

SharePoint: Enterprise Search Which Will Never Ever Let You Lose Anything Again
May 30, 2015
Bold assertion. I read “Why Using Microsoft SharePoint Will Improve Your Business Performance with a Simple Search Feature.” Memorable for several reasons:
- SharePoint has “amazing search capabilities.” (I mistakenly understood that the “new” SharePoint search was not yet available. Oh, well, I am in Harrod’s Creek, not a “nice venue in London.” Search is better when viewed from a “nice venue” I assume.
- I will never lose anything again. I assume, perhaps incorrectly, that the “anything” refers to a document I created and either parked intentionally or had parked for me by Microsoft’s “amazing” SharePoint. I note that the statement is a categorical, and then often present logical challenges to someone who asks, “Really? What’s the evidence you have to back up this wild and frisky claim?”
- I note that I can type a word or phrase to “surface every relevant document across all of the sites I have access to.” The author adds, “It’s brilliant.” Okay, got it, but I don’t believe it based on observation, our own hands on experiences, and the weed pile of third party vendors who insist their software actually makes SharePoint usable. I would list them, but you probably have these outfits’ burned into your memory.
What is interesting is that the focus of the write up seems to be Microsoft Dynamics GP. It is mentioned a couple of time. There are also references to Delve, another Microsoft search system.
Frankly I am not sure if the cheerleading for “brilliant” search is credible. We have worked on projects in organizations where SharePoint is the “pluming.” In a conference call last week, the client, a relatively large outfit in the Fortune 100, reported these “issues” with SharePoint:
- Users cannot locate documents created within 24 hours and written to the designated SharePoint device
- Documents in a results list do not include the version of the document for which the user searches
- Images of purchase orders for a company issued with a unique code cannot be retrieved
- Queries take more time than a Google query to complete
- The information about employees with specific expertise is not complete; that is, there will be no data about education or certain projects
- Collaboration is flakey
- The system crashes.
I could work through the list, but the point is that SharePoint is big business for those who get a job to maintain it and, in theory, make it work. SharePoint is the fertile field in which third party vendors plant applications to improve on what Microsoft offers. There are integrators who have specialized skills and want SharePoint to remain the money tree plantation the consultants have come to call home.
In short, what can one believe about Microsoft search? Delve into that.
Stephen E Arnold, May 30, 2015
Stephen E Arnold, June 2, 2015
Amazon and Elasticsearch
May 29, 2015
If you are curious about the utility of Elastic’s technology, you will find “Indexing Common Crawl Metadata on Amazon EMR Using Cascading and Elasticsearch” a useful article to review. The main idea is that Amazon made Elasticsearch do some circus tricks. The write up explains the approach, provides code snippets, and includes a couple of nifty graphics which help those zany Zonies figure out the implications of the data crunched. the main idea is that Elasticsearch did something use with content in everyone’s favorite magic wand Hadoop. Why didn’t Amazon use LucidWorks (Really?)? Hmm. Good question.
Stephen E Arnold, May 29, 2015
JobSamurai Offers Alternative Job Search Method (Without the Search)
May 29, 2015
The article titled Take the Search Out of Job Hunting with JobSamurai on MakeUseOf describes the perks in using JobSamurai next time you are out of work. A lot of people rely on services like Craigslist, but anyone who has searched for a job there knows that a good portion of the listings are frauds, or just non-existent. The number of irrelevant posts are also high and weeding through them all is time-consuming and frustrating. JobSamurai claims to have the answers, with a job website that minimizes the search factor. The article explains,
“JobSamurai uses your information to find jobs around the web that match your profile, then shows them to you as banner adverts on the websites you visit most often. They do this by leaving a tracking cookie in your web browser that sends data back to JobSamurai to notify them of where to display their content. It typically takes 10-15 days for their internal search engines to find all the jobs that match a candidate.”
While this means that users will need to exercise some patience before seeing results, it is balanced out by the absence of those terrible spam emails that job search websites love to litter your inbox with. JobSamurai promises to limit itself to one email every two months- which really seems like no emails at all.
Chelsea Kerwin, May 29, 2014
Sponsored by ArnoldIT.com, publisher of the CyberOSINT monograph
Search Functionality for the Roku 2
May 29, 2015
In with search, out with the remote-based headphone jack. Roku has had to weigh their priorities while considering user-friendly features, we learn from “Roku 2 Gets a Facelift with New Search Engine” at ITProPortal. The need for an affordable price point required the Roku 2 media-streaming player to drop some features so new ones could be added. Writer Sead Fadilpaši? reports:
“The new remote will work on IR, meaning you’ll need a clear line of sight to switch channels. The remote has also lost the headphone jack, which some will find quite saddening, as well as the motion sensor. Both remotes will now feature four dedicated buttons, which can’t be reprogrammed, giving users quick access to Netflix, YouTube, Google Play, and Rdio. New features also include a search engine and show notifications, letting people know when a certain show is available. The new Roku 2 will cost as much as the Apple TV after its price drop – a very competitive £69. Aside from improved hardware specs Roku has confirmed to Pocket-lint the new box will come with improved software that should have a dramatic affect in speeding up accessing your favorite channels, shows and movies.”
All Roku devices will be getting the revised interface, which adds a couple of features and is expected to speed boot times. The write-up reminds us that the Roku has a mobile app, with a new version due out soon. So if you really miss that headphone jack, just swap their remote for your smart phone. I leave the motion-sensor hack to you.
Cynthia Murrell, May 29, 2015
Sponsored by ArnoldIT.com, publisher of the CyberOSINT monograph
The Future of Enterprise and Web Search: Worrying about a Very Frail Goose
May 28, 2015
For a moment, I thought search was undergoing a renascence. But I was wrong. I noted a chart which purports to illustrate that the future is not keyword search. You can find the illustration (for now) at this Twitter location. The idea is that keyword search is less and less effective as the volume of data goes up. I don’t want to be a spoil sport, but for certain queries key words and good old Boolean may be the only way to retrieve certain types of information. Don’t believe me. Log on to your organization’s network or to Google. Now look for the telephone number of a specific person whose name you know or a tire company located in a specific city with a specific name which you know. Would you prefer to browse a directory, a word cloud, a list of suggestions? I want to zing directly to the specific fact. Yep, key word search. The old reliable.
But the chart points out that the future is composed of three “webs”: The Social Web, the Semantic Web, and the Intelligent Web. The dates for the Intelligent Web appears to be 2018 (the diagram at which I am looking is fuzzy). We are now perched half way through 2015. In 30 months, the Intelligent Web will arrive with these characteristics:
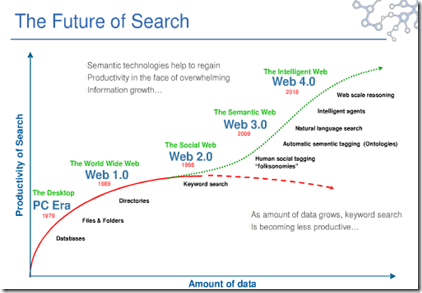
- Web scale reasoning (Don’t we have Watson? Oh, right. I forgot.)
- Intelligent agents (Why not tap Connotate? Agents ready to roll.)
- Natural language search (Yep, talk to your phone How is that working out on a noisy subway train?)
- Semantics. (Embrace the OWL. Now.)
Now these benchmarks will arrive in the next 30 months, which implies a gradual emergence of Web 4.0.
The hitch in the git along, like most futuristic predictions about information access, is that reality behaves in some unpredictable ways. The assumption behind this graph is “Semantic technology help to regain productivity in the face of overwhelming information growth.”
Data Darkness
May 28, 2015
According to Datameer, organizations do not use a large chunk of their data and it is commonly referred to “dark data.” “Shine Light On Dark Data” explains that organizations are trying to dig out the dark data and use it for business intelligence or in more recent terms big data. Dark data is created from back end business processes as well as from regular business activities. It is usually stored on storage silo in a closet and only kept for compliance audits.
Dark data has a lot of hidden potential:
“Research firm IDC estimates that 90 percent of digital data is dark. This dark data may come in the form of machine or sensor logs that when analyzed help predict vacated real estate or customer time zones that may help businesses pinpoint when customers in a specific region prefer to engage with brands. While the value of these insights are very significant, setting foot into the world of dark data that is unstructured, untagged and untapped is daunting for both IT and business users.”
The article suggests making a plan to harness the dark data and it does not offer much in the way of approaching a project other than making it specifically for dark data, such as identifying sources, use Hadoop to mine it, and tests results against other data sets.
This article is really a puff piece highlighting dark data without going into much detail about it. They are forgetting that the biggest movement in IT from the past three years: big data!
Whitney Grace, May 28, 2015
Sponsored by ArnoldIT.com, publisher of the CyberOSINT monograph
SharePoint Is Back and Yammer Is Left Behind
May 28, 2015
Many old things become trend and new again, and even that holds true with software, at least in principle. The old functions of SharePoint are withstanding the test of time, and the trendy new buzzwords that Microsoft worked so hard to push these last few years (cloud, social, collaborative) are fading out. Of course, some of it has to do with perception, but it does seem that Microsoft is harkening back to what the tried and true longtime users want. Read more in the CMS Wire article, “SharePoint is Back, Yammer… Not So Much.”
The article sums up the last few years:
“But these last few years, Microsoft seemingly didn’t want to talk about SharePoint. It wanted to talk about Office 365, the cloud, collaboration, social, mobile devices and perpetual monthly licensing models. Yet no one appears to have told many of the big traditional SharePoint customers of these shifts. These people are still running SharePoint 2007, 2010 and 2013 happily in-house and have no plans to change that for many years.”
So it seems that with the returned focus to on-premises SharePoint, users are pleased in theory. However, it remains to be seen how satisfying SharePoint Server 2016 will be in reality. To stay tuned to the latest reviews and feedback, keep an eye on ArnoldIT.com and his dedicated SharePoint feed. Stephen E. Arnold is a longtime leader in search with an interest in SharePoint. His reporting will shed a light on the realities of user experience once SharePoint Server 2016 becomes available.
Emily Rae Aldridge, May 28, 2015
Sponsored by ArnoldIT.com, publisher of the CyberOSINT monograph
Altiar And dtSearch Combine
May 27, 2015
Sometimes when items are combine they create something even better, such as Oreos and peanut butter, Disney and Marvel, and Netflix and original series. EContentMag alerted us that a new team-up is underway between two well known companies. The press release title says it all, “Altiar Cloud-Based ECM Platform Is Embedding The dtSearch Engine.” Altair is an enterprise content management platform that has been specifically used by Microsoft Azure. The popular dtSearch platform has been searching through terabytes since 1991 and is referred to as a powerful search tool. Embedding dtSearch into the Altiar core will make it a more powerful ECM.
Altiar is a popular ECM and can only be improved by dtSearch:
“A cloud-based service, Altiar includes rapid setup, scalability, and storage. It can accept any type of file, from PowerPoint to streaming video, as well as providing a host of tools and services to create custom content pages, newsletters, personal zones, and the like. The platform lets users not only access content from any connected device, but also manage, share, and track content, including features like email alerts.”
Microsoft is not a main player in the cloud computing and Microsoft Azure is supposed to drive more customers to them. Anything, like this new Altair improving its search will make it more appealing.
Whitney Grace, May 27, 2015
Sponsored by ArnoldIT.com, publisher of the CyberOSINT monograph
Hijacking Semantics for Search Engine Optimization
May 26, 2015
I am just too old and cranky to get with the search engine optimization program. If a person cannot find your content, too bad. SEO has caused some of the erosion of relevance across public Web search engines.
The reason is that pages with lousy content are marketed as having other, more valuable content. The result is queries like this:

I want information about methods of digital reasoning. What I get is a company profile.
How do I get information for my specific requirement? I have to know how to work around the problems SEO puts in my face every day, over and over again.
This query works on Bing, Google, and Yandex: artificial intelligence decision procedures.

The results do not point to a small company in Tennessee, but to substantive documents from which other, pointed queries can be launched for individuals, industry associations, and methods.
When I read “Semantic Search Strategies That Work,” I became agitated. The notion of “forgetting about content” and “focusing on quality” miss the mark. Telling me to “spend time on engagement” are a collection of unrelated assertions.
The goal of semantics for SEO is to generate traffic. The search systems suck in shaped content and persist in directing people to topics that may have little or nothing to do with the information a person needs to solve his or her problem.
In short, the bastardization of semantics in the name of SEO is ensuring that some users will define the world from the point of view of marketing, not objective information.
What’s the fix?
Here’s the shocker: There is no fix. As individuals abrogate their responsibility to demand high value, on point results, schlock becomes the order of the day.
So much for clear thinking. Semantic strategies that erode relevance do not “work” from my point of view. This type of semantics thickens the cloud of unknowning.
Stephen E Arnold, May 26, 2015
Computing Power Up a Trillion Fold in 60 Years. Search Remains Unchanged.
May 25, 2015
I get the Moore’s Law thing. The question is, “Why isn’t search and content processing improving?”
Navigate to “Processing Power Has Increased by One Trillion-Fold over the Past Six Decades” and check out the infographic. There are FLOPs and examples of devices which deliver them. I focused on the technology equivalents; for example, the Tianhe 2 Supercomputer is the equivalent of 18,400 PlayStation 4s.

The problem is that search and content processing continue to bedevil users. Perhaps the limitations of the methods cannot be remediated by a bigger, faster assemblage of metal and circuits?
The improvement in graphics is evident. But allowing me to locate a single document in my multi petabyte archive continues to a challenge. I have more search systems than the average squirrel in Harrod’s Creek.
Findability is creeping along. After 60 years, the benefits of information access systems are very difficult to tie to better decisions, increased revenues, and more efficient human endeavors even when a “team of teams” approach is used.
Wake up call for the search industry. Why not deliver some substantive improvements in information access which are not tied to advertising? Please, do not use the words metadata, semantics, analytics, and intelligence in your marketing. Just deliver something that provides me with the information I require without my having to guess key words, figure out odd ball clustering, or waiting minutes or hours for a query to process.
I don’t want Hollywood graphics. I want on point information. In the last 60 years, my information access needs have not been met.
Stephen E Arnold, May 25, 2015
-

- Subscribe to Beyond Search
Feature archive
News archive

-