

Enterprise Search Top Vendors: But Who Is the Judge?
July 3, 2008
My jaw dropped when I saw “The Top Enterprise Search Vendors,” an essay by Jon Brodkin, a writer affiliated with Network World. You can read the two-part document here. (Note: The url is one of those wacky jobs with percent signs and random characters, the product of a misbegotten content management system. So, if you can’t get the link to work after I write this [July 3, 2008, 2 pm Eastern time], you are on your own.)
Let’s cut to the chase.
Mr. Brodkin is using a consulting firm’s report as the backbone of his analysis. There is nothing wrong with that approach, and I use it myself for some documents. He picks up assertions in the consultant report and identifies some companies as “best” or “top” in the “enterprise search” market. We need a definition of “enterprise search”. A definition, in my view, is an essential first step. Why? I wrote a 300-page study about moving beyond search for Gilbane Group. A large part of my argument was that no one knows what enterprise search so dissatisfaction runs high, in the 50 to 75 percent. Picking the “best” or “top” vendor when the majority of system users are unhappy is an issue with me.
He writes:
The best enterprise search products on the market come from Autonomy, Endeca, the Microsoft subsidiary Fast and Vivisimo, but Google’s Search Appliance continues to dominate the market in terms of brand awareness and sheer number of customers, Forrester Research says in a new report.
Ah, yes, the Forrester “wave” report. Now we know the origin of the adjectives “top” and “best”. Other vendors to note include:
- Coveo
- IBM
- Microsoft’s own MOSS and MSS search systems (distinct from the Fast Search & Transfer ESP system). This is in too much flux to warrant discussion by me. I handle this in Beyond Search by saying, “Wait and see.” I know this is not what 65 million SharePoint users want to hear, but “wait and see”.
- Oracle
- Recommind.
Let’s do a reality check here, not for Mr. Brodkin’s sake or that of the Forrester “wave” team. Just in case an individual wants to license a search system, some basic information may be useful.
First, there are more than 300 vendors offering search, content processing, and text analytics systems at this time. There is no leader for several reasons:
- Autonomy has diversified aggressively and much of their market impact comes from systems in which search is a comparatively modest part in a far larger system; for example, fraud detection. So, revenues alone or total customer count are not key indicators of search.
- Fast Search & Transfer has been struggling with a modest challenge; namely, the investigation of its finances over an alleged loss of FY2007 $122 million in the fiscal year prior to Microsoft’s buying the company for $1.2 billion. Somehow “best” and “top” are in conflict with this alleged short fall. So, “best” and “top” mean one thing to me and definitely another to the Mr. Brodkin and the Forrester “wave” team. If an outfit is the best, I assume the firm’s financial health is part of its being “top” or “best”. I guess I am old fashioned or an addled goose.
- Endeca works hard to explain that it is an information access company. Sure, search functions work in an Endeca implementation, but I think lumping this company with Autonomy (diversified information services) and Fast Search & Transfer (murky financial picture) clarifies little and confuses more.
- Vivisimo is a relative newcomer to enterprise search. The company has some nifty de-duplication technology and it can federate results from different engines. The company is making sales in the enterprise arena. I categorize it as an up-and-coming vendor. I wonder if Vivisimo was surprised by its being labeled as a firm nosing around in Autonomy and Endeca territory. Great publicity. But Autonomy is about $300 million in revenue. Endeca is in the $110 million in revenue range. Vivisimo is far smaller, maybe one tenth Endeca’s size, but growing. A set to my way of thinking should contain like objects. $300 million, $100 million, $10 million–not the type of set I would craft to explain “enterprise search”.
Second, have vendors been miscategorized. I am okay with mentioning Coveo and Recommind. Both companies seem to have a solid value proposition and a clear sense of who their prospects are. Coveo, in particular, has some extremely tasty technology for mobile search. Recommind, despite its efforts to break out of the legal market, continues to make sales to lawyer-types. I am not sure the word “search” covers what these two firms are offering their customers. I think of both vendors offering “search plus other services and functions.”
Third, identifying IBM and Oracle as key players in search baffles me. Both buy consulting and advertising, but in “enterprise search”, neither figures prominently in my analyses. IBM is not a search company; it is a consulting firm using advice to push hardware, software, and services. Search at IBM can mean Lucene with an IBM T shirt. IBM also sells DB2, FileNet, iPhrase, and assorted text processing tools whose names I cannot keep straight. IBM also has an industry “openness” initiative called UIMA, a gasping swan right now in my opinion.
And, Oracle has been beating the secure search drum to deaf ears for a couple of years. Oracle SES 10g sells more Oracle servers, but Oracle is moving a lot of Google Search Appliances. So, what’s Oracle search? Is it the PL/SQL stuff that fuels more Oracle database installations, the SES 10g, or the Google Search Appliance? My sources indicate that Oracle sells more Google Search Appliances than SES 10g. Why? Well, it works and has a nifty API that allows Oracle consultants to hook the GSA into other enterprise systems. Forrester says Oracle is a search vendor, which is accurate. Forrester and Mr. Brodkin don’t mention the importance of the GSA in Oracle’s information access efforts.
Then there is Google or the GOOG. Google rates inclusion in the list of search leaders. The surprise is that Google is THE leader in enterprise search. The company doesn’t provide much information, but based on my research, Google has more than 11,000 Google Search Appliance licensees and more coming every day. When you add up the revenue from various enterprise activities, Google is not generating the paltry $188 million reported in its FY2007 financials. Nope. The GOOG is in the $400 million range. If my data are correct, Google, not Autonomy, is number one in gross revenue related to search.
What’s this all mean?
Let me boil out the waste products for you:
- Enterprise search is a non-starter in organizations. People don’t like the “search” experience, so the market is shifting. The change is coming quickly, and the established vendors are trying to reposition themselves by adding social search, business analytics, and discovery functions. The problem is that other companies are moving more quickly and delivering these much needed options quicker.
- There are some very significant vendors in the information access market, and these must be included on any procurement team’s “look at” list; specifically, Exalead (Paris) and Isys Search Software (Sydney and Denver). Both companies serve slightly different sectors of the information access market, but omitting them underscores a lack of knowledge of what’s hot and what’s not.
- Specialist vendors are having a significant impact in niche markets, and these vendors could make leaps into other segments as well. Examples that come to my mind are Attensity and Clearwell Systems.
- New players are poised to disrupt existing information access markets. Examples range from Silobreaker (Stockholm) to companies such as Attivio and Connotate. In fact, there is an ecosystem of new and interesting approaches that have search and retrieval functions but are definitely distancing themselves from the train wreck that is “enterprise search”.
I urge you to read the Forrester report. Just be sure of your facts before you base your decision on a single firm’s analysis. There is a reason that a pecking order in consulting exists. At the top are Booz, Allen & Hamilton, Boston Consulting Group, Bain, and McKinsey. Then there is a vast middle tier. Below the middle tier are firms that offers boutique services. Instead of accepting a firm’s view of the “top” or the “best”, make sure the advice you take comes from a firm that has a blue-chip recommendation.
The growing dissatisfaction with enterprise search can come back and bite hard.
Stephen Arnold, July 3, 2008
Funnelback Sucks in a Big Fish
July 3, 2008
I have tracked Funnelback in its various incarnations for years. On July 3, 2008, Dr. David Hawking became the chief scientist of this search system. I profiled the company in Enterprise Search Report, and I think the youngster who took over that job for the 4th edition kept the basics of my analysis. Funnelback is a good system, and it has a number of prestigious clients in Australia, the UK, and Canada.
Dr. Hawking is a recognized leader in information retrieval and search. You can read the complete news release here. Hurry, the PRWeb information gets moved around and deleted quickly. You can get basic information from the Funnelback Web site here.
Keep in mind that Funnelback is not a newcomer to search and content processing. The firm’s system has its roots in years of research at the Australian National University (the MIT of Australia) and its research arm. If you are not familiar with Funnelback, you can see the system in action on the Australian government’s portal at http://www.australia.gov.au or just click here.
Australia and New Zealand have a thriving search and content processing industry. Funnelback competes with ISYS Search Software, a system that I have found quite useful in my research work. You may also want to familiarize yourself with YourAmigo, a company that has some text processing functions bundled with its site optimization services. Also, check out (in person if possible) S.L.I. Systems in Christchurch, New Zealand.
There’s a perception that search is the domain of Silicon Valley. Wrong. Dr. Hawking, prior to this announcement, agreed to a question-and-answer session with the Beyond Search silly goose. I will post the full text of this conversation in a forthcoming Web log posting.
Stephen Arnold, July 3, 2008
Google Faces an Attack of Infinite Legal Eagles
July 3, 2008
My news reader overfloweth today, July 3, 2008. The legal eagles are circling the Googleplex, dropping subpoenas and court orders on the Googlers. In my two studies of Google–The Google Legacy (2005) and Google Version 2.0 (2007) I complied with my publisher’s request and included a list of the vulnerabilities Google faced in its charge to market dominance. I won’t reproduce the list of the dozen or so issues my research identified.
Instead, let me highlight one that has remained a threat constant since Google’s engineers sought inspiration from Yahoo Overture online advertising as a revenue generation mechanism. Google coughed up some cash and stock to Yahoo shortly before the company’s initial public offering. You can read the Google side of the deal here. Since that time, Google has been lawyered up, defending itself against all comers.
In my research, I asserted that lawyers and mathematicians, particularly brilliant mathematicians, don’t always see problems in the same way.
Kurt Opsahl’s “Court Ruling Will Expose Viewing Habits of YouTube Users” makes it clear that Google will have to produce usage data pertinent to YouTube.com, Google’s video service. You can read the full story here. This write up includes links to court documents, and you can grind through the legalese at your leisure.
Usage data is a crown jewel at Google. Few people know what Google captures. Even fewer have seen the fragments of information about the data model into which the usage data are inserted. I did write about one exemplary data table in my KMWorld column a month or two ago. If a legal eagle finds someone who can interpret the log file data in a Googley way, other legal eagles will join those circling the Googleplex. These legal eagles won’t be there for a drink of Odwalla and to get their automobiles washed.
The Bottomline is that this decision, if it survives a legal challenge, is likely to be problematic for Google. Lawyers and log files will result in a different output than achieved from rocket scientists and log files. In math there’s a notion of aleph. This is an aleph of woe for Google or
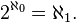
If you find legal eagle activities interesting, you will want to take a gander (no logo pun intended) at TechCrunch’s essay “Judge Protects YouTube’s Source Code, Throws Users to the Wolves”. I like this piece because it underscores some of the issues in a scuffle between old media and the GOOG:
I can understand why Judge Stanton, who graduated from law school in 1955, may be completely and utterly clueless when it comes to online videos services. But perhaps one of his bright young clerks or interns could have told him that (1) handing over user names and a list of videos they’ve watched to a highly litigious copyright holder is extremely likely to result in lawsuits against those users that have watched copyrighted content on YouTube, and (2) YouTube’s source code is about as valuable as the hard drive it would be delivered on, since the core Flash technology is owned by Adobe and there are countless YouTube clones out there, most of which offer higher quality video. YouTube’s core value is in it’s network effect – the library of content along with its massive user base.
Please, read Mr. Arrington’s essay here.
My take on this matter is that Google has its work cut out for its attorneys. My recollection is that Google has some of its attorneys in temporary quarters about one mile from the Google headquarters. Google’s senior management may have to move some of these JDs into Google headquarters and some of the math PhDs out to the trailers now housing some of Google’s juris doctors.
This silly goose thinks Viacom means business, and it is no puny Internet Service Provider in Chicago complaining about an Outlook migration tool. You can read about this legal issue here. This is video, folks. Video is real money. Infinite money in our digital culture.
Stephen Arnold, July 3, 2008
Autonomy: Not Just Deals, Super Deals
July 3, 2008
BusinessWeekly, the voice of Europe’s innovation capital, the east of England, reported on July 2, 2008:
Cambridge enterprise search company Autonomy has scooped two deals in the US in the last week worth over $85 million (£43m) and a top analyst is forecasting massive growth through 2009 on the back of a string of ‘super deals.’
Keep in mind that Autonomy has an annual revenue in the neighborhood of $300 million US, so this reported financial coup is roughly equivalent to more than 10 percent of the company’s annual turnover. You can read the full story here.
Adding to the good news is the fact that Morgan Stanley has given Autonomy an “overweight” rating. To the average investor, “overweight” means too many buckets of Kentucky Fried Chicken. To the financial community, the word means “buy”.
In May 2007, a UK investment outfit took a less optimistic view of Autonomy. But with these new deals, Autonomy appears to be back on a growth track, but I find it curious how two MBA-stuffed institutions can arrive at different views of a public-traded company.
Earlier this week, Autonomy’s founder and chief operating officer, Sir Michael Lynch authored an essay in the prestigious Financial Times. I commented on this story here, but I think the link to the full text has probably expired. Traditional prestigious media are protective of their essays from company presidents.
From my grubby nest in rural Kentucky overlooking the polluted Ohio River, the “voice of Europe’s innovation capital” and the prestigious Financial Times seem to be providing rostra for Sir Michael Lynch. The feature story also includes an interesting view of the market for search and content processing; specifically:
Three pure players – Autonomy, FAST/Microsoft and Endeca – operate in the high-end market and three majors operate in the medium-to-low end market (IBM, Microsoft and Google).
This segmentation does not match the analyses I included in the first three editions of Enterprise Search Report which I wrote and my new study Beyond Search, published in April 2008 by the Gilbane Group. My take on the market is that the companies identified as “pure players” find themselves under increasing competitive pressure from very large superplatforms who are now moving down market and bundling search with higher value solutions. From the bottom, these “pure players” are finding a number of competitors with newer technology and more aggressive pricing challenging from below. The result is that “pure players” have been forced to take drastic action to grow or survive. The Fast Search & Transfer deal with Microsoft and the subsequent questioning of Fast Search’s actual 2007 revenues is one example of financial over reach taking a toll. Fast Search, if my sources are accurate, lost $122 million or so in FY2007. Endeca which has moved past $100 million in revenues passed on an initial public offering and accepted investments from Intel and SAP’s venture arm. So, the “pure players” are not really Switzerland. Autonomy is now the sole occupant of the “pure play” space. Obviously Morgan Stanley thinks my analysis is the quacking of an addled goose. Time and the quarterly reports will tell, I suppose.
Congratulations to Autonomy because, according to Morgan Stanley, the company will benefit from “the Swiss effect.” Like other financial verbal fol-de-rol, the investment banks sees Autonomy’s independence as a benefit. The bank does not mention that there are several hundred other search, content processing, and text analytics companies living in this notional Switzerland. Nor does the bank put “the Swiss effect” into hard economic terms. Also, Switzerland did not have to deal with pesky “free” options in search such as Lucene or FLAX.
So, the there are sunny days ahead for Autonomy shareholders in the opinion of BusinessWeekly.co.uk and the Financial Times.
Stephen Arnold, July 3, 2008
Google Working on Dynamic Runtime
July 3, 2008
A colleague called to my attention Microsoft wizard James Hamilton’s post about a possible Google initiative. You can read the full note here. For me the most interesting point in the note was:
…The popular speculation is that Google will be announcing a dynamic language runtime with support for Python, JavaScript, and Java. A language runtime running on both server-side and client-side with support for a broad range of client devices including mobile phones would be pretty interesting.
Why is this important? More flexibility for developers. Google’s programming innovations continue to percolate.
Stephen Arnold, July 3, 2008
Yahoo’s Semantic Search Still Available
July 3, 2008
In the firestorm of publicity burning through blogland, Yahoo’s semantic search system has been marginalized. I admit, the url is not the easiest to remember: http://www.yr-bcn.es/demos/microsearch/. The moniker Microsearch seems to be intended to tell the astute user that Yahoo processes microformat information. A microformat is a Web-based data formatting approach that seeks to re-use existing content as metadata.
The site is labeled a demonstration, and the Yahoo logo is visible in a funereal black, which I quite like. The service is called Microsearch. The system supports supports RDFa marked-up pages plus some other semantic formats. Yahoo says:
Microsearch is a richer search experience combining traditional search results with metadata extracted from web [sic] pages. At the moment your Yahoo! Search is enriched in three ways: [a] by showing ‘smart’ snippets that summarize the metadata inside the page and allow to take action without actually visiting the page; [b] by showing map and timeline views that aggregate metadata from various pages, [c] by showing pages related to the current result.
I had to dig a bit to find the explicit connection with the Semantic Web, but the site offers a version of semantic search. Yahoo includes a link to the Semantic Web page at the World Wide Web consortium.
Let’s look at the system. Yahoo provides some suggested queries, but I prefer my own.
My first query was “enterprise search”. The system returned the following result page:

The map was visually arresting, but it was irrelevant to the query and the result set. I looked at the results and was surprised to find Microsoft was the number two result. The other results were okay. The same query on Google returned more Microsoft links. My conclusion was that the “semantic” feature on Yahoo worked about as well as regular Google. The other conclusion I drew was that Microsoft is working hard to come up at the top of the results list for the word pair “enterprise search”. Too bad I don’t think of Microsoft and enterprise search as sector leaders.
My second query was for the phrase “Michael Lynch Autonomy”. Here’s what Microsearch displayed:

For this query, the map did not render. I assumed that the system would show me the location of Autonomy’s headquarters in the United Kingdom. Sigh. Microsearch is at version 1.4 on July 3, 2008, and whizzy features should be working. The results were stale. The top ranked hit was a 2006 interview. My recollection is that the Financial Times ran an essay by Mr. Lynch a few days ago. Alas, the system seems unable to factor time into its results ranking. News stories often carry time and date data, and News XML includes explicit tags for these data. I ran the same query on standard Google. Google returned the results set more quickly than Yahoo. Google’s results were poor. The first hit was to someone other than Autonomy’s Mike Lynch. The other hits were more stale than Yahoo’s. Autonomy may want to emulate Microsoft’s search engine optimization push.
Observations
The semantic features of Microsearch did not appear front and center. The mapping function did not work. Compared to Google, Yahoo performed as well as market leader Google. To be fair, Google’s results were not too good and Yahoo hit that benchmark.
Agree? Disagree? Let me know.
Stephen Arnold, July 3, 2008
Texas: A Clever Twist on Computer Consulting
July 2, 2008
Working as an expert witness, I was in a big shot Houston, Texas, law firm. One of the legal eagles had screwed up his laptop. He asked me if I could resolve the problem. I looked at the machine, checked the size of his Outlook PST file (the cause of the problem), did a little nerd magic, and pronounced the machine battle ready.
According to an essay posted at Institute for Justice: Litigating for Liberty, “Magnum PC? New Texas Law Limits Computer Repair to Licensed Private Investigators”, I would have been guilty of a crime. You can read the story here.
The most interesting point in the write up for me is:
The law also criminalizes consumers who knowingly use an unlicensed company to perform any repair that constitutes an investigation in the eyes of the government. Consumers are subject to the same harsh penalties as the repair shops they use: criminal penalties of up to one year in jail and a $4,000 fine, and civil penalties of up to $10,000—just for having their computer repaired by an unlicensed technician.
So, not only was I a bad buy, the lawyer was a bad guy too. I am not sure if this is a hoax or if it is one more example of how interesting the legal system is. A number of scenarios are buzzing through my little mind now. I wonder if consultants working for Booz, Allen & Hamilton involved in systems work will have to be licensed. Somehow a consultant licensed as a private investigator and being paid to root through a client’s computer tickles my funny bone. Texas will need to clarify its consultant monitoring policies, I suppose. The State can’t allow an unlicensed technical SWAT team to fix a computer without the right paperwork.
Next time I am in Texas, I won’t fix your Macbook, Windows notebook, your AS/400–not even your mobile phone with email access. I wonder how much a private investigator’s license is in Texas? Will I have to pass a physical?”
Stephen Arnold, July 2, 2008
Google and Capillary Action
July 2, 2008
I think it was Dr. Snow’s Biology 101 class in 1962 when I had to perform an experiment related to capillary action. Capillary action, as I recall, the ability of a substance to draw another substance into it. My experiment involved a beaker of some foul smelling substance, a chunk of a mop, and a scale. I had to calculate how quickly the stinky stuff moved from the beaker into the mop. I did the experiment, got an A, and continued through life indifferent to this fundamental physical principle so essential to life.
InfoWorld, a great online publication compared to its last days as a failing print publication, has an important essay “Can Google Apps Move Up Market?” The author is Tom Kaneshige, and he does a good job of explaining that Google Apps, while not quite toy applications, are likely to face some resistance in organizations. The most important observation in his write up for me was:
Although Google Apps may carve out niches, it’s unlikely that basic applications in the cloud will play a major role in the way giants of industry conduct business. Imagine sensitive business documents being shared in the cloud without comprehensive enterprise controls. Not only is Google Apps not ready … companies aren’t either.
I don’t want to dispute the InfoWorld essay. I agree with most of its points.
However, I think one important observation may be germane. Google is working like a little beaver to get developers to create software for Google. Google is dating Salesforce.com. There’s the Android initiative. There’s the Google partner ecosystem cranking out scripts via the OneBox API. There’s the mapping crowd extending Google’s ubiquitous geospatial footprint. Developers are a longer term investment, but over a two or three year span, Google’s jejune developer program will have an impact.
Also, Google, as you probably are aware, is chomping on the wooden doors at colleges and universities. I am surprised when I meet a person from Arizona State University who said to me in April 2008, “Google is all over the campus. It’s Gmail. It’s Google Calendar. It’s all Google all the time.” ASU is not alone. The GOOG has its snout into more than 300 major academic institutions. One deal is for 1.5 million students someplace in Australia that I wrote about here.
Google’s approach to the enterprise is a variant of capillary action. As these seemingly uncoordinated activities take place, time–not technology or aggressive salesmanship–will deliver for Google. Google is betting that as its most avid developers mature and its college users enter the work force, these folks will pull Google along. Why beat your head against a concrete wall as Mr. Ballmer did in one of his famous motivational presentations? Why not let capillary action pull Google Apps, the Google Search Appliance, and Google data management services into organizations. It’s easier and doesn’t create YouTube.com video moments.
Stephen Arnold, July 2, 2008
Answering Questions: Holy Grail or Wholly Frustrating
July 2, 2008
The cat is out of the bag. Microsoft has acquired Powerset for $100 million. You can read the official announcement here. The most important part of the announcement to me was:
We know today that roughly a third of searches don’t get answered on the first search and first click…These problems exist because search engines today primarily match words in a search to words on a webpage [sic]. We can solve these problems by working to understand the intent behind each search and the concepts and meaning embedded in a webpage [sic]. Doing so, we can innovate in the quality of the search results, in the flexibility with which searchers can phrase their queries, and in the search user experience. We will use knowledge extracted from webpages [sic] to improve the result descriptions and provide new tools to help customers search better.
I agree. The problem is that delivering on these results is akin to an archaeologist finding the Holy Grail. In my experience, delivering “answers” and “better results” can be wholly frustrating. Don’t believe me? Just take a look at what happened to AskJeeves.com or any of the other semantic / natural language search systems. In fact, doubt is not evident in the dozens of posts about this topic on Techmeme.com this morning.
So, I’m going to offer a different view. I think the same problems will haunt Microsoft as it works to integrate Powerset technology into its various Live.com offerings.
Answering Questions: Circa 1996
In the mid 1990s, Ask Jeeves differentiated itself from the search leaders with its ability to answer questions. Well, some questions. The system worked for this query which I dredged from my files:
What’s the weather in Chicago, Illinois?
At the time, the approach was billed as natural language processing. Google does not maintain comprehensive historical records in its public-facing index. But you can find some information about the original system here or in the Wikipedia entry here.
How did a start up in the mid-1990s answer a user’s questions online? Computers were slow by today’s standards and expensive. Programming was time consuming. There were no tools comparable to python or Web services. Bandwidth was expensive and modems, chugged along south of 56 kilobits per second, eagerly slowing down in the course of a dial up session.

I have no inside knowledge about AskJeeves.com’s technology, but over the years, I have pieced together some information that allows me to characterize how AskJeeves.com delivered NLP (natural language processing) magic.
Humans.
AskJeeves.com compiled a list of frequently asked questions. Humans wrote answers. Programmers put data into database tables. Scripts parsed the user’s query and matched it to the answers in the tables. The real magic, from my point of view, was that AskJeeves.com updated the weather table, so when the system received my query “What is the weather in Chicago, Illinois?”, the system would pull the data from the weather table and display an answer. The system also showed links to weather sites in case the answer part was incorrect or not what the user wanted.
Over time, AskJeeves.com monitored what questions users asked and added these to the system.
What happened when the system received a query that could not be matched to a canned answer in a data table? The system picked the closest question to what the user asked and displayed that answer. So a question such as “What is the square of aleph zero plus N?” generated an answer along the lines “The Cubs won the pennant in 1918?” or some equally crazy answer.
AskJeeves.com discovered several facts about its approach to natural language processing:
- Humans were expensive. AskJeeves.com burned cash. The company tried to apply its canned question answering system to customer support and ended up part of the Barry Diller empire. Humans can answer questions, but the expense of paying humans to craft templates, create answer tables, and code the system were too high then and remain cash hungry today.
- Humans asked questions but did not really mean what they asked? Humans are perverse. A question like “What’s a good bar in San Francisco?” can go off the rails in many ways. For example, what type of bar does the user require? Biker, rock, blue collar? What’s San Francisco? Mission, Sunset, or Powell Street? The problem with answering questions, then, is that humans often have a tough time formulating the right question.
- Information changes. The answer today may not be the answer tomorrow. A system, therefore, has to have some way of knowing what the “right” answer is in the moment. As it turns out, the notion of “real time”–that is, accurate information at this moment–is an interesting challenge. In terms of stock prices, the “now quote” costs money. The quote from yesterday’s closing bell is free. Not only is it tricky to keep the index fresh, to have current information may impose additional costs.
This mini-case sheds light on two challenges in natural language processing.
ZDNet Says, Powerset Won’t Change the Search Equation
July 2, 2008
Larry Dignan has another good essay, “Microsoft’s Search Plan: It’s about Semantics and Possibly for Naught”. You can read the full essay here. Mr. Dignan believes that Microsoft gets some smart people and maybe a boost. He concludes:
However, Microsoft can reinvent search, but it’s still running up a natural Google monopoly. The analogy here is Windows: Microsoft didn’t have the best operating system on the planet. It just had the best positioned one. In search, the tables are turned in Google’s favor. I don’t see how Powerset will change that equation.
He is correct and diplomatic. My view is that semantic technology may help Microsoft with certain narrow functions. But applying the Powerset technology across the 12 billion Web pages that Microsoft says it has indexed will take some clever engineering. Semantic technology has to operate on the source content and figure out what the heck the user means. Google uses short cuts even though it has some serious semantic brainpower at the Googleplex. It is not just technology; it is plumbing that can be scaled economically and operated with tight cost controls.
Microsoft has money, but I am not sure it has enough time. The Google keeps lumbering forward. Microsoft has to find a way to jump over Google and take the high ground. Catching up won’t work. This is the calculus of Microsoft’s search challenge.
Stephen Arnold, July 2, 2008
-

- Subscribe to Beyond Search
Feature archive
News archive

-