

Free Book from OpenText on Business in the Digital Age
May 27, 2015
This is interesting. OpenText advertises their free, downloadable book in a post titled, “Transform Your Business for a Digital-First World.” Our question is whether OpenText can transform their own business; it seems their financial results have been flat and generally drifting down of late. I suppose this is a do-as-we-say-not-as-we-do situation.
The book may be worth looking into, though, especially since it passes along words of wisdom from leaders within multiple organizations. The description states:
“Digital technology is changing the rules of business with the promise of increased opportunity and innovation. The very nature of business is more fluid, social, global, accelerated, risky, and competitive. By 2020, profitable organizations will use digital channels to discover new customers, enter new markets and tap new streams of revenue. Those that don’t make the shift could fall to the wayside. In Digital: Disrupt or Die, a multi-year blueprint for success in 2020, OpenText CEO Mark Barrenechea and Chairman of the Board Tom Jenkins explore the relationship between products, services and Enterprise Information Management (EIM).”
Launched in 1991, OpenText offers tools for enterprise information management, business process management, and customer experience management. Based in Waterloo, Ontario, the company maintains offices around the world.
Cynthia Murrell, May 27, 2015
Sponsored by ArnoldIT.com, publisher of the CyberOSINT monograph
Computing Power Up a Trillion Fold in 60 Years. Search Remains Unchanged.
May 25, 2015
I get the Moore’s Law thing. The question is, “Why isn’t search and content processing improving?”
Navigate to “Processing Power Has Increased by One Trillion-Fold over the Past Six Decades” and check out the infographic. There are FLOPs and examples of devices which deliver them. I focused on the technology equivalents; for example, the Tianhe 2 Supercomputer is the equivalent of 18,400 PlayStation 4s.

The problem is that search and content processing continue to bedevil users. Perhaps the limitations of the methods cannot be remediated by a bigger, faster assemblage of metal and circuits?
The improvement in graphics is evident. But allowing me to locate a single document in my multi petabyte archive continues to a challenge. I have more search systems than the average squirrel in Harrod’s Creek.
Findability is creeping along. After 60 years, the benefits of information access systems are very difficult to tie to better decisions, increased revenues, and more efficient human endeavors even when a “team of teams” approach is used.
Wake up call for the search industry. Why not deliver some substantive improvements in information access which are not tied to advertising? Please, do not use the words metadata, semantics, analytics, and intelligence in your marketing. Just deliver something that provides me with the information I require without my having to guess key words, figure out odd ball clustering, or waiting minutes or hours for a query to process.
I don’t want Hollywood graphics. I want on point information. In the last 60 years, my information access needs have not been met.
Stephen E Arnold, May 25, 2015
IBM Watson: 75 Industries Have Watson Apps. What about Revenue from Watson?
May 25, 2015
Was it just four years ago? How PR time flies. I read “Boyhood.” Now here’s the subtitle, which is definitely Google-licious:
Watson was just 4 years old when it beat the best human contestants on Jeopardy! As it grows up and goes out into the world, the question becomes: How afraid of it should we be?
I am not too afraid. If I were the president of IBM, I would be fearful. Watson was supposed to be well on its way north of $1 billion in revenue. If I were the top wizards responsible for Watson, I would be trepedatious . If I were a stakeholder in IBM, I would be terrified.
But Watson does not frighten me. Watson, in case you do not know, is built from:
- Open source search
- Acquired companies’ technology
- Home brew scripts
- IBM bit iron
The mix is held together with massive hyperbole-infused marketing.
The problem is that the revenue is just not moving the needle for the Big Blue bean counters. Please, recall that IBM has reported dismal financial results for three years. IBM is buying back its stock. IBM is selling its assets. IBM is looking at the exhaust pipes of outfits like Amazon. IBM is in a pickle.
The write up ignores what I think are important factoids about IBM. The article asserts:
The machine began as the product of a long-shot corporate stunt, in which IBM engineers set out to build an artificial intelligence that could beat the greatest human champions at Jeopardy!, one that could master language’s subtleties: rhymes, allusions, puns….It has folded so seamlessly into the world that, according to IBM, the Watson program has been applied in 75 industries in 17 countries, and tens of thousands of people are using its applications in their own work. [Emphasis added]
How could I be skeptical? Molecular biology. A cook book. Jeopardy.
Now for some history:
Language is the “holy grail,” he said, “the reflection of how we think about the world.” He tapped his head. “It’s the path into here.”
And then the epiphany:
Watson was becoming something strange, and new — an expert that was only beginning to understand. One day, a young Watson engineer named Mike Barborak and his colleagues wrote something close to the simplest rule that he could imagine, which, translated from code to English, roughly meant: Things are related to things. They intended the rule as an instigation, an instruction to begin making a chain of inferences, each idea leaping to the next. Barborak presented a medical scenario, a few sentences from a patient note that described an older woman entering the doctor’s office with a tremor. He ran the program — things are related to things — and let Watson roam. In many ways, Watson’s truest expression is a graph, a concept map of clusters and connective lines that showed the leaps it was making. Barborak began to study its clusters — hundreds, maybe thousands of ideas that Watson had explored, many of them strange or obscure. “Just no way that a person would ever manually do those searches,” Barborak said. The inferences led it to a dense node that, when Barborak examined it, concerned a part of the brain…that becomes degraded by Parkinson’s disease. “Pretty amazing,” Barborak said. Watson didn’t really understand the woman’s suffering. But even so, it had done exactly what a doctor would do — pinpointed the relevant parts of the clinical report, discerned the disease, identified the biological cause. To make these leaps, all you needed was to read like a machine: voraciously and perfectly.
I have to take a break. My heart is racing. How could this marvel of technology be used to save lives, improve the output of Burger King, and become the all time big winner on the the Price Is Right?
Now let’s give IBM a pat on the back for getting this 6.000 word write up in a magazine consumed by those who love the Big Apple without the New Yorker’s copy editors poking their human nose into reportage.
From my point of view, Watson needs to deliver:
- Sustainable revenue
- Demonstrate that the system can be affordable
- Does not require human intermediaries to baby sit the system
- Process content so that real time outputs are usable by those needing “now” insights
- Does not make egregious errors which cause a human using Watson to spend time shaping or figuring out if the outputs are going to deliver what the user requires; for example, a cancer treatment regimen which helps the patient or a burrito a human can enjoy.
Hewlett Packard and IBM have managed to get themselves into the “search and content processing” bottle. It sure seems as if better information outputs will lead to billions in revenue. Unfortunately the realty is that getting big bucks from search and content processing is very difficult to do. For verification, just run a query on Google News with these terms: Hewlett Packard Autonomy.
The search and content processing sector is a utility function. There are applications which can generate substantial revenue. And it is true that these vendors include search as a utility function.
But pitching smart software spitballs works when one is not being watched by stakeholders. Under scrutiny, the approach does not have much of a chance. Don’t believe me? Take your entire life savings and buy IBM stock. Let me know how that works out.
Stephen E Arnold, May 25, 2015
Lexmark Buys Kofax: Scanning and Intelligence Support
May 22, 2015
Short honk: I was fascinated when Lexmark purchased Brainware and ISYS Search Software a couple of years ago. Lexmark, based in Lexington, Kentucky, used to be an IBM unit. That it seems did not work out as planned. Now Lexmark is in the scanning and intelligence business. Kofax converts paper to digital images. Think health care and financial services, among other paper centric operations. Kofax bought Kapow, a Danish outfit that provides connectors and ETL software and services. ETL means extract, transform, and load. Kapow is a go to outfit in the intelligence and government services sector. You can read about Lexmark’s move in “Lexmark Completes Acquisition of Kofax, Announces Enterprise Software Leadership Change.”
According to the write up:
- This was a billion dollar deal
- The executive revolving door is spinning.
In my experience, it is easier to spend money than to make it. Will Lexmark be able to convert these content processing functions into billions of dollars in revenue? Another good question to watch the company try to answer in the next year or so. Printers are a tough business. Content processing may be even more challenging. But it is Kentucky. Long shots get some love until the race is run.
Stephen E Arnold, May 22, 2015
Expert System Connects with PwC
May 21, 2015
Short honk: Expert System has become a collaborator with PwC (formerly a unit of IBM and an accounting firm). The article points out:
Expert System, a company active in the semantic technology for information management and big data listed on Aim Italy, announced the collaboration with PwC, global network of professional services and integrated audit, advisory, legal and tax, for Expo Business Matching, the virtual platform of business meetings promoted by Expo Milano 2015, the Chamber of Commerce of Milan, Promos, Fiera Milano and PwC.
Expert System is a content processing developer with offices in Italy and the United States.
Stephen E Arnold, May 21, 2015
Lexalytics Offers Tunable Text Mining
May 13, 2015
Want to do text mining without some of the technical hassles? if so, you will want to read about Lexalytics “the industry’s most tunable and configurable text mining technology.” Navigate to “Lexalytics Unveils Industry’s First Wizard for Text Mining and Sentiment Analysis.” I learned that text mining can be fun, easy, and intuitive.” I highlighted this quote from the news story as an indication that one does not need to understand exactly what’s going on in the text mining process:
“Before, our customers had to understand the meaning of things like ‘alpha-numeric content threshold’ and ‘entities confidence threshold,'” Jeff continued. “Lexalytics provides the most knobs to turn to get the results exactly as you want them, and now our customers don’t even have to think about them.”
Text mining, the old-fashioned way, required understanding of what was required, what procedures were appropriate, and ability to edit or write scripts. There are other skills that used to be required as the entry fee to text mining. The modern world of interfaces allows anyone to text mine. Do users understand the outputs? Sure. Perfectly.
As I read the story, I recalled a statement in “A Review of Three Natural Language Processors, AlchemyAPI, OpenCalais, and Semantria.” Here is the quote I noted in that July 2014 write up by Marc Clifton:
I find the concept of Natural Language Processing intriguing and that it holds many possibilities for helping to filter and analyze the vast and growing amount of information out there on the web. However, I’m not quite sure exactly how one uses the output of an NLP service in a productive way that goes beyond simple keyword matching. Some people will of course be interested in whether the sentiment is positive or negative, and I think the idea of extracting concepts (AlchemyAPI) and topics (Semantria) are useful in extracting higher level abstractions regarding a document. NLP is therefore an interesting field of study and I believe that the people who provide NLP services would benefit from the feedback of users to increase the value of their service.
Perhaps the feedback was, “Make this stuff easy to do.” Now the challenge is to impart understanding to what a text mining system outputs. That might be a bit more difficult.
Stephen E Arnold, May 13, 2015
Math and Search Experts
May 10, 2015
I found “There’s More to Mathematics Than Rigor and Proofs” a useful reminder between the the person who is comfor4table with math and the person who asserts he is good in math. With more search and content processing embracing numerical recipes, the explanations of what a math centric system can do often leave me rolling my eyes and, in some cases, laughing out loud.
This essay explains that time and different types of math experiences are necessary stages in developing a useful facility with some of today’s information retrieval systems and methods. The write up points out:
The distinction between the three types of errors can lead to the phenomenon (which can often be quite puzzling to readers at earlier stages of mathematical development) of a mathematical argument by a post-rigorous mathematician which locally contains a number of typos and other formal errors, but is globally quite sound, with the local errors propagating for a while before being cancelled out by other local errors. (In contrast, when unchecked by a solid intuition, once an error is introduced in an argument by a pre-rigorous or rigorous mathematician, it is possible for the error to propagate out of control until one is left with complete nonsense at the end of the argument.)
Perhaps this section of the article sheds some light on the content processing systems which wander off the track of relevance and accuracy? As my mathy relative Vladimir Igorevich Arnold was fond of saying to anyone who would listen: Understand first, then talk.
Stephen E Arnold, May 10, 2015
Hoping to End Enterprise Search Inaccuracies
May 1, 2015
Enterprise search is limited to how well users tag their content and the preloaded taxonomies. According Tech Target’s Search Content Management blog, text analytics might be the key to turning around poor enterprise search performance: “How Analytics Engines Could Finally-Relieve Enterprise Pain.” Text analytics turns out to only be part of the solution. Someone had the brilliant idea to use text analytics to classification issues in enterprise search, making search reactive to user input to proactive to search queries.
In general, analytics search engines work like this:
“The first is that analytics engines don’t create two buckets of content, where the goal is to identify documents that are deemed responsive. Instead, analytics engines identify documents that fall into each category and apply the respective metadata tags to the documents. Second, people don’t use these engines to search for content. The engines apply metadata to documents to allow search engines to find the correct information when people search for it. Text analytics provides the correct metadata to finally make search work within the enterprise.”
Supposedly, they are fixing the tagging issue by removing the biggest cause for error: humans. Microsoft caught onto how much this could generate profit, so they purchased Equivio in 2014 and integrated the FAST Search platform into SharePoint. Since Microsoft is doing it, every other tech company will copy and paste their actions in time. Enterprise search is gull of faults, but it has improved greatly. Big data trends have improved search quality, but tagging continues to be an issue. Text analytics search engines will probably be the newest big data field for development. Hint for developers: work on an analytics search product, launch it, and then it might be bought out.
Whitney Grace, May 1 2015
Sponsored by ArnoldIT.com, publisher of the CyberOSINT monograph
Recorded Future: The Threat Detection Leader
April 29, 2015
The Exclusive Interview with Jason Hines, Global Vice President at Recorded Future
In my analyses of Google technology, despite the search giant’s significant technical achievements, Google has a weakness. That “issue” is the company’s comparatively weak time capabilities. Identifying the specific time at which an event took place or is taking place is a very difficult computing problem. Time is essential to understanding the context of an event.
This point becomes clear in the answers to my questions in the Xenky Cyber Wizards Speak interview, conducted on April 25, 2015, with Jason Hines, one of the leaders in Recorded Future’s threat detection efforts. You can read the full interview with Hines on the Xenky.com Cyber Wizards Speak site at the Recorded Future Threat Intelligence Blog.
Recorded Future is a rapidly growing, highly influential start up spawned by a team of computer scientists responsible for the Spotfire content analytics system. The team set out in 2010 to use time as one of the lynch pins in a predictive analytics service. The idea was simple: Identify the time of actions, apply numerical analyses to events related by semantics or entities, and flag important developments likely to result from signals in the content stream. The idea was to use time as the foundation of a next generation analysis system, complete with visual representations of otherwise unfathomable data from the Web, including forums, content hosting sites like Pastebin, social media, and so on.
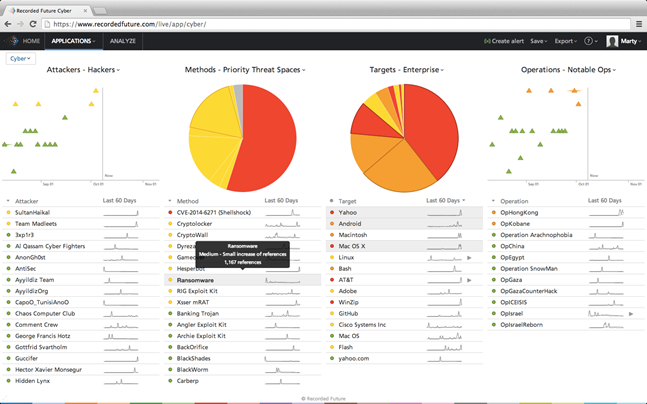
A Recorded Future data dashboard it easy for a law enforcement or intelligence professionals to identify important events and, with a mouse click, zoom to the specific data of importance to an investigation. (Used with the permission of Recorded Future, 2015.)
Five years ago, the tools for threat detection did not exist. Components like distributed content acquisition and visualization provided significant benefits to enterprise and consumer applications. Google, for example, built a multi-billion business using distributed processes for Web searching. Salesforce.com integrated visualization into its cloud services to allow its customers to “get insight faster.”
According to Jason Hines, one of the founders of Recorded Future and a former Google engineer, “When our team set out about five years ago, we took on the big challenge of indexing the Web in real time for analysis, and in doing so developed unique technology that allows users to unlock new analytic value from the Web.”
Recorded Future attracted attention almost immediately. In what was an industry first, Google and In-Q-Tel (the investment arm of the US government) invested in the Boston-based company. Threat intelligence is a field defined by Recorded Future. The ability to process massive real time content flows and then identify hot spots and items of interest to a matter allows an authorized user to identify threats and take appropriate action quickly. Fueled by commercial events like the security breach at Sony and cyber attacks on the White House, threat detection is now a core business concern.
The impact of Recorded Future’s innovations on threat detection was immediate. Traditional methods relied on human analysts. These methods worked but were and are slow and expensive. The use of Google-scale content processing combined with “smart mathematics” opened the door to a radically new approach to threat detection. Security, law enforcement, and intelligence professionals understood that sophisticated mathematical procedures combined with a real-time content processing capability would deliver a new and sophisticated approach to reducing risk, which is the central focus of threat detection.
In the exclusive interview with Xenky.com, the law enforcement and intelligence information service, Hines told me:
Recorded Future provides information security analysts with real-time threat intelligence to proactively defend their organization from cyber attacks. Our patented Web Intelligence Engine indexes and analyzes the open and Deep Web to provide you actionable insights and real-time alerts into emerging and direct threats. Four of the top five companies in the world rely on Recorded Future.
Despite the blue ribbon technology and support of organizations widely recognized as the most sophisticated in the technology sector, Recorded Future’s technology is a response to customer needs in the financial, defense, and security sectors. Hines said:
When it comes to security professionals we really enable them to become more proactive and intelligence-driven, improve threat response effectiveness, and help them inform the leadership and board on the organization’s threat environment. Recorded Future has beautiful interactive visualizations, and it’s something that we hear security administrators love to put in front of top management.
As the first mover in the threat intelligence sector, Recorded Future makes it possible for an authorized user to identify high risk situations. The company’s ability to help forecast and spotlight threats likely to signal a potential problem has obvious benefits. For security applications, Recorded Future identifies threats and provides data which allow adaptive perimeter systems like intelligent firewalls to proactively respond to threats from hackers and cyber criminals. For law enforcement, Recorded Future can flag trends so that investigators can better allocate their resources when dealing with a specific surveillance task.
Hines told me that financial and other consumer centric firms can tap Recorded Future’s threat intelligence solutions. He said:
We are increasingly looking outside our enterprise and attempt to better anticipate emerging threats. With tools like Recorded Future we can assess huge swaths of behavior at a high level across the network and surface things that are very pertinent to your interests or business activities across the globe. Cyber security is about proactively knowing potential threats, and much of that is previewed on IRC channels, social media postings, and so on.
In my new monograph CyberOSINT: Next Generation Information Access, Recorded Future emerged as the leader in threat intelligence among the 22 companies offering NGIA services. To learn more about Recorded Future, navigate to the firm’s Web site at www.recordedfuture.com.
Stephen E Arnold, April 29, 2015
Digital Reasoning Goes Cognitive
April 16, 2015
A new coat of paint is capturing some tire kickers’ attention.
IBM’s Watson is one of the dray horses pulling the cart containing old school indexing functions toward the airplane hanger.
There are assorted experts praising the digital equivalent of a West Coast Custom’s auto redo. A recent example is Digital Reasoning’s embrace of the concept of cognitive computing.
Digital Reasoning is about 15 years old and has provided utility services to the US government and some commercial clients. “Digital Reasoning Goes cognitive: CEO Tim Estes on Text, Knowledge, and Technology” explains the new marketing angle. The write up reported:
Cognitive is a next computing paradigm, responding to demand for always-on, hyper-aware data technologies that scale from device form to the enterprise. Cognitive computing is an approach rather than a specific capability. Cognitive mimics human perception, synthesis, and reasoning capabilities by applying human-like machine-learning methods to discern, assess, and exploit patterns in everyday data. It’s a natural for automating text, speech, and image processing and dynamic human-machine interactions.
If you want to keep track of the new positioning text processing companies are exploring, check out the write up. Will cognitive computing become the next big thing? For vendors struggling to meet stakeholder expectations, cognitive computing sounds more zippy that customer support services or even the hyperventilating sentiment analysis positioning.

Lego blocks are pieces that must be assembled.
Indexing never looked so good. Now the challenge is to take the new positioning and package it in a commercial product which can generate sustainable, organic revenues. Enterprise search positioning has not been able to achieve this goal with consistency. The processes and procedures for cognitive computing remind me of Legos. One can assemble the blocks in many ways. The challenge will be to put the pieces together so that a hardened, saleable product can be sold or licensed.

Is there a market for Lego airplane assembled by hand? Vendors of components may have to create “kits” in order to deliver a solution a customer can get his or her hands around.
An unfamiliar function with a buzzword can be easy to sell to those organizations with money and curiosity. Jargon is often not enough to keep stakeholders and in the case of IBM shareholders smiling. A single or a handful of Lego blocks may not satisfy those who want to assemble a solution that is more than a distraction. Is cognitive computing a supersonic biplane or a historical anomaly?
This is worth watching because many companies are thrashing for a hook which will lead to significant revenues, profits, and sustainable growth, not just a fresh paint job.
Stephen E Arnold, April 16, 2015
-

- Subscribe to Beyond Search
Feature archive
News archive

-