

Watson Put to Work in Academia as a Sounding Board and Study Buddy
November 24, 2015
The article on Kurzweil AI titled IBM’s Watson Shown to Enhance Human-Computer Co-Creativity, Support Biologically Inspired Design discusses a project set up among researchers and student teams at the Georgia Institute of Technology. The teams input information and questions about biomimetics, or biologically inspired design, and then Watson served as an “intelligent research assistant” for a Computational Creativity course in Spring 2015. The professor teaching the class, Ashok Goel, explained the benefits of this training.
“Imagine if you could ask Google a complicated question and it immediately responded with your answer — not just a list of links to manually open, says Goel. “That’s what we did with Watson. Researchers are provided a quickly digestible visual map of the concepts relevant to the query and the degree to which they are relevant. We were able to add more semantic and contextual meaning to Watson to give some notion of a conversation with the AI.”
Biomimetics is all about the comparison and inspiration of biological systems for technological system creation. The ability to “converse” with Watson could even help a student study a complicated topic and understand key concepts. Using Watson as an assistant who can bounce answers back at a professional could apply to many fields, and Goel is currently looking into online learning and healthcare. Watch out, grad students and TAs!
Chelsea Kerwin, November 24, 2015
Sponsored by ArnoldIT.com, publisher of the CyberOSINT monograph
Entity Extraction: Human Intermediation Still Necessary
November 23, 2015
I read “Facebook Should Be Able to Handle names like Isis and Phuc Dat Bich.” The article underscores the challenges smart software faces in a world believing that algorithms deliver the bacon.
Entity extraction methods requiring human subject matter experts and dictionary editors are expensive and slow. Algorithms are faster and over time more economical. Unfortunately the automated systems miss some things and get other stuff wrong.
The article explains that Facebook thinks a real person name Isis Anchalee is a bad guy. Another person with the transliterated Vietnamese name Phuc Dat Bich is a prohibited phrase.
What’s the fix?
First, the folks assuming that automated systems are pretty much accurate need to connect with the notion of an “exception file” or a log containing names which are not in a dictionary. What if there is no dictionary? Well, that is a problem. What about names with different spellings and in different character sets? Well, that too is a problem.
Will the vendors of automated systems point out the need for subject matter experts to create dictionaries, perform quality and accuracy audits, and update the dictionaries? Well, sort of.
The point is that like many numerical recipes the expectation that a system is working with a high degree of accuracy is often incorrect. Strike that, substitute “sort of accurate.”
The write up states:
If that’s how the company want the platform to function, Facebook is going to have to get a lot better at making sure their algorithms don’t unfairly penalize people whose names don’t fit in with the Anglo-standard.
When it comes time to get the automated system back into sync with accurate entity extraction, there may be a big price tag.
What your vendor did not make that clear?
Explain your “surprise” to the chief financial officer who wants to understand how you overlooked costs which may be greater than the initial cost of the system.
Stephen E Arnold, November 23, 2015
Inferences: Check Before You Assume the Outputs Are Accurate
November 23, 2015
Predictive software works really well as long as the software does not have to deal with horse races, the stock market, and the actions of single person and his closest pals.
“Inferences from Backtest Results Are False Until Proven True” offers a useful reminder to those who want to depend on algorithms someone else set up. The notion is helpful when the data processed are unchecked, unfamiliar, or just assumed to be spot on.
The write up says:
the primary task of quantitative traders should be to prove specific backtest results worthless, rather than proving them useful.
What throws backtests off the track? The write up provides a useful list of reminders:
- Data-mining and data snooping bias
- Use of non tradable instruments
- Unrealistic accounting of frictional effects
- Use of the market close to enter positions instead of the more realistic open
- Use of dubious risk and money management methods
- Lack of effect on actual prices
The author is concerned about financial applications, but the advice may be helpful to those who just want to click a link, output a visualization, and assume the big spikes are really important to the decision you will influence in one hour.
One point I highlighted was:
Widely used strategies lose any edge they might have had in the past.
Degradation occurs just like the statistical drift in Bayesian based systems. Exciting if you make decisions on outputs known to be flawed. How is that automatic indexing, business intelligence, and predictive analytics systems working?
Stephen E Arnold, November 23, 2015
Open Source Survey: One Big Surprise about Code Management
November 23, 2015
I read “Awfully Pleased to Meet You: Survey Finds Open Source Needs More Formal Policies.”
The fact that eight out of 10 outfits in the sample were using open source software was no surprise. The sponsor of the survey is open source centric.
The point I highlighted was:
According to the study, less than 42% of organizations maintain a IT Asset Management (ITAM) style inventory of open source components.
When I read this, I thought, “Who keeps track of the open source components?”
The answer in more than half the companies in the sample was, “Huh? What?”
I circled this point:
Shipley [Black Duck top dog] has also added the following comment, “In the results this year, it has become more evident that companies need their management and governance of open source to catch up to their usage. This is critical to reducing potential security, legal, and operational risks while allowing companies to reap the full benefits OSS provides.”
Is the reason companies spend money with open source commercial plays buying management? If that is the case, the successful commercial open source outfit is the one that has the ability to manage, not the technology and trends the marketers at certain commercial open source companies hype.
Stephen E Arnold, November 23, 2015
No Mole, Just Data
November 23, 2015
It all comes down to putting together the pieces, we learn from Salon’s article, “How to Explain the KGB’s Aazing Success Identifying CIA Agents in the Field?” For years, the CIA was convinced there was a Soviet mole in their midst; how else to explain the uncanny knack of the 20th Century’s KGB to identify CIA agents? Now we know it was due to the brilliance of one data-savvy KGB agent, Yuri Totrov, who analyzed U.S. government’s personnel data to separate the spies from the rest of our workers overseas. The technique was very effective, and all without the benefit of today’s analytics engines.
Totrov began by searching the KGB’s own data, and that of allies like Cuba, for patterns in known CIA agent postings. He also gleaned a lot if info from publicly available U.S. literature and from local police. Totrov was able to derive 26 “unchanging indicators” that would pinpoint a CIA agent, as well as many other markers less universal but useful. Things like CIA agents driving the same car and renting the same apartment as their immediate predecessors. Apparently, logistics agents back at Langley did not foresee that such consistency, though cost-effective, could be used against us.
Reporter Jonathan Haslam elaborates:
“Thus one productive line of inquiry quickly yielded evidence: the differences in the way agency officers undercover as diplomats were treated from genuine foreign service officers (FSOs). The pay scale at entry was much higher for a CIA officer; after three to four years abroad a genuine FSO could return home, whereas an agency employee could not; real FSOs had to be recruited between the ages of 21 and 31, whereas this did not apply to an agency officer; only real FSOs had to attend the Institute of Foreign Service for three months before entering the service; naturalized Americans could not become FSOs for at least nine years but they could become agency employees; when agency officers returned home, they did not normally appear in State Department listings; should they appear they were classified as research and planning, research and intelligence, consular or chancery for security affairs; unlike FSOs, agency officers could change their place of work for no apparent reason; their published biographies contained obvious gaps; agency officers could be relocated within the country to which they were posted, FSOs were not; agency officers usually had more than one working foreign language; their cover was usually as a ‘political’ or ‘consular’ official (often vice-consul); internal embassy reorganizations usually left agency personnel untouched, whether their rank, their office space or their telephones; their offices were located in restricted zones within the embassy; they would appear on the streets during the working day using public telephone boxes; they would arrange meetings for the evening, out of town, usually around 7.30 p.m. or 8.00 p.m.; and whereas FSOs had to observe strict rules about attending dinner, agency officers could come and go as they pleased.”
In the era of Big Data, it seems like common sense to expect such deviations to be noticed and correlated, but it was not always so obvious. Nevertheless, Totrov’s methods did cause embarrassment for the agency when they were revealed. Surely, the CIA has changed their logistic ways dramatically since then to avoid such discernable patterns. Right?
Cynthia Murrell, November 23, 2015
Sponsored by ArnoldIT.com, publisher of the CyberOSINT monograph
Search Experts Looking for Work? Rejoice
November 23, 2015
The article titled 17 Tools to Make LinkedIn Work for You on TNW provides some thoughtful commentary on how to make the best use of the social media platform LinkedIn. The article begins by emphasizing how important and relevant LinkedIn still is, particularly for people in Sales, who use the service to gather information and research prospects. It goes on to highlight the difficulty facing salespeople when it comes to searching LinkedIn, and the myriad of tools and Chrome extensions available to simplify search. The first on the list is Crystal,
“Language matters. How you communicate with someone, the words you use, how you structure your requests etc. affects their initial perception of you. And that’s what Crystal helps with. The standalone app as well as its Chrome extension allows you to profile Linkedin users profiles to detect their personality. And suggest the best ways to communicate with them. Crystal can tell you what to write in an email or how to create a message that engages them in a way they’d expect from you.”
Other resources include SalesLoft Prospector, which aids in building lists of targeted leads with contact information in tow, Elink.Club for LinkedIn, which visits 800 targeted profiles a day with the expectation that just under 10% of those users will, in turn, return the visit and become acquainted, and Discover.ly, which helps users establish mutual friends and social media commonalities with the profiles they view.
Chelsea Kerwin, November 23, 2015
Sponsored by ArnoldIT.com, publisher of the CyberOSINT monograph
The Art of Martec Content via a Renaissance Diagram
November 22, 2015
I love diagrams which explain content processing. I am ecstatic when a diagram explains information, artificial intelligence, and so much more. I feel as if I were a person from the Renaissance lowered into Nero’s house to see for the first time the frescos. Revelation. Perhaps this diagram points to a modern day Leonardo.
Navigate to “Marketing Data Technology: Making Sense of the Puzzle.” I admire the notion that marketing technology produces data. I love that tracking stuff, the spyware, the malware, and the rest of the goodies sales professionals use to craft their masterpieces. The idea that the data comprise a puzzle is a stroke of brilliance.
How does one convert data into a sale? Martec, marcom, or some other mar on one’s life?
Here’s the diagram. You can view a larger size at this link:
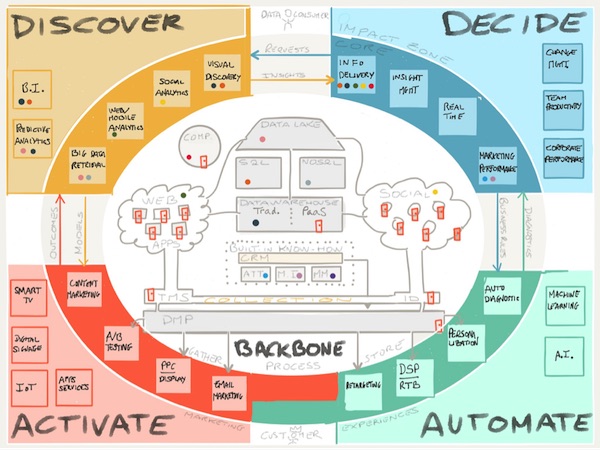
Notice the “space” is divided into four areas: discover, decide, activate, and automate. Notice that there are many functions in each area; for example, divide includes information delivery, insight real time, and marketing performance. Then notice that the diagram includes a complex diagram with a backbone, a data lake, the Web social media, and acronyms which mean nothing to me. There are like the artistic flourishes on the that hack’s paintings in the Sistine Chapel. The touches delight the eye, but no one cares about the details.
Now, I presume, you know how to make sense of the martec puzzle.
I find this type of diagram entertaining. I am not sure if it is a doodle or the Theory of Relativity for marketing professionals. Check out the original. I am still chuckling.
Stephen E Arnold, November 22, 2015
Search Provenance: Is That in France?
November 22, 2015
I find the excitement surrounding streaming apps interesting. I am not into apps for a mobile device. I use a mobile device to make phone calls and check email. I am hopelessly out of date, behind the times, old fashioned, and unhip.
That is fine with me.
Knowing what an app is doing seems prudent. I am not overly confident that 20 somethings will follow the straight and narrow. In fact, I am not sure those older stay within the rule of the road. The information highway? Dude, get out of my way.
The big point is that the write up “Teens Have Trouble Telling between Google Ads and Search Links” makes vivid the risk inherent in losing checkpoints, informational signals, and white lines in the datasphere.
The write up states:
UK watchdog Ofcom has posted a study showing that just 31 percent of kids aged 12 to 15 can tell the difference between a Google search ad and the real results just below them. They also tend to be overly trusting, as 19 percent of those young teens believe that all online results must be true. Not surprisingly, the figures get worse with younger children — just 16 percent of those aged 8 to 11 know whether they’re seeing an ad or a result.
Nothing like the ability to think and determine if information is valid. Do you want a ticket to provenance? I hear the food is wonderful.
Stephen E Arnold, November 22, 2015
Google and Search Quality Guidelines
November 21, 2015
You want your Web site to be found despite the shift to mobile devices. You want your mobile site to be found as more than half of the world ignores the old school approach to Web surfing. You want, no, you need traffic now.
The pathway to traffic heaven is explained in more than 150 pages of Google goodness. The Google Search Quality Guidelines may be downloaded for now at this link.
What will you learn:
- How to conform to Google’s definition of “quality”
- What to do to produce higher “quality” Web pages
- What to do to signal Google that you are into mobile.
Does the document explain the thresholds and interlinkage of the “scores” generated by the layers of code wrapped around PageRank.
Nope.
If you implement these actions, will you experience traffic like never before? Nah. Buy Adwords. The Google wants to shave time off its processes. The guidelines may have more to do with Google’s needs than webmasters?
I like the “proprietary and confidential” statement too.
Stephen E Arnold, November 21, 2015
Data and Information: Three Cs for an Average Grade
November 21, 2015
I read “Why Companies Are Not Engaging with Their Data.” The write up boils down the “challenge” to three Cs; that is, a mnemonic which makes it easy to pinpoint Big Data clumsiness.
The three Cs are:
- Callowness
- Cost
- Complexity.
How does one get past the notion of inexperience? I suppose one muddles through grade school, high school, college, and maybe graduate school. Then one uses “experience” to get a job and one can repeat this process with Big Data. How many organizations will have an appetite for the organic approach to inexperience? Not many I assert. We live in a quick fix, do it now environment which darned well better deliver an immediate pay off or “value.” Big Data may require experience but the real world wants instant gratification.
Cost remains a bit of a challenge, particularly when revenues are under pressure. Data analytics can be expensive when done correctly and really costly if done incorrectly.
Complexity. Math remains math. Engineering data management systems tickles the fancy of problem solvers. Combine the two, and the senior management of many firms are essentially clueless about what is required to deliver outputs which are on the money and with budgets.
The write up states:
As a recent report from Ernst & Young points out ‘Most organizations have complex and fragmented architecture landscapes that make the cohesive collation and dissemination of data difficult.
In short, big hat, no cattle. Just like the promises of enterprise search vendor to make information accessible to those making business decisions, the verbal picture painted by marketers is more enticing than the shadow cast by Big Data’s Cs. I see that.
Stephen E Arnold, November 21, 2015
-

- Subscribe to Beyond Search
Feature archive
News archive

-