

Medical Tagging: No Slam Dunk
May 28, 2015
The taxonomy/ontology/indexing professionals have a challenge. I am not sure many of the companies pitching better, faster, cheaper—no, strike that—better automated indexing of medical information will become too vocal about a flubbed layup.
Navigate to “Coalition for ICD 10 Responds to AMA.” It seems as if indexing what is a more closed corpus is a sticky ball of goo. The issue is the coding scheme required by everyone who wants to get reimbursed and retain certification.
The write up quotes a person who is supposed to be in the know:
“We’d see 13,000 diagnosis codes balloon into 68,000 – a five-fold increase.” [Dr. Robert Wah of the AMA]
The idea is that the controlled terms are becoming obese, weighty, and frankly sufficiently numerous to require legions of subject matter experts and software a heck of a lot more functional than Watson to apply “correctly.” I will let you select the definition of “correctly” which matches your viewpoint from this list of Beyond Search possibilities:
- Health care administrators: Get paid
- Physicians: Avoid scrutiny from any entity or boss
- Insurance companies: Pay the least possible amount yet have an opportunity for machine assisted claim identification for subrogation
- Patients: Oh, I forgot. The patients are of lesser importance.
You, gentle reader, are free to insert your own definition.
I circled this statement as mildly interesting:
As to whether ICD-10 will improve care, it would seem obvious that more precise data should lead to better identification of potential quality problems and assessment of provider performance. There are multiple provisions in current law that alter Medicare payments for providers with excess patient complications. Unfortunately, the ICD-9 codes available to identify complications are woefully inadequate. If a patient experiences a complication from a graft or device, there is no way to specify the type of graft or device nor the kind of problem that occurred. How can we as a nation assess hospital outcomes, pay fairly, ensure accurate performance reports, and embrace value-based care if our coded data doesn’t provide such basic information? Doesn’t the public have a right to know this kind of information?
Maybe. In my opinion, the public may rank below patients in the priorities of some health care delivery outfits, professionals, and advisers.
Indexing is necessary. Are the codes the ones needed? In an automatic indexing system, what’s more important: [a] Generating revenue for the vendor; [b] Reducing costs to the customer of the automated tagging system; [c] Making the indexing look okay and good enough?
Stephen E Arnold, May 28, 2015
The Future of Enterprise and Web Search: Worrying about a Very Frail Goose
May 28, 2015
For a moment, I thought search was undergoing a renascence. But I was wrong. I noted a chart which purports to illustrate that the future is not keyword search. You can find the illustration (for now) at this Twitter location. The idea is that keyword search is less and less effective as the volume of data goes up. I don’t want to be a spoil sport, but for certain queries key words and good old Boolean may be the only way to retrieve certain types of information. Don’t believe me. Log on to your organization’s network or to Google. Now look for the telephone number of a specific person whose name you know or a tire company located in a specific city with a specific name which you know. Would you prefer to browse a directory, a word cloud, a list of suggestions? I want to zing directly to the specific fact. Yep, key word search. The old reliable.
But the chart points out that the future is composed of three “webs”: The Social Web, the Semantic Web, and the Intelligent Web. The dates for the Intelligent Web appears to be 2018 (the diagram at which I am looking is fuzzy). We are now perched half way through 2015. In 30 months, the Intelligent Web will arrive with these characteristics:
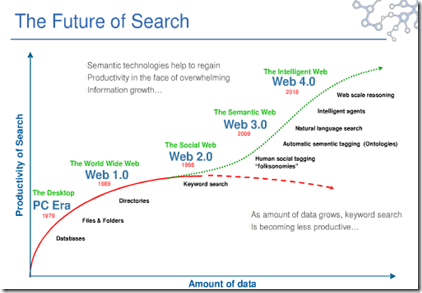
- Web scale reasoning (Don’t we have Watson? Oh, right. I forgot.)
- Intelligent agents (Why not tap Connotate? Agents ready to roll.)
- Natural language search (Yep, talk to your phone How is that working out on a noisy subway train?)
- Semantics. (Embrace the OWL. Now.)
Now these benchmarks will arrive in the next 30 months, which implies a gradual emergence of Web 4.0.
The hitch in the git along, like most futuristic predictions about information access, is that reality behaves in some unpredictable ways. The assumption behind this graph is “Semantic technology help to regain productivity in the face of overwhelming information growth.”
Data Darkness
May 28, 2015
According to Datameer, organizations do not use a large chunk of their data and it is commonly referred to “dark data.” “Shine Light On Dark Data” explains that organizations are trying to dig out the dark data and use it for business intelligence or in more recent terms big data. Dark data is created from back end business processes as well as from regular business activities. It is usually stored on storage silo in a closet and only kept for compliance audits.
Dark data has a lot of hidden potential:
“Research firm IDC estimates that 90 percent of digital data is dark. This dark data may come in the form of machine or sensor logs that when analyzed help predict vacated real estate or customer time zones that may help businesses pinpoint when customers in a specific region prefer to engage with brands. While the value of these insights are very significant, setting foot into the world of dark data that is unstructured, untagged and untapped is daunting for both IT and business users.”
The article suggests making a plan to harness the dark data and it does not offer much in the way of approaching a project other than making it specifically for dark data, such as identifying sources, use Hadoop to mine it, and tests results against other data sets.
This article is really a puff piece highlighting dark data without going into much detail about it. They are forgetting that the biggest movement in IT from the past three years: big data!
Whitney Grace, May 28, 2015
Sponsored by ArnoldIT.com, publisher of the CyberOSINT monograph
SharePoint Is Back and Yammer Is Left Behind
May 28, 2015
Many old things become trend and new again, and even that holds true with software, at least in principle. The old functions of SharePoint are withstanding the test of time, and the trendy new buzzwords that Microsoft worked so hard to push these last few years (cloud, social, collaborative) are fading out. Of course, some of it has to do with perception, but it does seem that Microsoft is harkening back to what the tried and true longtime users want. Read more in the CMS Wire article, “SharePoint is Back, Yammer… Not So Much.”
The article sums up the last few years:
“But these last few years, Microsoft seemingly didn’t want to talk about SharePoint. It wanted to talk about Office 365, the cloud, collaboration, social, mobile devices and perpetual monthly licensing models. Yet no one appears to have told many of the big traditional SharePoint customers of these shifts. These people are still running SharePoint 2007, 2010 and 2013 happily in-house and have no plans to change that for many years.”
So it seems that with the returned focus to on-premises SharePoint, users are pleased in theory. However, it remains to be seen how satisfying SharePoint Server 2016 will be in reality. To stay tuned to the latest reviews and feedback, keep an eye on ArnoldIT.com and his dedicated SharePoint feed. Stephen E. Arnold is a longtime leader in search with an interest in SharePoint. His reporting will shed a light on the realities of user experience once SharePoint Server 2016 becomes available.
Emily Rae Aldridge, May 28, 2015
Sponsored by ArnoldIT.com, publisher of the CyberOSINT monograph
Facebook Offers Ad Revenue for Streamlined News Experience
May 28, 2015
Facebook is offering an interesting carrot to certain publishers, like the New York Times and National Geographic, in the interest of streamlining the Facebook use-experience; CNet reports, “Facebook Aims to Host Full Stories, Will Let Publishers Keep Ad Revenue, Says Report.” Of course, the project has to have a hip yet obvious name: “Instant Articles” is reportedly the feature’s title. Writer Nate Ralph cites an article in the Wall Street Journal as he tells us:
“The move is aimed at improving the user experience on the world’s largest social network. Today, clicking on a news story on Facebook directs you to the news publication’s website, adding additional time as that site loads and — more importantly for Facebook — taking users away from the social network. With Instant Articles, all the content would load more or less immediately, keeping users engaged on Facebook’s site. The upside for publishers would be increased money from ads, the Journal said. With one of the versions of Instant Articles that’s being considered, publishers would keep all the revenue from associated ads that they sold. If Facebook sold the ads, however, the social network would keep 30 percent of the revenue.”
Apparently, some news publishers have been “wary” of becoming tightly integrated into Facebook, perhaps fearing a lack of control over their content and image. The write-up goes on to note that Facebook has been testing a feature that lets users prioritize updates from different sources. How many other ways to capture and hold our attention does the social media giant have up its sleeve?
Cynthia Murrell, May 28, 2015
Sponsored by ArnoldIT.com, publisher of the CyberOSINT monograph
Need Free Images and Clipart
May 27, 2015
One of my two or three readers called my attention to this listing: “65+ Sites to Find Awe Inspiring Public Domain Images and Clip Art for Your Blog + Social Media Posts for Free.” The write up provides basic information about the image resources. Update your public domain images, gentle readers.
Stephen E Arnold, May 27, 2015
From PowerPoint to the Open Office: The Washington Post Covers the News That Really Matters.
May 27, 2015
Here’s another gem from Jeff Bezos’ newspaper. I noted this item in my Overflight report this morning: “Google Got It Wrong. The Open-Office Trend Is Destroying the Workplace.” The premise of the write up, it seems to me, is that Google is responsible for offices without walls. Offices without walls are detrimental to work processes which require walls. Therefore, Google is wrong again.
Google, how could a math club inspired company destroy the workplace. I thought you folks just eroded relevance in search results, invented Loon balloons, and squabbled about private jet décor. Toss in the black swan who dallied with drugs and a disaffected wizard with several versions of his name. Here I am. Off base again.
According to the write up:
While employees feel like they’re part of a laid-back, innovative enterprise, the environment ultimately damages workers’ attention spans, productivity, creative thinking, and satisfaction. Furthermore, a sense of privacy boosts job performance, while the opposite can cause feelings of helplessness. In addition to the distractions, my colleagues and I have been more vulnerable to illness. Last flu season took down a succession of my co-workers like dominoes.
Oh, my goodness. My feeling of helplessness is Google’s fault. My co-workers and I will face rampant disease.
But, wait, what’s the fix? Well, do away with the office entirely. Yes, telework. When I was doing some odd jobs in Washington, DC, I noticed that some government workers “teleworked” one day a week. This meant that the consultants who were the primary driver of doing stuff we somewhat hampered. Imagine the productivity if no one converged on a common facility, interacted in direct face to face ways, and obtained a smidgen of identity from entering a giant building with a wonderful on premises cafeteria.
What’s fascinating about this write up? First, it is not news. Second, it blames Google for trend in which Google played much, if any, leadership role. Third, the “fix” is great for the rare individual who thrives in an environment without the old fashioned Tayloresque management methods.
Google, did you grasp the extent of your influence in the no walls office approach to work? Probably not. Was the destruction of my nifty corner office overlooking a duck pond in San Mateo an unintended consequence of linking relevance to paid advertising? I never liked that office. I appropriated an interior office without windows, moving the copy machine and assorted office equipment to the office with a view of the ducks. Go figure.
Oh, Washington Post, why not cover the rising tension in the South China Sea an issue with a touch more substance?
Stephen E Arnold, May 27, 2015
Excitement Ahead: Google and Oracle Get Another Jolt of Java
May 27, 2015
Let’s assume that Fortune is spot on. Let’s assume that Department of Justice lawyers have figured out the issues related to application programming interfaces. Let’s assume that copyright is the operative claim. Let’s assume that no one writes, “Assume. Ass-u-me.”
Navigate to “Let Oracle Own APIs, Justice Dept Tells Top Court in Surprise Filing.” Surprises are a good thing, right?
The all-time-champ of business is Fortune. I circled this passage:
The issue before the court is when, if at all, API’s can be protected by copyright. The outcome has serious repercussions not just for Google, but the entire software industry, since API’s act as a sort of lingua franca that allow different computer programs to deliver instructions to each other. In the case of Oracle and Google, the dispute turns on the search giant’s use of certain Java API’s for its Android software. Java is a programming language that was developed by Oracle’s predecessor, Sun Microsystems, and is widely used by software developers.
Quick question? When Java was in the Google mix, how many former Sun engineers were employed at Google? How many were working on the caffeinated project?
I then noted:
U.S. District Judge William Alsup, a respected Silicon Valley judge, initially sided with Google in 2012 after teaching himself Java for the trial. He found that the API’s were functional, and fell on the wrong side of copyright law’s “idea/expression dichotomy” and merger doctrine – these are rules that prevents copyright law from becoming too broad, and covering everyday things like menus and simple instructions.
Even the dinosaur bones on the Google campus smiled.
But then the legal worm did its thing:
Last year, however, the U.S. Federal Circuit appeals court overturned that finding, and likened the Java API’s to Charles Dickens and other literary works.
And now another twitch:
In its filing on Tuesday, the Obama Administration’s top lawyer sided with the Federal Circuit. It also repeated that court’s argument that the case should be decided by determining if Google had a “fair use” right to use the API’s
What’s next?
You know the answer: More lawyering.
Google now has an opportunity to spend more quality time with various officials in Washington, DC. The stakes are high because a couple of big companies are about to help explain copyright. Publishers, like Fortune, should be really excited.
Stephen E Arnold, May 27, 2015
Altiar And dtSearch Combine
May 27, 2015
Sometimes when items are combine they create something even better, such as Oreos and peanut butter, Disney and Marvel, and Netflix and original series. EContentMag alerted us that a new team-up is underway between two well known companies. The press release title says it all, “Altiar Cloud-Based ECM Platform Is Embedding The dtSearch Engine.” Altair is an enterprise content management platform that has been specifically used by Microsoft Azure. The popular dtSearch platform has been searching through terabytes since 1991 and is referred to as a powerful search tool. Embedding dtSearch into the Altiar core will make it a more powerful ECM.
Altiar is a popular ECM and can only be improved by dtSearch:
“A cloud-based service, Altiar includes rapid setup, scalability, and storage. It can accept any type of file, from PowerPoint to streaming video, as well as providing a host of tools and services to create custom content pages, newsletters, personal zones, and the like. The platform lets users not only access content from any connected device, but also manage, share, and track content, including features like email alerts.”
Microsoft is not a main player in the cloud computing and Microsoft Azure is supposed to drive more customers to them. Anything, like this new Altair improving its search will make it more appealing.
Whitney Grace, May 27, 2015
Sponsored by ArnoldIT.com, publisher of the CyberOSINT monograph
Free Book from OpenText on Business in the Digital Age
May 27, 2015
This is interesting. OpenText advertises their free, downloadable book in a post titled, “Transform Your Business for a Digital-First World.” Our question is whether OpenText can transform their own business; it seems their financial results have been flat and generally drifting down of late. I suppose this is a do-as-we-say-not-as-we-do situation.
The book may be worth looking into, though, especially since it passes along words of wisdom from leaders within multiple organizations. The description states:
“Digital technology is changing the rules of business with the promise of increased opportunity and innovation. The very nature of business is more fluid, social, global, accelerated, risky, and competitive. By 2020, profitable organizations will use digital channels to discover new customers, enter new markets and tap new streams of revenue. Those that don’t make the shift could fall to the wayside. In Digital: Disrupt or Die, a multi-year blueprint for success in 2020, OpenText CEO Mark Barrenechea and Chairman of the Board Tom Jenkins explore the relationship between products, services and Enterprise Information Management (EIM).”
Launched in 1991, OpenText offers tools for enterprise information management, business process management, and customer experience management. Based in Waterloo, Ontario, the company maintains offices around the world.
Cynthia Murrell, May 27, 2015
Sponsored by ArnoldIT.com, publisher of the CyberOSINT monograph
-

- Subscribe to Beyond Search
Feature archive
News archive

-