

Speeding Up Search: The Challenge of Multiple Bottlenecks
March 29, 2018
I read “Search at Scale Shows ~30,000X Speed Up.” I have been down this asphalt road before, many times in fact. The problem with search and retrieval is that numerous bottlenecks exist; for example, dealing with exceptions (content which the content processing system cannot manipulate).
Those who want relevant information or those who prefer superficial descriptions of search speed focus on a nice, easy-to-grasp metric; for example, how quickly do results display.
May I suggest you read the source document, work through the rat’s nest of acronyms, and swing your mental machete against the “metrics” in the write up?
Once you have taken these necessary steps, consider this statement from the write up:
These results suggest that we could use the high-quality matches of the RWMD to query — in sub-second time — at least 100 million documents using only a modest computational infrastructure.

The path to responsive search and retrieval is littered with multiple speed bumps. Hit any one when going to fast can break the search low rider.
I wish to list some of the speed bumps which the write does not adequately address or, in some cases, acknowledge:
- Content flows are often in the terabit or petabit range for certain filtering and query operations., One hundred million won’t ring the bell.
- This is the transform in ETL operations. Normalizing content takes some time, particularly when the historical on disc content from multiple outputs and real-time flows from systems ranging from Cisco Systems intercept devices are large. Please, think in terms of gigabytes per second and petabytes of archived data parked on servers in some countries’ government storage systems.
- Populating an index structure with new items also consumes time. If an object is not in an index of some sort, it is tough to find.
- Shaping the data set over time. Content has a weird property. It evolves. Lowly chat messages can contain a wide range of objects. Jump to today’s big light bulb which illuminates some blockchains’ ability house executables, videos, off color images, etc.
- Because IBM inevitably drags Watson to the party, keep in mind that Watson still requires humans to perform gorilla style grooming before it’s show time at the circus. Questions have to be considered. Content sources selected. The training wheels bolted to the bus. Then trials have to be launched. What good is a system which returns off point answers?
I think you get the idea.
Crime Prediction: Not a New Intelligence Analysis Function
March 16, 2018
We noted “New Orleans Ends Its Palantir Predictive Policing Program.” The interest in this Palantir Technologies’ project surprised us from our log cabin with a view of the mine drainage run off pond. The predictive angle is neither new nor particularly stealthy. Many years ago when I worked for one of the outfits developing intelligence analysis systems, the “predictive” function was a routine function.
Here’s how it works:
- Identify an entity of interest (person, event, organization, etc.)
- Search for other items including the entity
- Generate near matches. (We called this “fuzzification” because we wanted hits which were “near” the entity in which we had an interest. Plus, the process worked reasonably well in reverse too.)
- Punch the analyze function.
Once one repeats the process several times, the system dutifully generates reports which make it easy to spot:
- Exact matches; for example, a “name” has a telephone number and a dossier
- Close matches; for example, a partial name or organization is associated with the telephone number of the identity
- Predicted matches; for example, based on available “knowns”, the system can generate a list of highly likely matches.
The particular systems with which I am familiar allow the analyst, investigator, or intelligence professional to explore the relationships among these pieces of information. Timeline functions make it trivial to plot when events took place and retrieve from the analytics module highly likely locations for future actions. If an “organization” held a meeting with several “entities” at a particular location, the geographic component can plot the actual meetings and highlight suggestions for future meetings. In short, prediction functions work in a manner similar to Excel’s filling in items in a number series.

What would you predict as a “hot spot” based on this map? The red areas, the yellow areas, the orange areas, or the areas without an overlay? Prediction is facilitated with some outputs from intelligence analysis software. (Source: Palantir via Google Image search)
The New York Times Wants to Change Your Google Habit
March 1, 2018
Sunday is a slightly less crazy day. I took time to scan “The Case Against Google.” I had the dead tree edition of the New York Times Magazine for February 25, 2018. You may be able to access this remarkable hybridization of Harvard MBA think, DNA engineered to stick pins in Google, and good old establishment journalism toasted at Yale University.

The author is a wildly successful author. Charles Duhigg loves his family, makes time for his children, writes advice books, and immerses himself in a single project at a time. When he comes up for air, he breathes deeply of Google outputs in order to obtain information. If the Google fails, he picks up the phone. I assume those whom he calls answer the ring tone. I find that most people do not answer their phones, but that’s another habit which may require analysis.
I worked through the write up. I noted three things straight away.
First, the timeline structure of the story is logical. However, leaving it up to me to figure out which date matched which egregious Google action was annoying. Fortunately, after writing The Google Legacy, Google Version 2.0, and Google: The Digital Gutenberg, I had the general timeline in mind. Other readers may not.
Second, the statement early in the write up reveals the drift of the essay’s argument. The best selling author of The Power of Habit writes:
Within computer science, this kind of algorithmic alchemy is sometimes known as vertical search, and it’s notoriously hard to master. Even Google, with its thousands of Ph.D.s, gets spooked by vertical-search problems.
I am not into arguments about horizontal and vertical search. I ran around that mulberry tree with a number of companies, including a couple of New York investment banks. Been there. Done that. There are differences in how the components of a findability solution operate, but the basic plumbing is similar. One must not confuse search with the specific technology employed to deliver a particular type of output. Want to argue? First, read The New Landscape of Search, published by Pandia before the outfit shut down. Then, send me an email with your argument.
Third, cherry picking from Google’s statements makes it possible to paint a somewhat negative picture of the great and much loved Google. With more than 60,000 employees, many blogs, many public presentations, oodles of YouTube videos, and a library full of technical papers and patents, the Google folks say a lot. The problem is that finding a quote to support almost any statement is not hard; it just takes persistence. Here’s an example:
We absolutely do not make changes 5to our search algorithm to disadvantage competitors.
Governance: Now That Is a Management Touchstone for MBA Experts
February 27, 2018
I read “Unlocking the Power of Today’s Big Data through Governance.” Quite a lab grown meat wiener that “unlocking,” “power,” “Big Data,” and “governance” statement is that headline. Yep, IDG, the outfit which cannot govern its own agreements with the people the firm pays to make the IDG experts so darned smart. (For the back-story, check out this snapshot of governance in action.)
.jpg)
What’s the write up with the magical word governance about?
Instead of defining “governance,” I learn what governance is not; to wit:
Data governance isn’t about creating a veil of secrecy around data
I have zero idea what this means. Back to the word “governance.” Google and Wikipedia define the word in this way:
Governance is all of the processes of governing, whether undertaken by a government, market or network, whether over a family, tribe, formal or informal organization or territory and whether through the laws, norms, power or language of an organized society.
Okay, governing. What’s governing mean? Back to the GOOG. Here’s one definition which seems germane to MBA speakers:
control, influence, or regulate (a person, action, or course of events).
The essay drags out the chestnuts about lots of information. Okay, I think I understand because Big Data has been touted for many years. Now, mercifully I assert, the drums are beating out the rhythm of “artificial intelligence” and its handmaiden “algos,” the terrific abbreviation some of the marketing jazzed engineers have coined. Right, algos, bro.
What’s the control angle for Big Data? The answer is that “data governance” will deal with:
- Shoddy data
- Incomplete data
- Off point data
- Made up data
- Incorrect data
Presumably these thorny issues will yield to a manager who knows the ins and outs of governance. I suppose there are many experts in governance; for example, the fine folks who have tamed content chaos with their “governance” of content management systems or the archiving mavens who have figured out what to do with tweets at the Library of Congress. (The answer is to not archive tweets. There you go. Governance in action.)
The article suggests a “definitive data governance program.” Right. If one cannot deal with backfiles, changes to the data in the archives, and the new flows of data—how does one do the “definitive governance program” thing? The answer is, “Generate MBA baloney and toss around buzzwords.” Check out the list of tasks which, in my experience, are difficult to accomplish when resources are available and the organization has a can-do attitude:
- Document data and show its lineage.
- Set appropriate policies, and enforce them.
- Address roles and responsibilities of everyone who touches that data, encouraging collaboration across the organization.
These types of tasks are the life blood of consultants who purport to have the ability to deliver the near impossible.
What happens if we apply the guidelines in the Governance article to the data sets listed in “Big Data And AI: 30 Amazing (And Free) Public Data Sources For 2018.” In my experience, the cost of normalizing the data is likely to be out of reach for most organizations. Once these data have been put in a form that permits machine-based quality checks, the organization has to figure out what questions the data can answer with a reasonable level of confidence. Getting over these hurdles then raises the question, “Are these data up to date?” And, if the data are stale, “How do we update the information?” There are, of course, other questions, but the flag waving about governance operates at an Ivory Tower level. Dealing with data takes place with one’s knees on the ground and one’s hands in the dirt. If the public data sources are not pulling the hay wagon, what’s the time, cost, and complexity of obtaining original data sets, validating them, and whipping them into shape for use by an MBA?
You know the answer: “This is not going to happen.”
Here’s a paragraph which I circled in Oscar Mayer wiener pink:
One of the more significant, and exciting, changes in data governance has been the shift in focus to business users. Historically, data has been a technical issue owned by IT and locked within the organization by specific functions and silos. But if data is truly going to be an asset, everyday users—those who need to apply the data in different contexts—must have access and control over it and trust the data. As such, data governance is transforming from a technical tool to a business application. And chief data officers (CDOs) are starting to see the technologies behind data governance as their critical operating environment, in much the same way SAP serves CFOs, and Salesforce supports CROs. It is rare to find an opportunity to build a new system of record for a market.
Let’s look at this low calorie morsel and consider some of its constituent elements. (Have you ever seen wieners being manufactured? Fill in that gap in your education if you have not had the first hand learning experience.)
First, business users want to see a pretty dashboard, click on something that looks interesting in a visualization, and have an answer delivered. Most of the business people I know struggle to understand if the data in their system is accurate and limited expertise to understand the mathematical processes which churn away to display an “answer.”
The reference to SAP is fascinating, but I think of IBM-type systems as somewhat out of step with the more sophisticated tools available to deal with certain data problems. In short, SAP is an artifact of an earlier era, and its lessons, even when understood, have been inadequate in the era of real time data analysis.
Let me be clear: Data governance is a management malarkey. Look closely at organizations which are successful. Peer inside their data environments. When I have looked, I have seen clever solutions to specific problems. The cleverness can create its own set of challenges.
The difference between a Google and a Qwant, a LookingGlass Cyber and IBM i2, or Amazon and Wal-Mart is not Big Data. It is not the textbook definition of “governance.” Success has more to do with effective problem solving on a set of data required by a task. Google sells ads and deals with Big Data to achieve its revenue goals. LookingGlass addresses chat information for a specific case. Amazon recommends products in order to sell more products.
Experts who invoke governance on a broad scale as a management solution are disconnected from the discipline required to identify a problem and deal with data required to solve that problem.
Few organizations can do this with their “content management systems”, their “business intelligence systems,” or their “product information systems.” Why? Talking about a problem is not solving a problem.
Governance is wishful thinking and not something that is delivered by a consultant. Governance is an emergent characteristic of successful problem solving. Governance is not paint; it is not delivered by an MBA and a PowerPoint; it is not a core competency of jargon.
In Harrod’s Creek, governance is getting chicken to the stores in the UK. Whoops. That management governance is not working. So much in modern business does not work very well.
Stephen E Arnold, February 27, 2018
The Next Stage in Information Warfare: Quantum Weaponization
February 20, 2018
We have been tracking the emergence of peer to peer technologies. Innovators have been working to deal with the emergence of next generation mainframe computing architectures like those available from Amazon, Facebook, and Google. The idea is that these new mainframes have popped up a level and are using software to integrate individual computing devices into larger constructs which are command and control systems.
Examples of the innovations can be found in the digital currency sector with the emergence of IOTA like systems. There are other innovation nodes as well; for example, discussed in online publications like Medium, technical fora, and implemented by outfits like Anonymous Portugal.
One of the popular methods used by my former colleagues at Halliburton Nuclear Utility Services was to look at a particular problem. The nuclear engineers would then try to fit the problem into a meta-schema. The idea was that a particular problem in some nuclear applications could not be tackled directly. A nuclear engineer tried to find ways to address the problem without poking the specific issue because once probed, the problem morphed. Hence, the meta-method was more useful.
Here’s a diagram which I think shows one facet of the approach:
![]()
The idea is to come at a problem in different way. Edward de Bono called it “lateral thinking.” For me, the idea is to pop outside a problem, not in two dimensions, but three or four if time plays a part. Maybe “meta-thining” or “meta-analysis”?
What’s ahead for “the Internet” is what I conceptualize as urban warfare in the online world.
Non-traditional approaches to security, messaging, and data routing will combine to create a computing environment that’s different. Smart software will allow nodes or devices to make local decisions, and then that same smart software will use random message pathways to accomplish a task like routing. The difference between today’s concentrated Internet will be similar to Caesar’s Third Legion engaging in urban warfare. Caesar’s troops have swords; the urban fighters have modern weapons. Not even mighty Caesar can deal with the mismatch in technology.
Several observations:
- More robust encryption methods will make timely sense making of intercepted data very, very difficult
- Smart software will create polymorphic solutions to what are today difficult problems
- The diffusion of intelligent computing devices (including light bulbs) generate data volumes which will be difficult to process for meaningful signals by components not embedded in the polymorphic fabric. (Yes, this means law enforcement and intelligence entities).
- The era of the “old” Internet is ending, but the shift is underway. The movement is from a pointed stick to a cellular structure filled with adaptable proteins. The granularity and the “intelligence” of the tiny bits will be fascinating to observe.
In one sense, the uncertainty inherent in many phenomena will migrate into online.
The shift is not inherently “bad.” New opportunities will arise. The shift will have significant impacts, however. Just as the constructs of the industrial age have been reshaped by the “old” Internet, the new polymorphic, quantum-ized Internet will usher in some interesting changes.
Is digital Ebola replicating now, gentle reader?
Stephen E Arnold, February 20, 2018
Big Data, Search, and Artificial Intelligence: Quite a Mash Up
January 29, 2018
I read a consultant-technology mash up marketing essay. The write up is “Big Data and Search: The Time for Artificial Intelligence Is Now.” The write up is mostly jargon. I wonder if the engineer driving the word processing train pushed the wrong button.

Here are the “keywords” I noted in the write up:
Analytics
Artificial intelligence
Big Data
Blockchain
Business action and business use cases
Chatbots
Cognitive (presumably not the IBM which maybe doesn’t work as advertised)
Consumer services
Customer / citizen facing (some government speak too)
Digital assistants
False or biased results (yes, fake news)
Keywords
Machine learning
Natural language processing
Platforms
Real time results
Resources
SQL databases
Search
Transparency
Trust
Video
Online: Welcome to 1981 and 2018
January 8, 2018
I have been thinking about online. I met with a long-time friend and owner of a consumer-centric Web site. For many years (since 1993, in fact), the site grew and generated a solid stream of revenue.
At lunch, the site owner told me that in the last three years, the revenue was falling. As I listened to this sharp businessperson, I realized that his site had shifted from ads which he and his partners sold to ads provided by automated systems.
From direct control to the ease of automated ad provision created the current predicament: Falling revenue. At the same time, the mechanisms for selling ads directly evolved as well. The shift from many industry events to a handful of large business sector conferences took place. There were more potential customers at these shows, but the attendance shifted from hands-on marketers to people who wanted to make use of online automated sales and marketing systems began to dominate.

He said, “In the good old days of 1996, I could go to a trade show and meet people who made advertising and marketing decisions based on experience with print and TV advertising, dealer promotions, and ideas.”
“Now,” he continued, “I meet smart people who want to use methods which rely on automated advertising. When I talk about buying an ad on our site or sponsoring a section of our content, the new generation look at me like I’m crazy. What’s that?”
I listened. What could I say.
The good, old days maybe never existed.
I read “Facebook and Google Are Free. They Shouldn’t Be.” The write up has a simple premise: Users should pay for information.
I am not certain if the write up realizes that paying for online information was the only way to generate revenue from digital content in the past. I know that partners in law firms realize that running queries on LexisNexis and Westlaw have to allocate cash to pay for the digital information about laws, decisions, and cases. For the technical information in Chemical Abstracts, researchers and chemists have to pay as well. Financial data for traders costs money as well.
SIXGILL: Dark Web Intelligence with Sharp Teeth
December 14, 2017
“Sixgill” refers to the breathing apparatus of a shark. Deep. Silent. Stealthy. SIXGILL offers software and services which function like “your eyes in the Dark Web.”
Based in Netanya, just north of Tel Aviv, SIXGILL offers services for its cyber intelligence platform for the Dark Web. What sets the firm apart is its understanding of social networks and their mechanisms for operation.*
The company’s primary product is called “Dark-i.” The firm’s Web site states that the firm’s system can:
- Track and discover communication nodes across darknets with the capability to trace malicious activity back to their original sources
- Track criminal activity throughout the cyber crime lifecycle
- Operate in a covert manner including the ability to pinpoint and track illegal hideouts
- Support clients with automated and intelligence methods.
The Dark-i system is impressive. In a walk through of the firm’s capabilities, I noted these specific features of the Dark-i system:
- Easy-to-understand reports, including summaries of alleged bad actors behaviors with time stamp data
- Automated “profiles” of Dark Web malicious actors
- The social networks of the alleged bad actors
- The behavior patterns in accessing the Dark Web and the Dark Web sites the individuals visit.
- Access to the information on Dark Web forums.
Details about the innovations the company uses are very difficult to obtain. Based on open source information, a typical interface for SIXGILL looks like this:
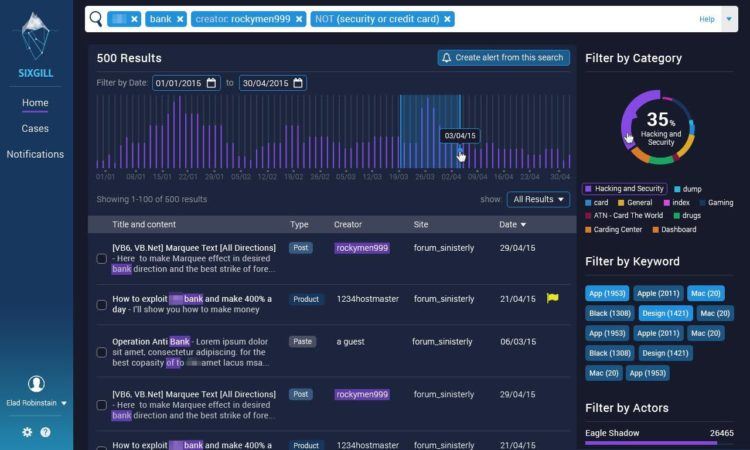
Based on my reading of the information in the screenshot, it appears that this SIXGILL display provides the following information:
- The results of a query
- Items in the result set on a time line
- One-click filtering based on categories taken from the the sources and from tags generated by the system, threat actors, and Dark Web sources
- A list of forum posts with the “creator” identified along with the source site and the date of the post.
Compared with reports about Dark Web activity from other vendors providing Dark Web analytic, monitoring, and search services, the Dark Web Notebook team pegs s SIXGILL in the top tier of services.
Google Relevance: A Light Bulb Flickers
November 20, 2017
The Wall Street Journal published “Google Has Chosen an Answer for You. It’s Often Wrong” on November 17, 2017. The story is online, but you have to pay money to read it. I gave up on the WSJ’s online service years ago because at each renewal cycle, the WSJ kills my account. Pretty annoying because the pivot of the WSJ write up about Google implies that Google does not do information the way “real” news organizations do. Google does not annoy me the way “real” news outfits handle their online services.
For me, the WSJ is a collection of folks who find themselves looking at the exhaust pipes of the Google Hellcat. A source for a story like “Google Has Chosen an Answer for You. It’s Often Wrong” is a search engine optimization expert. Now that’s a source of relevance expertise! Another useful source are the terse posts by Googlers authorized to write vapid, cheery comments in Google’s “official” blogs. The guts of Google’s technology is described in wonky technical papers, the background and claims sections of the Google’s patent documents, and systematic queries run against Google’s multiple content indexes over time. A few random queries does not reveal the shape of the Googzilla in my experience. Toss in a lack of understanding about how Google’s algorithms work and their baked in biases, and you get a write up that slips on a banana peel of the imperative to generate advertising revenue.
I found the write up interesting for three reasons:
- Unusual topic. Real journalists rarely address the question of relevance in ad-supported online services from a solid knowledge base. But today everyone is an expert in search. Just ask any millennial, please. Jonathan Edwards had less conviction about his beliefs than a person skilled in the use of locating a pizza joint on a Google Map.
- SEO is an authority. SEO (search engine optimization) experts have done more to undermine relevance in online than any other group. The one exception are the teams who have to find ways to generate clicks from advertisers who want to shove money into the Google slot machine in the hopes of an online traffic pay day. Using SEO experts’ data as evidence grinds against my belief that old fashioned virtues like editorial policies, selectivity, comprehensive indexing, and a bear hug applied to precision and recall calculations are helpful when discussing relevance, accuracy, and provenance.
- You don’t know what you don’t know. The presentation of the problems of converting a query into a correct answer reminds me of the many discussions I have had over the years with search engine developers. Natural language processing is tricky. Don’t believe me. Grab your copy of Gramatica didactica del espanol and check out the “rules” for el complemento circunstancial. Online systems struggle with what seems obvious to a reasonably informed human, but toss in multiple languages for automated question answer, and “Houston, we have a problem” echoes.
I urge you to read the original WSJ article yourself. You decide how bad the situation is at ad-supported online search services, big time “real” news organizations, and among clueless users who believe that what’s online is, by golly, the truth dusted in accuracy and frosted with rightness.
Humans often take the path of least resistance; therefore, performing high school term paper research is a task left to an ad supported online search system. “Hey, the game is on, and I have to check my Facebook” takes precedence over analytic thought. But there is a free lunch, right?
In my opinion, this particular article fits in the category of dead tree media envy. I find it amusing that the WSJ is irritated that Google search results may not be relevant or accurate. There’s 20 years of search evolution under Googzilla’s scales, gentle reader. The good old days of the juiced up CLEVER methods and Backrub’s old fashioned ideas about relevance are long gone.
I spoke with one of the earlier Googlers in 1999 at a now defunct (thank goodness) search engine conference. As I recall, that confident and young Google wizard told me in a supercilious way that truncation was “something Google would never do.”
What? Huh?
Guess what? Google introduced truncation because it was a required method to deliver features like classification of content. Mr. Page’s comment to me in 1999 and the subsequent embrace of truncation makes clear that Google was willing to make changes to increase its ability to capture the clicks of users. Kicking truncation to the curb and then digging through the gutter trash told me two things: [a] Google could change its mind for the sake of expediency prior to its IPO and [b] Google could say one thing and happily do another.
I thought that Google would sail into accuracy and relevance storms almost 20 years ago. Today Googzilla may be facing its own Ice Age. Articles like the one in the WSJ are just belated harbingers of push back against a commercial company that now has to conform to “standards” for accuracy, comprehensiveness, and relevance.
Hey, Google sells ads. Algorithmic methods refined over the last two decades make that process slick and useful. Selling ads does not pivot on investing money in identifying valid sources and the provenance of “facts.” Not even the WSJ article probes too deeply into the SEO experts’ assertions and survey data.
I assume I should be pleased that the WSJ has finally realized that algorithms integrated with online advertising generate a number of problematic issues for those concerned with factual and verifiable responses.
Enterprise Search: Will Synthetic Hormones Produce a Revenue Winner?
October 27, 2017
One of my colleagues provided me with a copy of the 24 page report with the hefty title:
In Search for Insight 2017. Enterprise Search and Findability Survey. Insights from 2012-2017
I stumbled on the phrase “In Search for Insight 2017.”

The report combines survey data with observations about what’s going to make enterprise search great again. I use the word “again” because:
- The buy up and sell out craziness which culminated with Microsoft’s buying Fast Search & Transfer in 2008 and Hewlett Packard’s purchase of Autonomy in 2011 marked the end of the old-school enterprise search vendors. As you may recall, Fast Search was the subject of a criminal investigation and the HP Autonomy deal continues to make its way through the legal system. You may perceive these two deals as barn burners. I see them as capstones for the era during which search was marketed as the solution to information problems in organizations.
- The word “search” has become confusing and devalued. For most people, “search” means the Danny Sullivan search engine optimization systems and methods. For those with some experience in information science, “search” means locating relevant information. SEO erodes relevance; the less popular connotation of the word suggests answering a user’s question. Not surprisingly, jargon has been used for many years in an effort to explain that “enterprise search” is infused with taxonomies, ontologies, semantic technologies, clustering, discovery, natural language processing, and other verbal chrome trim to make search into a Next Big Thing again. From my point of view, search is a utility and a code word for spoofing Google so that an irrelevant page appears instead of the answer the user seeks.
- The enterprise search landscape (the title of one of my monographs) has been bulldozed and reworked. The money in the old school precision and recall type of search comes from consulting. Search Technologies was acquired by Accenture to add services revenue to the management consulting firm’s repertoire of MBA fixes. What is left are companies offering “solutions” which require substantial engineering, consulting, and training services. The “engine”, in many cases, are open source systems which one can download without burdensome license fees. From my point of view, search boils down to picking an open source solution. If those don’t work, one can license a proprietary system wrapped around open source. If one wants a proprietary system, there are some available, but these are not likely to reach the lofty heights of the Fast Search or Autonomy IDOL systems in the salad days of enterprise search and its promises of a universal search system. The universal search outfit Google pulled out of enterprise search for a reason.
I want to highlight five of the points in the 24 page write up. Please, register to get your own copy of this document.
Here are my five highlights. My comments are in italics after each quote from the document:
-

- Subscribe to Beyond Search
Feature archive
News archive

-