

Listen Up, Search Experts, Innovation Ended in 1870
May 2, 2015
I just completed a video in which I said, “Keyword search has not changed for 50 years.” I assume that one or two ahistorical 20 somethings will tell me that I need to get back in the rest home where I belong.
I read “Fundamental Innovation Peaked in 1870 and Why That’s a Good Thing,” which is a write up designed to attract clicks and generate furious online discussion and maybe a comic book. I think that 1870 was 145 years ago, but I could be wrong. Ahistorical allows many interesting things to occur.
The point of the write up is to bolster the assertion that “society has only become less innovative through the years.” I buy that, at least for the period of time I have allocated to write this pre Kentucky Derby blog post on a sparkling spring day with the temperature pegged at 72 degrees Fahrenheit or 22.22 degrees Celsius for those who are particular about conversions accurate to two decimal places. Celsius was defined in the mid 18th century, a fact bolstering the argument of the article under my microscope. Note that the microscope was invented in the late 16th century by two Dutch guys who charged a lot of money for corrective eye wear. I wonder if these clever souls thought about bolting a wireless computer and miniature video screen to their spectacles.
The write up reports that the math crazed lads at the Santa Fe Institute “discovered” innovation has flat lined. Well, someone needs to come up with a better Celsius. Maybe we can do what content processing vendors do and rename “Celsius” to “centigrade” and claim a breakthrough innovation?
Here’s the big idea:
“A new invention consists of technologies, either new or already in use, brought together in a way not previously seen,” the Santa Fe researchers, led by complex systems theorist Hyejin Youn, write. “The historical record on this process is extensive. For recent examples consider the incandescent light bulb, which involves the use of electricity, a heated filament, an inert gas and a glass bulb; the laser, which presupposes the ability to construct highly reflective optical cavities, creates light intensification mediums of sufficient purity and supplies light of specific wavelengths; or the polymerase chain reaction, which requires the abilities to finely control thermal cycling (which involves the use of computers) and isolate short DNA fragments (which in turn applies techniques from chemical engineering).”
Let’s assume the SFI folks are spot on. I would suggest that information access is an ideal example of a lack of innovation. Handwritten notes pinned to manuscripts did not work very well, but the “idea” was there: The notes told the lucky library user something about the scroll in the slot or the pile in some cases. That’s metadata.
Flash forward to the news releases I received last week about breakthrough content classification, metadata extraction, and predictive tagging.
SFI is correct. These notions are quite old. The point overlooked in the write up about the researchers’ insight is that pinned notes did not work very well. I recall learning that monks groused about careless users not pinning them back on the content object when finished.
Take heart. Most automated, super indexing systems are only about 80 percent accurate. That’s close enough for horse shoes and more evidence that digital information access methods are not going to get a real innovator very excited.
Taking a bit of this and a bit of that is what’s needed. Even with these cut and paste approach to invention, the enterprise search sector leaves me with the nostalgic feeling I experience after I leave a museum exhibit.
But what about the Google, IBM, and Microsoft patents? I assume SFI wizards would testify in the role of expert witnesses that the inventions were not original. I wonder how many patent attorneys are reworking their résumés in order to seek an alternative source of revenue?
Lots? Well, maybe not.
Stephen
BA Insight: More Auto Classification for SharePoint
April 30, 2015
I thought automatic indexing and classifying of content was a slam dunk. One could download Elastic and Carrot2 or just use Microsoft’s tools to whip up a way to put accounting tags on accounting documents, and planning on strategic management documents.
There are a number of SharePoint centric “automated solutions” available, and now there is one more.
I noticed on the BA Insight Web site this page:

There was some rah rah in US and Australian publications. But the big point is that either SharePoint administrators have a problem that existing solutions cannot solve or the competitors’ solutions don’t work particularly well.
My hunch is that automatic indexing and classifying in a wonky SharePoint set up is a challenge. The indexing can be done by humans and be terrible. Alternatively, the tagging can be done by an automated system and be terrible.
The issues range from entity resolution (remember the different spellings of Al Qaeda) to “drift.” In my lingo, “drift” means that the starting point for automated indexing just wanders as more content flows through the system and the administrator does not provide the time consuming and often expensive tweaking to get the indexing back on track.
There are smarter systems than some of those marketed to the struggling SharePoint licensees. I profile a number of NGIA systems in my new monograph CyberOSINT: Next Generation Information Access.
The SharePoint folks are not featured in my study because the demands of real time, multi lingual, real time content processing do not work with solutions from more traditional vendors.
On any given day, I am asked to sit through Webinars about concepts, semantics, and classification. If these solutions worked, the market for SharePoint add in would begin to coalesce.
So far, dealing with the exciting world of SharePoint content processing remains a work very much in progress.
Stephen E Arnold, April 30, 2015
Recorded Future: The Threat Detection Leader
April 29, 2015
The Exclusive Interview with Jason Hines, Global Vice President at Recorded Future
In my analyses of Google technology, despite the search giant’s significant technical achievements, Google has a weakness. That “issue” is the company’s comparatively weak time capabilities. Identifying the specific time at which an event took place or is taking place is a very difficult computing problem. Time is essential to understanding the context of an event.
This point becomes clear in the answers to my questions in the Xenky Cyber Wizards Speak interview, conducted on April 25, 2015, with Jason Hines, one of the leaders in Recorded Future’s threat detection efforts. You can read the full interview with Hines on the Xenky.com Cyber Wizards Speak site at the Recorded Future Threat Intelligence Blog.
Recorded Future is a rapidly growing, highly influential start up spawned by a team of computer scientists responsible for the Spotfire content analytics system. The team set out in 2010 to use time as one of the lynch pins in a predictive analytics service. The idea was simple: Identify the time of actions, apply numerical analyses to events related by semantics or entities, and flag important developments likely to result from signals in the content stream. The idea was to use time as the foundation of a next generation analysis system, complete with visual representations of otherwise unfathomable data from the Web, including forums, content hosting sites like Pastebin, social media, and so on.
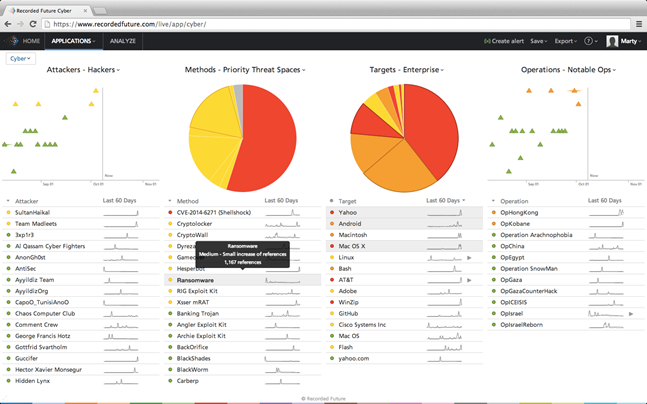
A Recorded Future data dashboard it easy for a law enforcement or intelligence professionals to identify important events and, with a mouse click, zoom to the specific data of importance to an investigation. (Used with the permission of Recorded Future, 2015.)
Five years ago, the tools for threat detection did not exist. Components like distributed content acquisition and visualization provided significant benefits to enterprise and consumer applications. Google, for example, built a multi-billion business using distributed processes for Web searching. Salesforce.com integrated visualization into its cloud services to allow its customers to “get insight faster.”
According to Jason Hines, one of the founders of Recorded Future and a former Google engineer, “When our team set out about five years ago, we took on the big challenge of indexing the Web in real time for analysis, and in doing so developed unique technology that allows users to unlock new analytic value from the Web.”
Recorded Future attracted attention almost immediately. In what was an industry first, Google and In-Q-Tel (the investment arm of the US government) invested in the Boston-based company. Threat intelligence is a field defined by Recorded Future. The ability to process massive real time content flows and then identify hot spots and items of interest to a matter allows an authorized user to identify threats and take appropriate action quickly. Fueled by commercial events like the security breach at Sony and cyber attacks on the White House, threat detection is now a core business concern.
The impact of Recorded Future’s innovations on threat detection was immediate. Traditional methods relied on human analysts. These methods worked but were and are slow and expensive. The use of Google-scale content processing combined with “smart mathematics” opened the door to a radically new approach to threat detection. Security, law enforcement, and intelligence professionals understood that sophisticated mathematical procedures combined with a real-time content processing capability would deliver a new and sophisticated approach to reducing risk, which is the central focus of threat detection.
In the exclusive interview with Xenky.com, the law enforcement and intelligence information service, Hines told me:
Recorded Future provides information security analysts with real-time threat intelligence to proactively defend their organization from cyber attacks. Our patented Web Intelligence Engine indexes and analyzes the open and Deep Web to provide you actionable insights and real-time alerts into emerging and direct threats. Four of the top five companies in the world rely on Recorded Future.
Despite the blue ribbon technology and support of organizations widely recognized as the most sophisticated in the technology sector, Recorded Future’s technology is a response to customer needs in the financial, defense, and security sectors. Hines said:
When it comes to security professionals we really enable them to become more proactive and intelligence-driven, improve threat response effectiveness, and help them inform the leadership and board on the organization’s threat environment. Recorded Future has beautiful interactive visualizations, and it’s something that we hear security administrators love to put in front of top management.
As the first mover in the threat intelligence sector, Recorded Future makes it possible for an authorized user to identify high risk situations. The company’s ability to help forecast and spotlight threats likely to signal a potential problem has obvious benefits. For security applications, Recorded Future identifies threats and provides data which allow adaptive perimeter systems like intelligent firewalls to proactively respond to threats from hackers and cyber criminals. For law enforcement, Recorded Future can flag trends so that investigators can better allocate their resources when dealing with a specific surveillance task.
Hines told me that financial and other consumer centric firms can tap Recorded Future’s threat intelligence solutions. He said:
We are increasingly looking outside our enterprise and attempt to better anticipate emerging threats. With tools like Recorded Future we can assess huge swaths of behavior at a high level across the network and surface things that are very pertinent to your interests or business activities across the globe. Cyber security is about proactively knowing potential threats, and much of that is previewed on IRC channels, social media postings, and so on.
In my new monograph CyberOSINT: Next Generation Information Access, Recorded Future emerged as the leader in threat intelligence among the 22 companies offering NGIA services. To learn more about Recorded Future, navigate to the firm’s Web site at www.recordedfuture.com.
Stephen E Arnold, April 29, 2015
Cerebrant Discovery Platform from Content Analyst
April 29, 2015
A new content analysis platform boasts the ability to find “non-obvious” relationships within unstructured data, we learn from a write-up hosted at PRWeb, “Content Analyst Announces Cerebrant, a Revolutionary SaaS Discovery Platform to Provide Rapid Insight into Big Content.” The press release explains what makes Cerebrant special:
“Users can identify and select disparate collections of public and premium unstructured content such as scientific research papers, industry reports, syndicated research, news, Wikipedia and other internal and external repositories.
“Unlike alternative solutions, Cerebrant is not dependent upon Boolean search strings, exhaustive taxonomies, or word libraries since it leverages the power of the company’s proprietary Latent Semantic Indexing (LSI)-based learning engine. Users simply take a selection of text ranging from a short phrase, sentence, paragraph, or entire document and Cerebrant identifies and ranks the most conceptually related documents, articles and terms across the selected content sets ranging from tens of thousands to millions of text items.”
We’re told that Cerebrant is based on the company’s prominent CAAT machine learning engine. The write-up also notes that the platform is cloud-based, making it easy to implement and use. Content Analyst launched in 2004, and is based in Reston, Virginia, near Washington, DC. They also happen to be hiring, in case anyone here is interested.
Cynthia Murrell, April 29, 2015
Sponsored by ArnoldIT.com, publisher of the CyberOSINT monograph
Enterprise Search Vendors: One Way to Move Past Failure
April 21, 2015
I just finished reading articles about IBM’s quarterly report. The headline is that the company has reported slumping revenues for three years in a row. Pretty impressive. I assumed that Watson, fueled with Lucene, home brew scripts, acquisitions, and liberal splashes of public relations, would be the revenue headliner.
How does IBM Watson’s unit, newly enhanced with a health component, respond to what I would call “missing a target.” Others, who are more word worthy than I, might use the word “failure.”
I read a blog post which lured me because at age 70 I am not sure where I left my dog, wife, and automobile this morning. Short term memory is indeed thrilling. Now what was I thinking?
Oh, right, “Embrace Selective Short-Term Memory to Move Past Failure Quickly.” The point of the write up is that those who have failed can more forward using this trick:
Rather than get caught up trying to emotionally soothe yourself, just forget it happened.
I have a theory that after an enterprise search vendor finds itself in a bit of a sticky wicket, the marketers can move on to the next client, repeat the assertions about semantic search or natural language processing or Big Data or whatever chant of buzzwords lands a sale.
Ask the marketer about an issue—for example, Convera and the NBA, Fast Search and the Norwegian authorities, or Autonomy and the Department of Energy—and you confront a team with a unifying characteristic: The memory of the “issues” with a search system is a tabula rasa. Ask someone about the US Army’s search system or the UK National Health Service about its meta indexing.
There is nothing quite like the convenient delete key which operates the selective memory functions.
Stephen E Arnold, April 21, 2015
The Law of Moore: Is Information Retrieval an Exception?
April 17, 2015
I read “Moore’s Law Is Dead, Long Live Moore’s Law.” The “law” cooked up by a chip company suggests that in technology stuff gets better, faster, and cheaper.” With electronic brains getting, better, faster, cheaper, it follows that phones are more wonderful every few weeks. The logic applies to laptops, intelligence in automobiles, and airline related functions.
The article focuses on the Intel-like world of computer parts. The write up makes this point which I highlighted:
From 2005 through 2014, Moore’s Law continued — but the emphasis was on improving cost by driving down the expense of each additional transistor. Those transistors might not run more quickly than their predecessors, but they were often more power-efficient and less expensive to build.
Yep, the cheaper point is significant. The article then tracks to a point that warranted a yellow highlight:
After 50 years, Moore’s Law has become cultural shorthand for innovation itself. When Intel, or Nvidia, or Samsung refer to Moore’s Law in this context, they’re referring to the continuous application of decades of knowledge and ingenuity across hundreds of products. It’s a way of acknowledging the tremendous collaboration that continues to occur from the fab line to the living room, the result of painstaking research aimed to bring a platform’s capabilities a little more in line with what users want. Is that marketing? You bet. But it’s not just marketing.
These two points sparked my thinking about the discipline of enterprise information access. Enterprise search relies on a wide range of computing operations. If these operations are indeed getting better, faster, and cheaper, does it make sense to assume that information retrieval is also getting better, faster, and cheaper?
What is happening from my point of view is that the basic design of enterprise information access systems has not changed significantly in the last decade, maybe longer. There is the content acquisition module, the normalization or transformation module, the indexing module, the query processing module, the administrative module, and other bits and pieces.
The outputs from today’s information access systems do not vary much from the outputs available from systems on offer a decade ago. Endeca generated visual reports by 2003. Relationship maps were available from Inxight and Semio (remember that outfit) even earlier. Smart software like the long forgotten Inference system winnowed results on what the user sought in his or her query. Linguistic functions were the heart and soul of Delphes. Statistical procedures were the backbone of PLS, based on Cornell wizardry.
Search and retrieval has benefited from faster hardware. But the computational burdens piled on available resources have made it possible to layer on function after function. The ability to make layers of content processing and filtering work has done little to ameliorate the grousing about many enterprise search systems.
The fix has not been to deliver a solution significantly different from what Autonomy and Fast Search offered in 2001. The fix has been to shift from what users’ need to deal with business questions to:
- Business intelligence
- Semantics
- Natural language processing
- Cognitive computing
- Metadata
- Visualization
- Text analytics.
I know I am missing some of the chestnuts. The point is that information access may be lagging behind certain other sectors; for example, voice search via a mobile device. When I review a “new” search solution, I often find myself with the same sense of wonder I had when I first walked through the Smithsonian Museum: Interesting but mostly old stuff.
Just a thought that enterprise search is delivering less, not “Moore.”
Stephen E Arnold, April 17, 2015
Digital Reasoning Goes Cognitive
April 16, 2015
A new coat of paint is capturing some tire kickers’ attention.
IBM’s Watson is one of the dray horses pulling the cart containing old school indexing functions toward the airplane hanger.
There are assorted experts praising the digital equivalent of a West Coast Custom’s auto redo. A recent example is Digital Reasoning’s embrace of the concept of cognitive computing.
Digital Reasoning is about 15 years old and has provided utility services to the US government and some commercial clients. “Digital Reasoning Goes cognitive: CEO Tim Estes on Text, Knowledge, and Technology” explains the new marketing angle. The write up reported:
Cognitive is a next computing paradigm, responding to demand for always-on, hyper-aware data technologies that scale from device form to the enterprise. Cognitive computing is an approach rather than a specific capability. Cognitive mimics human perception, synthesis, and reasoning capabilities by applying human-like machine-learning methods to discern, assess, and exploit patterns in everyday data. It’s a natural for automating text, speech, and image processing and dynamic human-machine interactions.
If you want to keep track of the new positioning text processing companies are exploring, check out the write up. Will cognitive computing become the next big thing? For vendors struggling to meet stakeholder expectations, cognitive computing sounds more zippy that customer support services or even the hyperventilating sentiment analysis positioning.

Lego blocks are pieces that must be assembled.
Indexing never looked so good. Now the challenge is to take the new positioning and package it in a commercial product which can generate sustainable, organic revenues. Enterprise search positioning has not been able to achieve this goal with consistency. The processes and procedures for cognitive computing remind me of Legos. One can assemble the blocks in many ways. The challenge will be to put the pieces together so that a hardened, saleable product can be sold or licensed.

Is there a market for Lego airplane assembled by hand? Vendors of components may have to create “kits” in order to deliver a solution a customer can get his or her hands around.
An unfamiliar function with a buzzword can be easy to sell to those organizations with money and curiosity. Jargon is often not enough to keep stakeholders and in the case of IBM shareholders smiling. A single or a handful of Lego blocks may not satisfy those who want to assemble a solution that is more than a distraction. Is cognitive computing a supersonic biplane or a historical anomaly?
This is worth watching because many companies are thrashing for a hook which will lead to significant revenues, profits, and sustainable growth, not just a fresh paint job.
Stephen E Arnold, April 16, 2015
Yahoo: A Portion of Its Fantastical Search History
April 15, 2015
I have a view of Yahoo. Sure, it was formed when I was part of the team that developed The Point (Top 5% of the Internet). Yahoo had a directory. We had a content processing system. We spoke with Yahoo’s David Filo. Yahoo had a vision, he said. We said, No problem.
The Point became part of Lycos, embracing Fuzzy and his round ball chair. Yahoo, well, Yahoo just got bigger and generally went the way of general purpose portals. CEOs came and went. Stakeholders howled and then sulked.
I read or rather looked at “Yahoo. Semantic Search From Document Retrieval to Virtual Assistants.” You can find the PowerPoint “essay” or “revisionist report” on SlideShare. The deck was assembled by the director of research at Yahoo Labs. I don’t think this outfit is into balloons, self driving automobiles, and dealing with complainers at the European Commission. Here’s the link. Keep in mind you may have to sign up with the LinkedIn service in order to do anything nifty with the content.
The premise of the slide deck is that Yahoo is into semantic search. After some stumbles, semantic search started to become a big deal with Google and rich snippets, Bing and its tiles, and Facebook with its Like button and the magical Open Graph Protocol. The OGP has some fascinating uses. My book CyberOSINT can illuminate some of these uses.
And where is Yahoo in the 2008 to 2010 interval when semantic search was abloom? Patience, grasshopper.
Yahoo was chugging along with its Knowledge Graph. If this does not ring a bell, here’s the illustration used in the deck:

The date is 2013, so Yahoo has been busy since Facebook, Google, and Microsoft were semanticizing their worlds. Yahoo has a process in place. Again from the slide deck:

I was reminded of the diagrams created by other search vendors. These particular diagrams echo the descriptions of the now defunct Siderean Software server’s set up. But most content processing systems are more alike than different.
Elastic What: Stretching Understanding to the Snapping Point
April 10, 2015
I love Amazon. I love Elastic as a name for search. I hate confusion. Elasticsearch is now “Elastic.” I get it. But after I read “Amazon Launches New File Storage Service For EC2”, there may be some confusion between Amazon’s use of Elastic, various Amazon “elastic” services, and search. Is Amazon going to embrace the word “elastic” to describe its information retrieval system. Will this cause some confusion with the open source search vendor Elastic? I find it interesting that name confusion is an ever present issue in search. I have mentioned what happens when a company loses control of its name. Examples range from Thunderstone (a maker of search and search appliances) and the consumer software with the same name. Smartlogic (indexing software) is now facing encroachment from Smartlogic.io (consulting services). Brainware, now owned by Lexmark, lost control of its brand when distasteful videos appeared with the label Brainware. The brand was blasted with nasty bits. Where is the search oriented Brainware now? Retired I believe just as I am.
Little wonder some people have difficulty figuring out which vendor offers what software. Stretch your mind around the challenge of explaining that you want the Amazon elastic and the Elastic elastic. Vendors seem to operate without regard to the need to reduce signal mixing.
Stephen E Arnold, April 10, 2015
Progress in Image Search Tech
April 8, 2015
Anyone interested in the mechanics behind image search should check out the description of PicSeer: Search Into Images from YangSky. The product write-up goes into surprising detail about what sets their “cognitive & semantic image search engine” apart, complete with comparative illustrations. The page’s translation seems to have been done either quickly or by machine, but don’t let the awkward wording in places put you off; there’s good information here. The text describes the competition’s approach:
“Today, the image searching experiences of all major commercial image search engines are embarrassing. This is because these image search engines are
- Using non-image correlations such as the image file names and the texts in the vicinity of the images to guess what are the images all about;
- Using low-level features, such as colors, textures and primary shapes, of image to make content-based indexing/retrievals.”
With the first approach, they note, trying to narrow the search terms is inefficient because the software is looking at metadata instead of inspecting the actual image; any narrowed search excludes many relevant entries. The second approach above simply does not consider enough information about images to return the most relevant, and only most relevant, results. The write-up goes on to explain what makes their product different, using for their example an endearing image of a smiling young boy:
“How can PicSeer have this kind of understanding towards images? The Physical Linguistic Vision Technologies have can represent cognitive features into nouns and verbs called computational nouns and computational verbs, respectively. In this case, the image of the boy is represented as a computational noun ‘boy’ and the facial expression of the boy is represented by a computational verb ‘smile’. All these steps are done by the computer itself automatically.”
See the write-up for many more details, including examples of how Google handles the “boy smiles” query. (Be warned– there’s a very brief section about porn filtering that includes a couple censored screenshots and adult keyword examples.) It looks like image search technology progressing apace.
Cynthia Murrell, April 08, 2015
Stephen E Arnold, Publisher of CyberOSINT at www.xenky.com
-

- Subscribe to Beyond Search
Feature archive
News archive

-