

Entity Extraction: Not As Simple As Some Vendors Say
November 19, 2024
 No smart software. Just a dumb dinobaby. Oh, the art? Yeah, MidJourney.
No smart software. Just a dumb dinobaby. Oh, the art? Yeah, MidJourney.
Most of the systems incorporating entity extraction have been trained to recognize the names of simple entities and mostly based on the use of capitalization. An “entity” can be a person’s name, the name of an organization, or a location like Niagara Falls, near Buffalo, New York. The river “Niagara” when bound to “Falls” means a geologic feature. The “Buffalo” is not a Bubalina; it is a delightful city with even more pleasing weather.
The same entity extraction process has to work for specialized software used by law enforcement, intelligence agencies, and legal professionals. Compared to entity extraction for consumer-facing applications like Google’s Web search or Apple Maps, the specialized software vendors have to contend with:
- Gang slang in English and other languages; for example, “bumble bee.” This is not an insect; it is a nickname for the Latin Kings.
- Organizations operating in Lao PDR and converted to English words like Zhao Wei’s Kings Romans Casino. Mr. Wei has been allegedly involved in gambling activities in a poorly-regulated region in the Golden Triangle.
- Individuals who use aliases like maestrolive, james44123, or ahmed2004. There are either “real” people behind the handles or they are sock puppets (fake identities).
Why do these variations create a challenge? In order to locate a business, the content processing system has to identify the entity the user seeks. For an investigator, chopping through a thicket of language and idiosyncratic personas is the difference between making progress or hitting a dead end. Automated entity extraction systems can work using smart software, carefully-crafted and constantly updated controlled vocabulary list, or a hybrid system.
Automated entity extraction systems can work using smart software, carefully-crafted and constantly updated controlled vocabulary list, or a hybrid system.
Let’s take an example which confronts a person looking for information about the Ku Group. This is a financial services firm responsible for the Kucoin. The Ku Group is interesting because it has been found guilty in the US for certain financial activities in the State of New York and by the US Securities & Exchange Commission.
One of the Ku Group’s senior executives plays a “name game.” An individual named “Johnny” uses versions of his name like
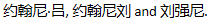
These are then used in news and legal documents as “Johnny Lyu” “John Lu” and “J. Liu.”
Is there a system able to process these variants and map them to versions in other languages in an automated manner?
The answer is, “Yes.”
The Beyond Search research team identified Bitext, Madrid, Spain, as having one of the most interesting and accurate named entity extraction systems available. The firm’s NER or Named Entity Recognition handles complex entity identification, parsing, and indexing in more than 20 languages, including those with challenging writing systems; for example, Arabic and Chinese.
The Bitext NER solution offers several key advantages:
• Local SDK Distribution: The self-contained, local SDK eliminates cloud dependencies, ensuring optimal speed and security, particularly in environments where data privacy is paramount.
• OEM Integration: Seamlessly integrated as a white-label solution, Bitext technology can be embedded directly into an existing content processing system, allowing a vendor to maintain full control over the user experience while enhancing existing capabilities.
• Transparency & Reliability: Unlike the unpredictable nature of Large Language Models (LLMs), NER technology avoids black-box approaches, providing consistent and explainable results, which is critical for compliance and audit purposes.
• Speed, Efficiency, and Precision: Developed in C, the NER system is lightweight, fast, and resource-efficient, allowing for real-time extraction of critical entities, even in high-volume data environments like real-time or near-real time content processing.
• Source Code Availability: For added flexibility, Bitext offers optional access to the source code, enabling a vendor to make custom adaptations to fit their unique requirements and maintain control over a vendor’s proprietary enhancements.
Furthermore, NER technology is designed to identify and categorize key information within text, such as names of people, organizations, locations, dates, and other entities like license numbers and bank account codes. This capability is crucial for analyzing unstructured data and extracting actionable intelligence. In regions like Southeast Asia, known for complex cyber fraud activities, the NER technology excels in addressing specific challenges. By reliably extracting entities, aliases, and associated metadata from diverse and unstructured sources, Bitext empowers intelligence analysts and investigators to detect patterns and connections in scenarios involving organizations such as Shwe Kokko and Yatai International Holding Group.
Bitext provides entity extraction technology to three of the top five publicly traded firms on the US NASDAQ for over a decade. If you want to more about Bitext and its Named Entity Recognition system, contact Bitext at this link. The firm’s Web site is www.bitext.com.
Stephen E Arnold, November 19, 2024
Comments
One Response to “Entity Extraction: Not As Simple As Some Vendors Say”
-

- Subscribe to Beyond Search
Feature archive
News archive

-
[…] wrote a short item about tracking Chinese names translated to English, French, or Spanish with widely varying […]