

More Huge Notions for Natural Language Processing
December 4, 2015
You talk to your mobile phone, right? I assume you don’t try the chat with Siri- and Cortana- type services in noisy places, in front of folks you don’t trust, and when you are in a wind storm.
I know that the idea of typing questions with subjects, verbs, adjectives, and other parts of speech is an exciting one to some people. In reality, crafting sentences is not the ideal way to interact with some search systems. If you are looking for snaps of Miley Cyrus, you don’t want to write a sentence. Just enter the word “Miley” and the Alphabet Google thing does the rest. Easy.
I read about another search related research study in “Natural Language Processing NLP Market Dynamics, Forecast, Analysis and Supply Demand 2015-2025.” I find the decade long view evidence that Excel trend functions may have helped the analysts formulate their “future insights.”
The write up about the study identifies some of the companies engaged in NLP. Here’s a sample:
IBM Corporation,
3M Co.
Hewlett-Packard Co.
Apple Inc.
Oracle Corporation
Microsoft Corporation
Dolbey Systems Inc.
SAS Institute Inc.
Netbase Solutions Inc.
Verint Systems Inc.
What no Alphabet Google? Perhaps the full study includes this outfit.
A report by MarketsAndMarkets pegged NLP as reaching $13.4 billion by 2020. I assume that the size of the market in 2025 will be larger. Since I don’t have the market size data from Future Market Insights, we will just have to wait and see what happens.
In today’s business world, projections for a decade in the future strike me as somewhat far reaching and maybe a little silly.
Who crafted this report? According to the write up:
Future Market Insights (FMI) is a premier provider of syndicated research reports, custom research reports, and consulting services. We deliver a complete packaged solution, which combines current market intelligence, statistical anecdotes, technology inputs, valuable growth insights, aerial view of the competitive framework, and future market trends.
I like the aerial view of the competitive framework thing. I wish I could do that type of work. I wonder how Verint perceives a 10 year projection when some of the firm’s intelligence works focuses on slightly shorter time horizons.
Stephen E Arnold, December 4, 2015
Stanford Offers an NLP Demo
October 8, 2015
Want to see what natural language processing does in the Stanford CoreNLP implementation. Navigate to Stanford CoreNLP. The service is free. Enter some text. The system will scan the input and display an output. NLP revealed:

What can one do with this output? Build an application around the outputs. NLP is easy. The artificial intelligence implementation is a bit of a challenge, of course, but parts of speech, named entities, and dependency parsing can be darned useful. Now mixed language inputs may be an issue. Names in different character sets could be a hurdle. I am thrilled that NLP has been visualized using the brat visualization and annotation software. Get excited, gentle reader.
Stephen E Arnold, October 8, 2015
Partridge Search for Scientific Papers and Recommendation
August 17, 2015
If you read academic papers, you may want to take a flight through Partridge. Additional details are at this link. According to the Web site: Partridge
is a web based tool used for information retrieval and filtering that makes use of Machine Learning techniques. Partridge indexes lots of academic papers and classifies them based on their content. It also indexes their content by scientific concept, providing the ability to search for phrases within specific key areas of the paper (for example, you could search for a specific outcome in the ‘conclusion’ or find out how the experiment was conducted in the ‘methodology’ section.)
The About section of the Web site explains:
Partridge is a collection of tools and web-based scripts that use artificial intelligence to run semantic analysis on large bodies of text in order to provide reader recommendations to those who query the tool. The project is named after Errol Partridge, a character from the cult Science Fiction film ‘Equilibrium’ who imparts knowledge of a cache of fictional books (banned contraband in the film) upon the protagonist, John Preston, eventually leading to his defiance of the state and the de-criminalization of literature. Partridge is my dissertation project at Aberystwyth University, United Kingdom.
Check out the system at http://paprol.org.uk.
Stephen E Arnold, August 17, 2015
Watson: The PR Blitz Continues
July 28, 2015
I know that IBM is trying to reverse 13 quarters of revenue decline. I know that most of the firm’s business units are struggling to hit their numbers. I know that IBM’s loyal employees are doing their best to belt out the IBM song “Ever Onward” in perfect harmony.

If you are not familiar with the lyrics, you can read the words at this link on the IBM Web site, which unlike the dev ops pages are still online:
EVER ONWARD — EVER ONWARD!
That’s the spirit that has brought us fame!
We’re big, but bigger we will be
We can’t fail for all can see
That to serve humanity has been our aim!
Our products now are known, in every zone,
Our reputation sparkles like a gem!
We’ve fought our way through — and new
Fields we’re sure to conquer too
For the EVER ONWARD I.B.M.
Goodness, I am tapping my foot just reading the phrase “Our reputation sparkles like a gem!”
And I don’t count the grinches who complain at EndicottAlliance.org like this:
Comment 07/27/15:
Job Title: IT Specialist
Location: Rochester MN
CustAcct: Various
BusUnit: Cloud
Message: I was forced out/bullied out through bad PBC rating/threats of PIP. I left voluntarily a few months back, rather than waiting for the inevitable layoff (since my 2014 rating was a 3, I would have probably been let go with no package). Once I got my appraisal in January, I started looking around and found another job that pays about the same as my band 10 IBM salary – and I am evaluating several other offers as we speak. I truly feel for the victims of yet another round of layoffs. But I don’t quite understand why some find it “shocking” and “unexpected” that IBM gets rid of them. Your CEO has publicly declared that many of you – especially those in the services organizations – are nothing more than “empty calories.” She went on record with those words. What do you expect? Either you organize or you better start looking for something else.
I pay attention to the “3 Lessons IBM’s Watson Can Teach Us about Our Brains’ Biases.” The write up explains:
Cognitive computing is transforming the way we work.
The Future of Enterprise and Web Search: Worrying about a Very Frail Goose
May 28, 2015
For a moment, I thought search was undergoing a renascence. But I was wrong. I noted a chart which purports to illustrate that the future is not keyword search. You can find the illustration (for now) at this Twitter location. The idea is that keyword search is less and less effective as the volume of data goes up. I don’t want to be a spoil sport, but for certain queries key words and good old Boolean may be the only way to retrieve certain types of information. Don’t believe me. Log on to your organization’s network or to Google. Now look for the telephone number of a specific person whose name you know or a tire company located in a specific city with a specific name which you know. Would you prefer to browse a directory, a word cloud, a list of suggestions? I want to zing directly to the specific fact. Yep, key word search. The old reliable.
But the chart points out that the future is composed of three “webs”: The Social Web, the Semantic Web, and the Intelligent Web. The dates for the Intelligent Web appears to be 2018 (the diagram at which I am looking is fuzzy). We are now perched half way through 2015. In 30 months, the Intelligent Web will arrive with these characteristics:
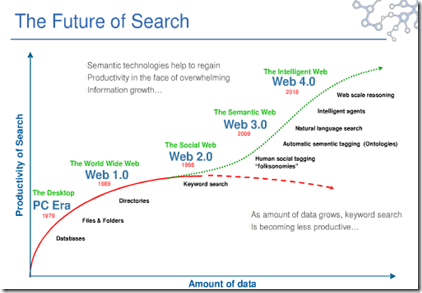
- Web scale reasoning (Don’t we have Watson? Oh, right. I forgot.)
- Intelligent agents (Why not tap Connotate? Agents ready to roll.)
- Natural language search (Yep, talk to your phone How is that working out on a noisy subway train?)
- Semantics. (Embrace the OWL. Now.)
Now these benchmarks will arrive in the next 30 months, which implies a gradual emergence of Web 4.0.
The hitch in the git along, like most futuristic predictions about information access, is that reality behaves in some unpredictable ways. The assumption behind this graph is “Semantic technology help to regain productivity in the face of overwhelming information growth.”
Kelsen Enters Legal Search Field
February 23, 2015
A new natural-language search platform out of Berlin, Kelsen, delivers software-as-a-service to law firms. Basic Thinking discusses “The Wolfram Alpha of the Legal Industry.” Writer Jürgen Kroder interviewed Kelsen co-founder Veronica Pratzka. She explains what makes her company’s search service different (quote auto-translated from the original German):
“Kelsen is generated based on pre-existing legal cases not a search engine, but a self-learning algorithm that automatically answers. 70-80 percent of the global online data are very unstructured. Search engines look for keywords and only. Google has many answers, but you have to look for them yourself thousands of search results together and hope that you just entered the correct keywords. Kelsen, however, is rather a free online lawyer who understands natural language practitioner trained in all areas of law, works 24/7 and is always up-to-date….
“First Kelsen understands natural language compared to Google! That is, even with the entry of long sentences and questions, not just keywords, Kelsen is suitable answers. Moreover, Kelsen searches ‘only’ relevant legal data sources and provides the user with a choice of right answers ready, he can also evaluate.’
“One could easily Kelsen effusive as ‘the Wolfram Alpha the legal industry,’ respectively. We focus on Kelsen with legal data structure and analyze them in order to eventually make available. From this structuring and visualization of legal data not only seeking advice and lawyers can benefit, but also legislators, courts and research institutions.”
Pratzka notes that her company received boosts from both the Microsoft Accelerator and the IBM Entrepreneur startup support programs. Kelsen expects to turn a profit on the business-to-consumer side through premium memberships. In business-to-business, though, the company plans to excel by simply outperforming the competition. Pratzka seems very confident. Will the service garner the attention she and her team expect?
Cynthia Murrell, February 23, 2015
Sponsored by ArnoldIT.com, developer of Augmentext
Facebook Gains Natural Language Capacity with Via AI Acquisition
February 11, 2015
Facebook is making inroads into the natural language space, we learn from “Facebook Buys Wit.ai, Adds Natural Language Knowhow” at ZDNet. Reporter Larry Dignan tells us the social-media giant gained more than 6,000 developers in the deal with the startup, who has created an open-source natural language platform with an eye to the “Internet of Things.” He writes:
“Wit.ai is an early stage startup that in October raised $3 million in seed financing with Andreessen Horowitz as the lead investor. Wit.ai aims to create a natural language platform that’s open sourced and distributed. Terms of the deal weren’t disclosed, but indicates what Facebook is thinking. As the social network is increasingly mobile, it will need natural language algorithms and knowhow to add key features. Rival Google has built in a bevy of natural language tools into Android and Apple has its Siri personal assistant.”
Though the Wit.ai platform is free for open data projects, it earns its keep through commercial instances and queries-per-day charges. Wit.ai launched in October 2013, and is headquartered in Palo Alto, California.
Cynthia Murrell, February 11, 2015
Sponsored by ArnoldIT.com, developer of Augmentext
Watson Goes Open Source…Not Really
January 2, 2015
IBM’s Watson is becoming a new natural language processing analytical tool. It is doubtful that IBM will ever expose Watson’s guts to the open source community, but parts of its internal software organs were designed around existing open source work. Also do not doubt the open source community’s resourcefulness. The community is already building their own Watson-like entities. InfoWorld lists these open source projects on “Watson Wannabes: 4 Open Source Projects For Machine Intelligence.”
DARPA DeepDive is an automated system for classifying unstructured data that emulates Watosn’s decision-making process with human guidance. Christopher Re of the University of Wisconsin, developed it.
Apache Unstructured Information Management (UIMA) is a program that was actually used to program Watson. It is a standard for performing analysis on textual content. IBM UIMA architecture is available via the open source Apache Foundation. It is not a complete machine learning system and only offers the minimum code to build on.
OpenCog’s goal is to build a platform for developers to build and share artificial intelligence programs. OpenCog wants to help create intelligent systems that have humanlike world understanding rather than being focused on one specific area. OpenCog is already using NLP, making it a practical solution similar to Watson.
The Open Advancement of Question Answering Systems (OAQA) is more akin to Watson than the other three. It offers an advanced question and answering system-using NLP. IBM and Carnegie Mellon University started it. OAQA is only a toolkit, not a downloadable solution.
“The one major drawback to each project, as you can guess, is that they’re not offered in nearly as refined or polished a package as Watson. Whereas Watson is designed to be used immediately in a business context, these are raw toolkits that require heavy lifting. Plus, Watson’s services have already been pre-trained with a curated body of real-world data. With these systems, you’ll have to supply the data sources, which may prove to be a far bigger project than the programming itself.”
All too true.
Whitney Grace, January 02, 2015
Sponsored by ArnoldIT.com, developer of Augmentext
Garbling the Natural Language Processors
December 30, 2014
Natural language processing is becoming a popular analytical tool as well as a quicker way for search and customer support. Dragon Nuance is at the tip of everyone’s tongue when NLP enters a conversation, but there are other products with their own benefits. Code Project recently reviewed three of NLP in, ”A Review Of Three Natural Language Processors, AlchemyAPI, OpenCalais, And Semantria.”
Rather than sticking readers with plain product reviews, Code Project explains what NLP is used for and how it accomplishes it. While NLP is used for vocal commands, it can do many other things: improve SEO, knowledge management, text mining, text analytics, content visualization and monetization, decision support, automatic classification, and regulatory compliance. NLP extracts entities aka proper nouns from content, then classifies, tags, and provides a sentiment score to give each entity a meaning.
In layman’s terms:
“…the primary purpose of an NLP is to extract the nouns, determine their types, and provide some “scoring” (relevance or sentiment) of the entity within the text. Using relevance, one can supposedly filter out entities to those that are most relevant in the document. Using sentiment analysis, one can determine the overall sentiment of an entity in the document, useful for determining the “tone” of the document with regards to an entity — for example, is the entity “sovereign debt” described negatively, neutrally, or positively in the document?”
NLP categorizes the human element in content. Its usefulness will become more apparent in future years, especially as people rely more and more on electronic devices for communication, consumerism, and interaction.
Whitney Grace, December 30, 2014
Sponsored by ArnoldIT.com, developer of Augmentext
A Plan for Achieving ROI via Text Analytics
December 6, 2014
ROI is the end goal for many big data and enterprise related projects and it is refreshing to see some information published in regards to if companies achieve it like we recently saw in a Smart Data Collective article, “Text Analytics, Big Data and the Keys to ROI.” According to a study released last year (further discussed in“Text/Content Analytics 2011: User Perspectives on Solutions and Providers”) the reason many businesses do not get positive returns has to do with the planning phase. Many report that they did not start with a clear plan to get there.
The author shares with us an example from his full-time work in text analytics. One of his clients that was focused on sifting through masses of social media data and data from government applications looking for suspicious activity needed a solution for a text-heavy application. The author responded by suggesting a selective cross-lingual process, one which worked with the text in its native language, and only on the text that was relevant to the topic of interest.
The following happened after the author’s suggestion:
Although he seemed to appreciate the logic of my suggestions and the quality benefits of avoiding translation, he just didn’t want to deal with a new approach. He asked to just translate everything and analyze later – as many people do. But I felt strongly that he’d be spending more and getting weaker results. So, I gave him two quotes. One for translating everything first and analyzing later – his way, and one for the cross-lingual approach that I recommended. When he saw that his own plan was going to cost over a million dollars more, he quickly became very open minded about exploring a new approach.
It sounds like the author could have suggested a number of similar semantic processing solutions. For example, Cogito Intelligence API enhances the ability to decipher meaning and insights from a multitude of content sources including social media and unstructured corporate data. The point is that ROI is out there and there are innovative companies like Expert System and beyond enabling it.
Megan Feil, December 6, 2014
-

- Subscribe to Beyond Search
Feature archive
News archive

-