

Elastic and Its Approach to Its Search Business
February 16, 2021
This blog post is about Elastic, the Shay Banon information retrieval company, not Amazon AWS Elastic services. Confused yet? The confusion will only increase over time because the “name” Elastic is going to be difficult to keep intact due to Amazon’s ability to erode brand names.
But that’s just one challenge the Elastic search company founded by the magic behind Compass Search. An excellent analysis of Elastic search’s challenges appears in “Elastic Has Stretched the Patience of Many in Open Source. But Is There Room for a Third Way?”
The write up quotes an open source expert as saying:
Let’s be really clear – it’s a move from open to proprietary as a consequence of a failed business model decision…. Elastic should have though their revenue model through up front. By the time the team made the decision to open source their code, the platform economy existed and their decisions to open source ought to
have been aligned to an appropriate business model.
I circled this statement in the article:
Sympathy for Elastic’s position comes from a perhaps unexpected source. Matt Assay, principal at Elastic’s bête noire AWS, believes it’s time to revisit the idea of “shared source”, a licensing scheme originally dreamed up by Microsoft two decades ago as an answer to the then-novel open source concept. In shared source, code is open – as in visible – but its uses are restricted… The heart of the problem is about who gets to profit from open source software. To help resolve that problem, we just might need new licensing.
Information retrieval is not about precision and recall, providing answers to users, or removing confusion about terms and product names — search is about money. Making big bucks from a utility service continues to lure some and smack down others. Now it is time to be squishy and bouncy I suppose.
Stephen E Arnold, February 16, 2021
Google and Broad Match
February 11, 2021
I read “Google Is Moving on From Broad Match Modifier.” The essay’s angle is search engine optimization; that is, spoofing Google’s now diluted relevance methods. The write up says:
Google says it has been getting better at learning the intent behind a query, and is therefore more confident it can correctly map advertisements to queries. As that ability improves, the differences between Phrase Match and Broad Match Modified diminishes. Moving forward, there will be three match types, each with specific benefits:
- Exact match: for precision
- Broad match: for reach
- Phrase match: in Google’s words, to combine the best of both.
Let’s assume that these are the reasons. Exact match delivers precision. Broad match casts a wide net. No thumbtypers wants a null set. Obviously there is zero information in a null set in the mind of the GenXers and Millennials, right? The phrase match is supposed to combine precision and recall. Oh, my goodness, precision and recall. What happened to cause the Google to reach into the deep history of STAIRS III and RECON for this notion.
Google hasn’t and won’t.
The missing factor in the write up’s analysis is answering the question, “When will each of the three approaches be used, under what conditions, and what happens if the bus drives to the wrong city?” (This bus analogy is my happy way of expressing the idea that Google search results often have little to do with either the words in the user’s query or the “intent” of the user (allegedly determined by Google’s knowledge of each user and the magic of more than 100 “factors” for determining what to present).
The key is the word “reach.” Changes to Google’s methods are, from my point of view, are designed to accomplish one thing: Burn through ad inventory.
By killing off functioning Boolean, deprecating search operators, ignoring meaningful time indexing, and tossing disambiguation into the wind blowing a Google volleyball into Shoreline traffic — the company’s core search methods have been shaped to produce money.
SEO experts don’t like this viewpoint. Google doesn’t care as long as the money keeps flowing. With Google investing less in infrastructure and facing significant pressure from government investigators and outfits like Amazon and Facebook, re-explaining search boils down to showing content which transports ads.
Where’s that leave the SEO experts? Answer: Ad sales reps for the Google. Traffic comes to advertisers. But the big bucks are the big advertisers’ campaigns which expose a message to as many eyeballs as possible. That’s why “broad reach” is the fox in the relevance hen house.
Stephen E Arnold, February 11, 2021
Algolia: Making Search Smarter But Is This Possible?
February 5, 2021
A retail search startup pins its AI hopes on a recent acquisition, we learn from the write-up at SiliconANGLE, “Algolia Acquires MorphL to Embed AI into its Enterprise Search Tech.” The company is using its new purchase to power Algolia AI. The platform predicts searchers’ intent in order to deliver tailored (aka targeted) search results, even on a user’s first interaction with the software. Writer Mike Wheatley tells us:
“Algolia sells a cloud-based search engine that companies can embed in their sites, cloud services and mobile apps via an application programming interface. Online retailers can use the platform to help shoppers browse their product catalogs, for example. Algolia’s technology is also used by websites such as the open publishing platform Medium and the online learning course provider Coursera. Algolia’s enterprise-focused search technology enables companies to create a customized search bar, with tools such as a sidebar so shoppers can quickly filter goods by price, for example. MorphL is a Romanian startup that has created an AI platform for e-commerce personalization that works by predicting how people are likely to interact with a user interface. Its technology will extend Algolia’s search APIs with recommendations and user behavior models that will make it possible for e-commerce websites and apps to deliver more ‘intent-based experiences.’”
The Google Digital News Initiative funded MorphL’s development. The startup began as an open-source project in 2018 and is based in Bucharest, Romania. Headquartered in San Francisco, Algolia was founded in 2012. MorphL is the company’s second acquisition; it plucked SeaUrchin.IO in 2018.
Will Algolia search be smarter, maybe even cognitive? Worth watching to see how many IQ points are added to Algolia’s results.
Cynthia Murrell, February 5, 2021
Old Book Illustrations: No Photoshop or Illustrator, Thank You
February 1, 2021
Here is a useful resource—Old Book Illustrations. The site began as a way for the creators to share pictures from their own collection of Victorian and French Romantic books and grew as they explored other collections online. All images are in the public domain. The site’s About page elaborates:
“Although it would have been possible to considerably broaden the time-frame of our pursuit, we chose to keep our focus on the original period in which we started for reasons pertaining to taste, consistency, and practicality: due to obvious legal restrictions, we had to stay within the limits of the public domain. This explains why there won’t be on this site illustrations first published prior to the 18th century or later than the first quarter of the 20th century. We are not the only image collection on the web, neither will we ever be the largest one. We hope however to be a destination of choice for visitors more particularly interested in Victorian and French Romantic illustrations—we understand French Romanticism in its broadest sense and draw its final line, at least in the realm of book illustration, at the death of Gustave Doré. We also focused our efforts on offering as many different paths and avenues as possible to help you find your way to an illustration, whether you are looking for something specific or browsing randomly. The many links organizing content by artist, language, publisher, date of birth, and more are designed to make searching easier and indecision rewarding.”
The site is well organized and easy to either search or browse is several ways—by artists, publishers, subjects, art techniques, book titles, and formats (portrait, landscape, tondo, or square). There is even a “navigation how-to” if one wants a little help getting started. The site also posts articles like biographies and descriptions of cultural contexts. We recommend checking it out and perhaps bookmarking it for future use.
Cynthia Murrell, February 1, 2021
News Flash: ECommerce Search Is Not Enterprise Search
January 8, 2021
Now here is some crazy stuff—e-commerce search masquerading as enterprise search. Business Wire shares, “Searchspring Named Leader in Enterprise Search Software and E-Merchandising in G2 Grid Reports for Winter 2021.” Now Searchspring may or may not be the best commerce platform, but enterprise search is an entirely different animal. The press release crows:
“The reports’ scores are based on verified reviews by customers and grounded on ease of use, ease of setup, ease of administration, and how well the software meets requirements. G2 is the world’s largest B2B tech marketplace for software and services, helping businesses make smarter buying decisions. Searchspring ranked No. 2 across all providers, earning its Winter 2021 ‘Leader’ position in Enterprise Search Software and E-Merchandising, in addition to being recognized for ‘Best Support’, ‘Easiest Admin’, and ‘Easiest Setup’. Rated by Searchspring customers as 4.9/5 stars, Searchspring was favorably reviewed for offering the ‘Gold Standard for Functionality’, ‘Brilliant Service’, and ‘Incredible Performance. Amazing People. Fantastic Results.’”
So G2’s qualifications for winning make no distinction between e-commerce and enterprise search. We suppose we cannot blame the company for taking the title it was handed and running with it. 2020 has been a big year for online retail, and Searchspring is happy to be recognized for being on top of the surge. Founded in 2007, the firm is located in San Antonio, Texas.
Cynthia Murrell, January 8, 2021
Stork Search for Static Sites
January 8, 2021
Just a short honk to let our dear readers in on this search resource: If you host a website with static content, Stork may be for you. At the platform’s landing page, Creator James Little tells us how it works:
“Stork is two things that work in tandem to put a beautiful, fast, and accurate search interface on your static site. First, it’s a program that indexes your content and writes that index to disk. Second, it’s a JavaScript library that downloads that index, hooks into a search input, and displays optimal search results immediately to your user, as they type. Stork is built with Rust, and the JavaScript library uses Web Assembly behind the scenes. It’s built with content creators in mind, in that it requires little-to-no code to get started and can be extended deeply. It’s perfect for JAMstack sites and personal blogs, but can be used wherever you need a search interface.”
The page offers a setup guide which, interestingly, uses the task of embedding The Federalist Papers as an example. Complete with snippets of code, the description walks users through setup, customization, and index building, so see the page for those details. One can see the project’s GitHub here.
Cynthia Murrell, January 8, 2021
Factoids from Best Paper Awards in Computer Science
January 6, 2021
I noted “Best Paper Awards in Computer Science Since 1996.” The year caught my attention because that was the point in time at which software stagnation gained traction. See “The Great Software Stagnation” for the argument.
The Best Papers tally represents awards issued to the “best papers”. Hats off to the compiler Jeff Huang and his sources and helpers.
I zipped through the listings which contained dozens upon dozens of papers I knew absolutely zero about. I will probably be pushing up daisies before I work through these write ups.
I pulled out several observations which answered questions of interest to me.
First, the data illustrate the long tail thing. Stated another way, the data reveal that if an expert wants to win a prestigious award, it matters which institution issues one’s paycheck:
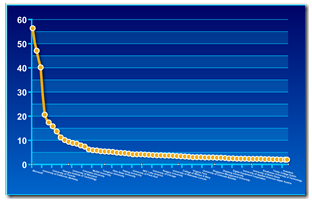
Second, what are the most prestigious “names” to which one should apply for employment in computer science? Here’s the list of the top 25. The others are interesting but not the Broadway stars of the digital world:
| 1 | Microsoft | 56.4 |
| 2 | University of Washington | 50.5 |
| 3 | Carnegie Mellon University | 47.1 |
| 4 | Stanford University | 43.3 |
| 5 | Massachusetts Institute of Technology | 40.2 |
| 6 | University of California, Berkeley | 29.2 |
| 7 | University of Michigan | 20.6 |
| 8 | University of Illinois at Urbana–Champaign | 18.5 |
| 9 | Cornell University | 17.4 |
| 10 | 16.8 | |
| 11 | University of Toronto | 15.8 |
| 12 | University of Texas at Austin | 14.5 |
| 13 | IBM | 13.7 |
| 14 | University of British Columbia | 12.4 |
| 15 | University of Massachusetts Amherst | 11.2 |
| 16 | Georgia Institute of Technology | 10.3 |
| 17 | École Polytechnique Fédérale de Lausanne | 10.1 |
| 18 | University of Oxford | 9.6 |
| 19 | University of California, Irvine | 9.4 |
| 20 | Princeton University | 9.1 |
| 21 | University of Maryland | 8.9 |
| 22 | University of California, San Diego | 8.7 |
| 23 | University of Cambridge | 8.6 |
| 24 | University of Wisconsin–Madison | 8 |
| 25 | Yahoo | 7.9 |
Note that Microsoft, the once proud Death Star of the North, is number one. For comparison, the Google is number 10. But the delta in average “bests” is an intriguing 39.6 papers. The ever innovative IBM is number 13, and the estimable Yahoo Oath Verizon confection is number 25.
I did not spot a Chinese University. A quick scan of the authors reveals that quite a few Chinese wizards labor in the research vineyards at these research-oriented institutions. Short of manual counting and analysis of names, I decided to to calculate authors by nationality. I think that’s a good task for you, gentle reader.
What about search as a research topic in this pool? I used a couple of online text analysis tools like Writewords, a tool on my system, and the Madeintext service. The counts varied slightly, which is standard operating procedure for counting tools like these. The 10 most frequently used words in the titles of the award winning papers are:
| data 63 times |
| based 56 times |
| learning 53 times |
| using 49 times |
| design 45 times |
| analysis 38 times |
| software 36 times |
| time 36 times |
| search 35 times |
| Web 30 times |
The surprise is that “search” was, based on my analysis of the counts I used, was the ninth most popular word in the papers’ titles. Who knew? Almost as surprising was “social” ranking a miserable 46th. Search, it seems, remains an area of interest. Now if that interest can be transformed into sustainable revenue and sufficient profit to fund research, bug fixes, and enhancements — life would be better in my opinion.
Stephen E Arnold, January 5, 2020
Sinequa: A Logical Leap
December 21, 2020
The French have contributed significantly to logic. One may not agree with the precepts of Peter Abelard, the enlightened René Descartes, or the mathiness of Jean-Yves Girard. A rational observer of the disciplines of search and retrieval may want to inspect the reasoning of “How Apple’s Pending Search Engine Hints at a Rise in Enterprise Search.”
The jumping off point for this essay is the vaporware emitted by heavy breathing thumb typers that Apple will roll out a Web search engine. The idea is an interesting one, but, as I write this, Apple is busy with a number of tasks. But vaporware is a proven fungible among those engaged in enterprise search. The idea of finding just the information one needs when working in a dynamic company is a bit like looking for the end of a rainbow. One can see it; therefore, there must be an end. Even better, mothers have informed their precocious progeny that there is a pot of gold at the terminus.
What can one do with the assumption that an Apple Web search engine will manifest itself?
The answer is probably one which will set a number of French logicians spinning in their graves.
According to the write up from an “expert” at the French enterprise search firm Sinequa:
So, if Apple is spending (most likely) billions of dollars recreating a tool that effortlessly finds us the global sum of human knowledge, then isn’t it about time we improve the tools that knowledge workers have to do their jobs?
That’s quite a leap, particularly for a discipline which dates from the pre-STAIRS era. But from a company founded in 2002, the leap is nothing out of the ordinary.
But enterprise search is a big job; for example:
The complication is that enterprise data is more heterogeneous in nature than internet data, which is homogeneous by comparison. As a result, enterprise data tends to reside in silos, so if we need to find a document, we can narrow down where we look to a couple of places – for instance, in our email or on a particular SharePoint. However. further complication arises when we don’t know where to look – or worse still, we don’t know what we’re looking for. A siloed approach works fairly well but at some point, we start to lose track of where to look. According to recent Sinequa research, knowledge workers currently have to access an average of around six different systems when looking for information – that’s potentially six individual searches you need to make to find something.
And why has enterprise search as a discipline failed to deliver exactly what an employee needs to do his or her job at a particular point in time?
That’s a good question which the logical confection does not address. No problem. Vendors of enterprise search have dodged the question for more than half a century.
Here’s how the essary nails down its stunning analysis:
It’s only a matter of time before enterprise search reaches a similar tipping point. There will be a time when the silos become too many or the time taken to search them becomes too great. The question is whether the reason for enterprise to take search seriously is because a lack of search is seen as an existential threat, or an opportunity to differentiate.
Okay, 50 years and counting.
Do you hear that buzzing sound? I surmise that it is René Descartes trying to contact Jacque Ellul to discuss how French logic fell off the wine cart.
My hunch is that Messrs. Descartes and Ellul will realize that providing access to information in response to a particular business need is a digital version of running toward the end of the rainbow. Some exercise, d’accord, but the journey may end in disappointment.
Par for the course for a company whose product pricing begins at $0.01 if Sourceforge is to be believed. Yep, $0.01. Logical? Sure. It’s marketing consistent with the hundreds of companies which have flogged enterprise search for decades.
Rainbows. Pots of gold. Yep.
Stephen E Arnold, December 20, 2020
Smart Software Can Find Different Points of View
December 18, 2020
All news outlets are dominated by one-sided rhetorics and dance to ratings and political tunes. The goal of news outlets is to sensationalize everything to generate profit and promote political agendas. It leaves viewers wanting more from news outlets, such as unbiased information. It is a sad time, indeed, when individuals long for news outlets of yesteryears because they had more diverse perspectives.
With today’s advanced technology one would think there would be a news search engine that rounded by articles of varying perspectives so individuals could come to their own opinions. Apparently such a search engine exists: https://articlefinder.org
Article Finder’s has a minimalist UI and uses colors to make people think about Google. The premise is simple:
“People will view the same story in different ways based on their priors. It’s important to understand how others view the same event to better understand how they think. Article Finder allows you to find articles of the same story from different sources so you can gain a holistic picture.”
After conducting a few searches, Article Finder does retrieve different articles about the same topics. It relies on a customizable Google search. The search results are returned in an organized list that states the title and news source. The minimalist style decreases distraction.
However, I wonder if Article Finder is any different from a regular Google news search? Google offers news from multiple sources and even customizable options through Google profiles. Article Finder serves a purpose but it seems unnecessary unless they add something new.
Whitney Grace, December 18, 2020
Amazon Uses Googley Phrase Which Also Was Mostly Marketing Hoo Hah
December 17, 2020
You may not remember, but I do. Like yesterday. I wrote an analysis for the late, highly regarded financial services firm and contract bridge epicenter BearStearns. The document was published more than a decade ago. Two things happened. Google immediately rolled out a special event to announce universal search. I heard that the name morphed into unified search and then federated search among some Googlers. The idea is that a user runs a query and expects the content of which he or she is aware will be in the results. Ho ho ho. The merrie search elves know that even at the mighty Google one must search silos of data. Universal, unified, federated. That’s like a Dark Web vendor posting 1 800 YOU WISH as the customer support number for bogus contraband.
Imagine my surprise when I noted this Amazon post:
Universal, unified, whatever. I find it fascinating how search related terminology comes into vogue and falls out of favor only to return in a weird but actually identifiable Kondratiev waves. Examples include:
- Inference (nifty but there was a search vendor called Inference now essentially forgotten)
- Boolean which several vendors have resurrected after thumbtypers declared the method dead
- indexing now creeping back into favor after metadata and enrichment have not moved the needle for jargon recycling.
Yep, unified. Much better than “federated”, of course. Remember Vivisimo? I sort of do, but IBM repositioned it as some whizzy part of Watson. Is search at AWS or anywhere for that matter what the user expects. Ho ho ho say the merrie search elves. Ho ho ho. That’s a good one.
Stephen E Arnold, December 16, 2020
-

- Subscribe to Beyond Search
Feature archive
News archive

-