2010. After the deal closed, the new version of Fast seemed to drop from view. What became available was “old” Fast.
I read the InfoWorld story “Bring Better Search to SharePoint.” Set aside the PR-iness of the write up. The main point is that SharePoint has a lousy search system. Think of the $1.2 billion Microsoft paid for what seems to be, according to the write up, a mongrel dog. My analysis of Fast Search focused on its age. The code dates from the late 1990s and its use of proprietary, third party, and open source components. Complexity and the 32 bit architecture were in need of attention beyond refactoring.
The InfoWorld passage which caught my attention was:
Longitude Search’s AptivRank technology monitors users as they search, then promotes or demotes content’s relevance rankings based on the actions the user takes with that content. In a nutshell, it takes Microsoft’s search-ranking algorithm and makes it more intelligent…
The solution to SharePoint’s woes amounts to tweaking. In my experience, there are many vendors offering similar functionality and almost identical claims regarding fixing up SharePoint. You can chase down more at www.arnoldit.com/overflight.
The efforts are focused on a product with a large market footprint. In today’s dicey economic casino, it makes sense to trumpet solutions to long standing information retrieval challenges in a product like SharePoint. Heck, if I had to pick a market to pump up my revenue, SharePoint is a better bet than some others.
Contrast the InfoWorld’s “overcome SharePoint weaknesses” with the search assertions in “Search Technology That Can Gauge Opinion and Predict the Future.” We are jumping from the reality of a Microsoft product which has an allegedly flawed search system into the exciting world of what everyone really, really wants—serious magic. Fixing SharePoint is pretty much hobby store magic. Predicting the future: That is big time, hide the Statue of Liberty magic.
Here’s the passage which caught my attention:
A team of EU-funded researchers have developed a new kind of internet search that takes into account factors such as opinion, bias, context, time and location. The new technology, which could soon be in use commercially, can display trends in public opinion about a topic, company or person over time — and it can even be used to predict the future…Future Predictor application is able to make searches based on questions such as ‘What will oil prices be in 2050?’ or ‘How much will global temperatures rise over the next 100 years?’ and find relevant information and forecasts from today’s web. For example, a search for the year 2034 turns up ‘space travel’ as the most relevant topic indexed in today’s news.
Yep, rich indexing, facets, and understanding text are in use.
What these two examples make clear, in my opinion, is that:
Search is broken. If an established product delivers inadequate findability, why hasn’t Microsoft just solved the problem? If off the shelf solutions are available from numerous vendors, why hasn’t Microsoft bought the ones which fix up SharePoint and call it a day? The answer is that none of the existing solutions deliver what users want. Sure, search gets a little better, but the SharePoint search problem has been around for a decade and if search were such an easy problem to solve, Microsoft has the money to do the job. Still a problem? Well, that’s a clue that search is a tough nut to crack in my book. Marketers don’t have to make a system meet user needs. Columnists don’t even have to use the systems about which they write. Pity the users.
Writing about whiz bang new systems funded by government agencies is more fun than figuring out how to get these systems to work in the real world. If SharePoint search does not work, what effort and investment will be required to predict the future via a search query? I am not holding my breath, but the pundits can zoom forward.
The search and retrieval sector is in turmoil, and it will stay that way. The big news in search is that free and open source options are available which work as well as Autonomy- and Endeca-like systems. The proprietary and science fiction solutions illustrate on one hand the problems basic search has in meeting user needs and, on the other hand, the lengths to which researchers are trying to go to convince their funding sources and regular people that search is going to get better real soon now.
Net net: Search is a problem and it is going to stay that way. Quick fixes, big data, and predictive whatevers are not going to perform serious magic quickly, economically, or reliably without significant investment. InfoWorld seems to see chipper descriptions and assertions as evidence of better search. The Science Daily write up mingles sci-fi excitement with a government funded program to point the way to the future.
Sorry. Search is tough and will remain a chunk of elk hide until the next round of magic is spooned by public relations professionals into the coffee mugs of the mavens and real journalists.
Stephen E Arnold, August 17, 2012
Sponsored by Augmentext
Perfecting Web Site Semantics
August 6, 2012
Web site search is most often frustrating, and at its worst, a detriment to customers and commerce. Fabasoft Mindbreeze, a company heralded for its advances in enterprise search, is bringing its semantic specialization to the world of Web site search with Fabasoft Mindbreeze InSite. Daniel Fallmann, Fabasoft Mindbreeze CEO, highlights the features of the new product in his blog entry, “4 Points for Perfect Website Semantics.”
Fallmann lays out the problem:
The problem: Standard search machines, in particular the one provided by CMS, are unproductive and don’t consider the website’s sophisticated structure. The best example: enter the search term ‘product’ and the search delivers no results, even though product is its own category on the site. Even if the search produces a result for another term, there’s nothing more than a ‘relatively un-motivating list of links,’ not really much help to a website visitor.
Using semantics in the search means that the Web site is being understood, not just keyword searched. Automatic indexing preserves the existing site structure, while providing hassle-free search for the customer. In addition, InSite benefits the Web site developer, in that he/she can see how users are navigating the site and which elements are most often searched.
The attractive “behind-the-scenes” functioning of Fabasoft Mindbreeze InSite means that customers benefit from the intuitive, semantic search without the distraction of a clunky search layer. Satisfy your customers and your developers by exploring InSite today.
Emily Rae Aldridge, August 6, 2012
Sponsored by ArnoldIT.com, developer of Augmentext.
Short Honk: High Value Podcast about Solr
August 4, 2012
If you are interested in Lucene/Solr and have a long commute, you will want to check out Episode 187 of the IEEE’s Software Engineering Podcast. You can find the podcast on iTunes. Grant Ingersoll, one of Lucid Imagination’s experts in open source search and a committer on the Apache Lucene/Solr project, reviews the origins of Lucene, explains the features of Solr, and covers a range of important, hard to get search information. According to IEEE, the podcast offers a:
dive into the architecture of the Solr search engine. The architecture portion of the interview covers the Lucene full-text index, including the text ingestion process, how indexes are built, and how the search engine ranks search results. Grant also explains some of the key differences between a search engine and a relational database, and why both have a place within modern application architectures.
One of the highlights of the podcast is Mr. Ingersoll’s explanation of vector space indexing. Even a high school brush with trigonometry is sufficient to make this important subject fascinating. Highly recommended.
Stephen E Arnold, August 4, 2012
Sponsored by Augmentext
Research and Development Innovation: A New Study from a Search Vendor
August 3, 2012
I received message from LinkedIn about a news item called “What Are the Keys to Innovation in R&D?” I followed the links and learned that the “study” was sponsored by Coveo, a search vendor based in Canada. You can access similar information about the study by navigating to the blog post “New Study: The Keys to Innovation for R&D Organizations – Their Own, Unused Knowledge.” (You will also want to reference the news release about the study as well. It is on the Coveo News and Events page.

Engineers need access to the drawings and those data behind the component or subsystem manufactured by their employer. Text based search systems cannot handle this type of specialized data without some additional work or the use of third party systems. A happy quack to PRLog: http://www.prlog.org/10416296-mechanical-design-drawing-services.jpg
{kind=link}
The main of the study, as I interpret it, is marketing Coveo as a tool to facilitate knowledge management. Even though I write a monthly column for the print and online publication KMWorld, I do not have a definition of knowledge management with which I am comfortable. The years I spent at Booz, Allen & Hamilton taught me that management is darned tough to define. Management as a practice is even more difficult to do well. Managing research and development is one of the more difficult tasks a CEO must handle. Not even Google has an answer. Google is now buying companies to have a future, not inventing its future with existing staff.
The unhappy state of many search and content processing companies is evidence that those with technological expertise may not be able to generate consistent and growing revenues. Innovation in search has become a matter of jazzing up interfaces and turning up the marketing volume. The $10 billion paid for Autonomy, the top dog in the search and content processing space, triggered grousing by Hewlett Packard’s top executives. Disappointing revenues may have contributed to the departure of some high profile Autonomy Corporation executives. Not even the HP way can make traditional search technology pay off as expected, hoped, and needed. Search vendors are having a tough time growing fast enough to stay ahead of spiking technical and support costs.
When I studied for a year at the Jesuit-run Duquesne University, I encountered Dr. Frances J. Chivers. The venerable PhD was an expert in epistemology with a deep appreciation for the lively St. Augustine and the comedian Johann Gottlieb Fichte. I was indexing medieval Latin sermons. I had to take “required” courses in “knowledge.” In the mid 1960s, there were not too many computer science departments in the text indexing game, so I assume that Duquesne’s administrators believed that sticking me in the epistemology track would improve the performance of my mainframe indexing software. Well, let me tell you: Knowledge is a tough nut to crack.
Now you can appreciate my consternation when the two words are juxtaposed and used by search vendors to sell indexing. Dr. Chivers did not have a clue about what I was doing and why. I tried to avoid getting involved in discussions that referenced existentialism, hermeneutics, and related subjects. Hey, I liked the indexing thing and the grant money. To this day, I avoid talking about knowledge.
Selected Findings
Back to the study. Coveo reports:
We recently polled R&D teams about how they use and share innovation across offices and departments, and the challenges they face in doing so. Because R&D is a primary creator and consumer of knowledge, these organizations should be a model for how to utilize and share it. However, as we’ve seen in the demand for our intelligent indexing technology, and as revealed in the study, we found that R&D teams are more apt to duplicate work, lose knowledge and operate in soloed, “tribal” environments where information isn’t shared and experts can’t be found. This creates a huge opportunity for those who get it right—to out-innovate and out-perform their competition.
The question I raised to myself was, “How were the responses from Twitter verified as coming from qualified respondents?” And, “How many engineers with professional licenses versus individuals who like Yahoo’s former president just arbitrarily awarded themselves a particular certification were in the study?” Also, “What statistical tests were applied to the results to validate the the data met textbook-recommended margins of error?”
I may have the answers to these questions in the source documents. I have written about “number shaping” at some of the firms with which I have worked, and I have addressed the issue more directly in my opt in, personal news service Honk. (Honk, a free weekly newsletter, is a no-holds-barred look at one hot topic in search and content processing. Those with a propensity to high blood pressure should not subscribe.)
Making Data Easy with Training Wheels? The Nielsen Dust Up
July 31, 2012
In the Honk newsletter, I have been plugging away at some of the flights of fancy that surround big data, next generation analytics, and all things predictive. I am nervous about “training wheels” on complex mathematical processes. Like the fill-in-the-blanks functions in Excel, a person without a foundation in math can fiddle around until the software spits out a number which “looks good.” In one of my jobs, my boss was a master at “the flow.” The idea was that numbers can be shaped to support a particular point. I recall his comment to me in 1974, “Most of our clients are not smart enough to work through the math. We have to generate outputs which flow.” The idea is one that troubled me. I moved on to greener and less slippery pastures and I kept that notion of “flow” squarely in mind. Numbers should not cause the person looking at a chart or a table to say, “Wow, that number looks weird.” Hence, flow allows the reasoning process to be guided.
I just read a story which I hope is not accurate. I want to document my coming across the item, however. I think it will be an interesting touchstone and search and content processing companies race to be come players in big data and analytics. The story appeared in the Hollywood Reporter, a publication about which I know little. The headline caught my attention because it resonates with advertising and advertising automatically evokes the Google logo for me. “Nielsen Sued for Billions over Allegedly Manipulated TV Ratings” carries a hard hitting subtitle too: “In a huge new lawsuit, the business of TV ratings is fingered for rampant corruption by India’s largest TV news network.” I know even less about India than the Hollywood Reporter.
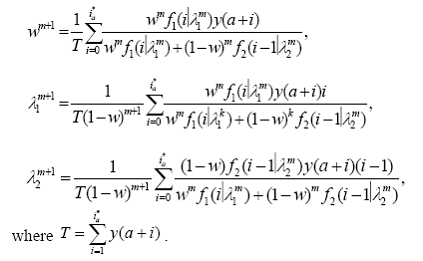
Fancy math underlies the products and services of many analytics firms which offer products and services to licensees that make interacting with data a matter of pointing and clicking. A happy quack for the equation to http://goo.gl/lBlXV
Here’s the passage I noted:
In a 194-page lawsuit filed in New York court late last week, NDTV accuses Nielsen of violating the Foreign Corrupt Practices Act by manipulating viewership data in favor of channels that are willing to provide bribes to its officials. According to NDTV, rampant manipulation of viewership data has been going on for eight years, and when presented with evidence earlier this year, top executives at Nielsen pledged to make changes. But the Indian news giant says these promises have been false ones.
Like most litigation, the story will unfold slowly and perhaps not at all. The i2 Group Palantir litigation is a relatively recent example. Based on my experience with the boss who wanted numbers to flow, I can see how the possibility of tweaking could be useful to some companies. However, with the dismal state of math skills, how can I now of the problem was a result of human intent, human error, or a training wheels type system driven over rocky terrain. I can’t and I bet that most people thinking about this situation cannot either.
What is interesting to me, however, are these notions:
- How many other fancy math systems are open to similar allegations from their licensees?
- Will this type of legal action cause some of the vendors pitching fancy math and predictive systems to modify their marketing materials to include more caveats and real world anchors instead of bold assertions?
- How will the legal system deal with fancy math litigation? I don’t know many attorneys. The handful with which I have some experience have been quick to point out that math, engineering, and science were not their strengths. Logic and reasoning were their strong suits.
With many search and content processing companies embracing fancy math, sentiment analysis, smart indexing and other math-based functions, will a search vendor find itself in the hot seat? I hope not but the market wants to buy fancy math. Understanding the fancy math may drive demand for individuals who can figure out if the systems and methods do what the licensee believes they do.
Oh, I like the word “billions.” Big money adds to the drama of analytics risk management in my opinion.
Stephen E Arnold, July 31, 2012
Microsoft and Yammer: Extending SharePoint Functionality
July 31, 2012
Yammer is what an enterprise social network tool; organizations implement it to spur collaboration between users. On the Yammer homepage we found a new application which permits Microsoft SharePoint Integration. After reading the specs, we found on the Microsoft blog about “Yammer-The Next Step for Social Networking In Schools?”
According to the post, Microsoft recently purchased Yammer. The post explains Yammer’s basic functions, the dashboard mirrors Facebook’s design with hints of Twitter. The post digs into how Yammer would be used in schools, basically the same way it would for any company: staff would use to communicate between departments, share content, etc. It can also be a boon for students too:
“We know that group work is a great way to encourage students to engage with their peers, but this isn’t easy when they all use different social networks, clouds and systems. By joining Yammer, students can create secure groups via which they can communicate their ideas, ask questions and share files, as well as allowing for their competitive side to come out through ‘Leaderboards’, which show data about who has received the most likes, replies and much.”
Students can perform group work, receive studying help, share content, and even praise each other within Yammer. While it can be a tool of food for students, it can also make cheating and plagiarism easier if not monitored. Yammer should install an app that will be able to detect plagiarism.
The surge of interest in social content is growing in government agencies, commercial organizations, and educational institutions. However, indexing and making this content
findable can be a challenging task. The tools an organization uses require tight integration with
a search system. Mindbreeze provides capabilities to make social content easily findable within a SharePoint environment. A Yammer style can enhance productivity. Mindbreeze offers a range of social and collaborative features and has the engineering expertise to resolve almost any search and retrieval issue. Check out the Mindbreeze social collaboration Web page for more information.
Whitney Grace, July 31, 2012
Sponsored by Mindbreeze
-

- Subscribe to Beyond Search
Feature archive
News archive

-