

WCC Group and ImageWare
March 20, 2013
I saw a reference to a court filing by the law firm called San Diego IP Law Group LLP. You can find the document at the San Diego court as Case 3:13-cv-oo309-DMS-JMA. I took a quick look and it appeared that the a company in the search and content processing business is a party to the legal matter. The “defendant”, if I read the document correctly, is WCC Services US, Inc., a Delaware corporation owned by WCC Group BV in the Netherlands.
Here’s what WCC says about its company:
WCC is a high-end software company that automates the matching process by providing more accurate and intelligent results. Non-core activities such as client implementations are performed by qualified partners like Accenture or EDS. To maintain its stated company objectives, WCC recruits and retains a motivated, flexible and highly educated staff. The knowledge and passion of our people drives industry-leading innovation and delights customers with the quality of our products and support. WCC is committed to a transparent Corporate Governance structure, even as a privately-held company. The organization’s openness, internally and externally, gives stakeholders up-to-date information about WCC and its future course. Conservative accounting policies assure continuity of the company and clearly signal WCC’s reliability as a business partner.
The court document carries the phrase “Complain for patent infringement” with a demand for a jury trial. The court document references a number of patents; for example, US 7298873 and some others.
I just wanted to document the existence of this court document. Like the Palantir i2 Group dust up, these disputes about content processing are interesting to me. Once resolved, the information about the matter can disappear. Google, of course, does not like urls which fail to resolve. I don’t loud sirens. Like Google, there’s not much one can do about certain content going dark. Stuff happens whether Google or I like it.
Keep in mind that I don’t have a dog in this fight. I have been monitoring WCC Group’s information retrieval business, but the company has kept a low profile. I did try to contact the company a couple of years ago, but I was unable to get much traction.
WCC’s search system is called Elise. There are some public descriptions of the search related business at these links:
- Job matching
- An Elise solution for “PES” which I don’t recognize as a useful acronym for public employment services
- A case study for a German PES
The San Diego Law Group’s Web site is http://firm.sandiegoiplaw.com/. The WCC Web site (assuming I have located the correct Web destination) is http://www.wcc-group.com/.
Stephen E Arnold, March 20, 2013
eDiscovery: A Source of Thrills and Reduced Costs?
February 2, 2013
When I hear the phrase “eDiscovery”, I don’t get chills. I suppose some folks do. I read after dinner last night (February 1, 2013) “Letter From LegalTech: The Thrills of E-Discovery.” The author addresses the use of search and content processing technology to figure out which documents are most germane to a legal matter. Once the subset has been identified, eDiscovery provides outputs which “real” attorneys (whether in Bangalore or Binghamton) can use to develop their “logical” arguments.

A happy quack to
One interesting factoid bumps into my rather sharp assessment of the “size” of the enterprise search market generated by an azure chip out. The number was about $1.5 billion. In the eDiscovery write up, the author says:
Nobody seems to know how large the e-discovery market is — estimates range from 1.2 to 2.8 billion dollars — but everyone agree it’s not going anywhere. We’re never going back to sorting through those boxes of documents in that proverbial warehouse.
I like the categorical affirmative “nobody.” The point is that sizing any of the search and content processing markets is pretty much like asking Bernie Madoff type professionals, “How much in liquid assets do you have?” The answer is situational, enhanced by marketing, and believed without a moment’s hesitation.
I know the eDiscovery market is out there because I get lots of PR spam about various breakthroughs, revolutions, and inventions which promise to revolutionize figuring out which email will help a legal eagle win a case with his or her “logical” argument. I wanted to use the word “rational” in the manner of John Ralston Saul, but the rational attorneys are leaving the field and looking for work as novelists, bloggers, and fast food workers.
One company—an outfit called Catalyst Repository Systems—flooded me with PR email spam about its products. I called the company on January 31, 2013. I was treated in an offhand, suspicious manner by a tense, somewhat defensive young man named Mark, Monk, Matt, or Mump. At age 69, I have a tough time figuring out Denver accents. Mark, Monk, Matt, or Mump took my name and phone number. He assured me that his boss would call me back to answer my questions about PR spam and the product which struck me as a “me too.” I did learn that he had six years of marketing experience and that he just “push the send button.” I suggested that he may want to know to whom he is sending messages multiple times, he said, “You are being too aggressive.” I pointed out that I was asking a question just like the lawyers who, one presumes, gobbles up the Catalyst products. He took my name, did not ask how to spell it, wrote down my direct line and did not bother to repeat it back to me, and left me with the impression that I was out of bounds and annoying. That was amusing because I was trying hard to be a regular type caller.

A happy quack to Bitter Lawyer which has information about the pressures upon some in the legal profession. See http://www.bitterlawyer.com/i%E2%80%99m-unemployed-and-feel-ripped-off-by-my-ttt-law-school/
Mark, Monk, Matt, or Mump may have delivered the message and the Catalyst top dog was too busy to give me a jingle. Another possibility is that Mark, Monk, Matt, or Mump never took the note. He just wanted to get a person complaining about PR spam off the phone. Either way, Catalyst qualifies as an interesting example of what’s happening in eDiscovery. Desperation marketing has infected other subsectors of the information retrieval market. Maybe this is an attempt to hit in reality revenues of $1.5 billion?
Information Confusion: Search Gone South
January 26, 2013
I read “We Are Supposed to Be Truth Tellers.” I think the publication is owned by a large media firm. The point of the write up is that “real news” has a higher aspiration and may deal with facts with a smidgen of opinion.
I am not a journalist. I am a semi retired guy who lives in rural Kentucky. I am not a big fan of downloading and watching television programs. The idea that I would want to record multiple shows, skip commercials, and then feel smarter and more informed as a direct result of those activities baffles me.
Here’s what I understand:
A large company clamped down on a subsidiary’s giving a recording oriented outfit a prize for coming up with a product that allows the couch potato to skip commercials. The fallout from this corporate decision caused a journalist to quit and triggered some internal grousing.
The article addresses these issues, which I admit, are foreign to me. Here’s one of the passages which caught my attention:
CNET reporters need to either be resigning or be reporting this story, or both. On CNET. If someone higher up removes their content then they should republish it on their personal blogs. If they are then fired for that they should sue the company. And either way, other tech sites, including this one, would be more than happy to make them job offers.
I agree I suppose. But what baffles me are these questions:
- In today’s uncertain financial climate, does anyone expect senior management to do more than take steps to minimize risk, reduce costs, and try to keep their jobs? I don’t. The notion that senior management of a media company embraces the feel good methods of Whole Earth or the Dali Lama is out of whack with reality in my opinion.
- In the era of “weaponized information,” pay to play search traffic, and sponsored content from organizations like good old ArnoldIT—what is accurate. What is the reality? What is given spin? I find that when I run a query for “gourmet craft spirit” I get some darned interesting results. Try it. Who are these “gourmet craft spirit” people? Interesting stuff, but what’s news, what’s fact, and what’s marketing? If I cannot tell, how about the average Web surfer who lets online systems predict what the user needs before the user enters a query?
- At a time when those using online to find pizza and paradise, can users discern when a system is sending false content? More importantly, can today’s Fancy Dan intelligence systems from Palantir-likeand i2 Group-like discern “fake” information from “real” information? My experience is that with sufficient resources, these advanced systems can output results which are shaped by crafty humans. Not exactly what the licensees want or know about.
Net net: I am confused about the “facts” of any content object available today and skeptical of smart systems’ outputs. These can be, gentle reader, manipulated. I see articles in the Wall Street Journal which report on wire tapping. Interesting but did not the owner of the newspaper find itself tangled in a wire tapping legal matter? I read about industry trends from consulting firms who highlight the companies who pay to be given the high intensity beam and the rah rah assessments. Is this Big Data baloney sponsored content, a marketing trend, or just the next big thing to generate cash in a time of desperation. I see conference programs which feature firms who pay for platinum sponsorships and then get the keynote, a couple of panels, and a product talk. Heck, after one talk, I get the message about sentiment analysis. Do I need to hear from this sponsor four or five more times. Ah, “real” information? So what’s real?
In today’s digital world, there are many opportunities for humans to exercise self interest. The dust up over the CBS intervention is not surprising to me. The high profile resignation of a real journalist is a heck of a way to get visibility for “ethical” behavior. The subsequent buzz on the Internet, including this blog post, are part of the information game today.
Thank goodness I am sold and in a geographic location without running water, but I have an Internet connection. Such is progress. The ethics stuff, the assumptions of “real” journalists, and the notion of objective, fair information don’t cause much of stir around the wood burning stove at the local grocery.
“Weaponized information” has arrived in some observers’ consciousness. That is a step forward. That insight is coming after the train left the station. Blog posts may not be effective in getting the train to stop, back up, and let the late arrivals board.
Stephen E Arnold, January 26, 2013
Big Data and Search
January 1, 2013
A new year has arrived. Flipping a digit on the calendar prompts many gurus, wizards, failed Web masters, former real journalists, and unemployed English majors to identify trends. How can I resist a chrome plated, Gangnam style bandwagon? Big Data is no trend. It is, according to the smart set:
that Big Data would be “the next big chapter of our business history.
My approach is more modest. And I want to avoid silver-numbered politics and the monitoring business. I want to think about a subject of interest to a small group of techno-watchers: Big Data and search.
My view is that there has been Big Data for a long time. Marketers and venture hawks circle an issue. If enough birds block the sun, others notice. Big Data is now one of the official Big Trends for 2013. Search, as readers of this blog may know, experiences the best of times and the worst of times regardless of the year or the hot trends.
As the volume of unstructured information increases, search plays a part. What’s different for 2013 is that those trying to make better decisions need a helping hand, crutches, training wheels, and tools. Vendors of analytics systems like SAS and IBM SPSS should be in the driver’s seat. But these firms are not. An outfit like Palantir claims to be the leader of the parade. The company has snazzy graphics and $150 million in venture funding. Good enough for me I suppose. The Palantirs suggest that the old dudes at SAS and SPSS still require individuals who understand math and can program for the “end user”. Not surprisingly, there are more end users than there are SAS and SPSS wizards. One way around the shortage is to make Big Data a point-and-click affair. Satisfying? The marketers say, “For sure.”
A new opportunity arises for those who want the benefits of fancy math without the cost, hassle, and delay of dealing with intermediaries who may not have an MBA or aspire to be independently wealth before the age of 30. Toss in the health care data the US Federal government mandates, the avalanche of fuzzy thinking baloney from blogs like this one, and the tireless efforts of PR wizards to promote everything thing from antique abacuses to zebra striped fabrics. One must not overlook e-mail, PowerPoint presentations, and the rivers of video which have to be processed and “understood.” In these streams of real time and semi-fresh data, there must be gems which can generate diamond bright insights. Even sociology major may have a shot at a permanent job.
The biggest of the Big Berthas are firing away at Big Data. Navigate to “Sure, Big Data Is Great. But So Is Intuition.” Harvard, MIT, and juicy details explain that the trend is now anchored into the halls of academe. There is even a cautionary quote from an academic who was able to identify just one example of Big Data going somewhat astray. Here’s the quote:
At the M.I.T. conference, a panel was asked to cite examples of big failures in Big Data. No one could really think of any. Soon after, though, Roberto Rigobon could barely contain himself as he took to the stage. Mr. Rigobon, a professor at M.I.T.’s Sloan School of Management, said that the financial crisis certainly humbled the data hounds. “Hedge funds failed all over the world,” he said. THE problem is that a math model, like a metaphor, is a simplification. This type of modeling came out of the sciences, where the behavior of particles in a fluid, for example, is predictable according to the laws of physics.
Sure Big Data has downsides. MBAs love to lift downsides via their trusty, almost infallible intellectual hydraulics.
My focus is search. The trends I wish to share with my two or three readers require some preliminary observations:
- Search vendors will just say they can handle Big Data. Proof not required. It is cheaper to assert a technology than actually develop a capability.
- Search vendors will point out that sooner or later a user will know enough to enter a query. Fancy math notwithstanding, nothing works quite like a well crafted query. Search may be a commodity, but it will not go away.
- Big Data systems are great at generating hot graphics. In order to answer a question, a Big Data system must be able to display the source document. Even the slickest analytics person has to find a source. Well, maybe not all of the time, but sometimes it is useful prior to a deposition.
- Big Data systems cannot process certain types of data. Search systems cannot process certain types of data. It makes sense to process whatever fits into each system’s intake system and use both systems. The charm of two systems which do not quite align is sweet music to a marketer’s ears. If a company has a search system, that outfit will buy a Big Data system. If a company has a Big Data system, the outfit will be shopping for a search system. Nice symmetry!
- Search systems and Big Data systems can scale. Now this particular assertion is true when one criterion is met; an unending supply of money. The Big Data thing has a huge appetite for resources. Chomp. Chomp. That’s the sound of a budget being consumed in a sprightly way.
Now the trends:
Trend 1. Before the end of 2013, Big Data will find itself explaining why the actual data processed were Small Data. The assertion that existing systems can handle whatever the client wants to process will be exposed as selective content processing systems. Big Data are big and systems have finite capacity. Some clients may not be thrilled to learn that their ore did not include the tonnage that contained the gems. In short, say hello to aggressive sampling and indexes which are not refreshed in anything close to real time.
Trend 2. Big Data and search vendors will be tripping over themselves in an effort to explain which system does what under what circumstances. The assertion that a system can do both structured and unstructured while uncovering the meaning of the data is one I want to believe. Too bad the assertion is mushy in the accuracy department’s basement.
Trend 3.The talent pool for Big Data and search is less plentiful than the pool of art history majors. More bad news. The pool is not filling rapidly. As a result, quite a few data swimmers drown. Example: the financial crisis perhaps? The talent shortage suggests some interesting cost overruns and project failures.
Trend 4. A new Big Thing will nose into the Big Data and search content processing space. Will the new Big Thing work? Nah. The reason is that extracting high value knowledge from raw data is a tough problem. Writing new marketing copy is a great deal easier. I am not sure what the buzzword will be. I am pretty sure vendors will need a new one before the end of 2013. Even PSY called it quits with Gangnam style. No such luck in Big Data and search at this time.
Trend 5. The same glassy eyed confusion which analytics and search presentations engender will lead to greater buyer confusion and slow down procurements. Not even the magic of the “cloud” will be able to close certain deals. In a quest for revenue, the vendors will wrap basic ideas in a cloud of unknowing.
I suppose that is a good thing. Thank goodness I am unemployed, clueless, and living in a rural Kentucky goose pond.
Stephen E Arnold, January 1, 2012
Another Beyond Search analysis for free
Visualization Woes: Smart Software Creates Human Problems
December 10, 2012
I am not dependent on visualization to figure out what data imply or “mean.” I have been a critic of systems which insulate the professional from the source information and data. I read “Visualization Problem”. The article focuses on the system user’s inability to come up with a mental picture or a concept. I learned:
I know I am supposed to get better with time, but it feels that the whole visualization part shouldn’t be this hard, especially since I can picture my wonderland so easily. I tried picturing my tulpa in my wonderland, in black/white voids, without any background, even what FAQ_man guide says about your surroundings, but none has worked. And I really have been working on her form for a long time.
A “tulpa” is a construct. But the key point is that the software cannot do the work of an inspired human.
The somewhat plaintive lament trigger three thoughts about the mad rush to “smart software” which converts data into high impact visuals.
First, a user may not be able to conceptualize what the visualization system is supposed to deliver in the first place. If a person becomes dependent on what the software provides, the user is flying blind. In the case of the “tulpa” problem, the result may be a lousy output. In the case of a smart business intelligence system such as Palantir’s or Centrifuge Systems’, the result may be data which are not understood.
Second, the weak link in this shift from “getting one’s hands dirty” by reviewing data, looking at exceptions, and making decisions about the processes to be used to generate a chart or graph puts the vendor in control. My view is that users of smart software have to do more than get the McDonald’s or KFC’s version of a good meal.
Third, with numerical literacy and a preference for “I’m feeling lucky” interfaces, the likelihood of content and data manipulation increases dramatically.
I am not able to judge a good “tulpa” from a bad “tulpa.” I do know that as smart software diffuses, the problem software will solve is the human factor. I think that is not such a good thing. From the author’s pain learning will result. For a vendor, from the author’s pain motivation to deliver predictive outputs and more training wheel functions will be what research and develop focuses upon.
I prefer a system with balance like Digital Reasoning’s: Advanced technology, appropriate user controls, and an interface which permits closer looks at data.
Stephen E Arnold, December 10, 2012
An ElasticSearch Feature Comparison: Where Is the Beef?
November 15, 2012
There is an interesting but somewhat incomplete “feature comparison” between Solr and ElasticSearch. ElasticSearch, as you may know, is the new $10 million darling of the search world. Well, maybe Attivio with $42 million or Palantir with $150 million is “darlinger”?
You can find the write up at “Apache Solr vs ElasticSearch.” I want to point out that the comments to the basic information are quite useful. Among the points included in the comments which I found helpful were:
- The notion of dynamic fields, field copying via multi-fields, and alternative query parsers
- A reference to DataStax, Cassandra, and Solr
- A suggestion that an eZ Publish reference be added.
However, I want to point out that in our analysis of ElasticSearch, there is one big factor not embraced by a feature list. Organizations want a system which is easy to install, maintain, and extend. Cost is a big deal, but when one factors in the costs associated with start up companies, there may be less predictability than with more established open source vendors such as Attivio, IBM, LucidWorks, and others.
As a side note, the publisher of the first three editions of the Enterprise Search Report, which I wrote, I had to produce nearly 20 feature charts. Guess what? Most of the feature charts were identical on the main points. The differences were of great technical importance to developers at the vendors’ firms. However, to the companies licensing software, the decisive factors were usually based on business considerations; for example:
- Customer live demos and references from these customers
- Pricing including support and training
- Business stability
- Engineering depth of the vendor
- Financial performance over time
- Management experience.
The fact that one vendor’s approach to k-means was “faster”, the metatagging system was “self learning”, or that another vendor’s system could index 10 gigabytes of content in X time slices was often irrelevant as decision time. Maybe open source search will be different, but right now, the open source world is on a vector that leads to the same business models which the traditional proprietary software vendors used with varying degrees of success?
In my view, a company in growth mode is juggling many balls at once and riding a unicycle. Consequently, the marketing and developer hyperbole may distract from the pure business considerations which garnered Attivio four times the funding that ElasticSearch obtained. The downside is that Attivio has to generate sufficient revenue to hit financial targets. Some financial types want five, 10, or 17 times the investment. I am too old and frail for that type of pressure. Even a $10 million cash infusion works out to $50, $170, or $100 million in revenues.
Only a handful of the 50 search vendors I track have revenues in shouting distance of $50 million. On a call with some MBA types last week, I learned that blowing past the revenues of Autonomy, Endeca, and Fast Search before their sale or implosion, was a “no brainer.”
I am not so sure. Building and sustaining revenue is more than a feature punch list. The real challenge is building and sustaining a business. Look at the present situation for HP Autonomy. Fast Search is, in my opinion, an end of life product. Endeca is an “all things to all people” solution. Endeca is darned good at eCommerce and processing certain types of data sets.
Open source software is important. Open source search is important too. What is more important is the constellation of factors that make “free” software into a viable commercial product which delivers a return to its funding sources. Will the open source community cheerlead when the VCs force the innovators who took those millions to produce a hefty profit? More than marketing and feature lists are needed. Just my opinion.
You can purchase the ElasticSearch analysis at this link for $3,500. Why so much? IDC has to generate revenue and return a profit. My hunch is that this is a fact of economic life that some open source code surfers do not yet hug and cuddle every hour or two.
Stephen E Arnold, November 14, 2012
What Is the Most Deployed Search System in the World?
September 26, 2012
I just had a brief chat with LucidWorks. In that call, I learned about a surprising fact presented in the Forbes’ article “LucidWorks: Bringing Search to Big Data.” Here’s the point I noted:
Lucene/Solr is the most deployed search technology in the world, used by companies such as Netflix, AT&T, Sears, Ford, and Verizon. According to Ingersoll, Twitter search is powered by Lucene, handling more than a billion queries a day, with close to four hundred million tweets indexed and available within 50 milliseconds of being posted (see here for a 2010 post about Lucene by the Twitter engineering team).
There may be many search options. Some are free and spin outs of university or personal research projects (Elasticsearch, SearchBox). Others are well backed start ups (Palantir, Centrifuge Systems). Some are hybrids (Basho and Datastax).
If Forbes is correct, there is one vendor poised to disrupt search, analytics, and content processing—LucidWorks. More about this Forbes article in a day or two.
Don C Anderson, September 26, 2012
Sponsored by Augmentext
Attivio vs Sinequa: Who Does What?
September 12, 2012
When I was assembling the Attivio company profile for IDC (http://www.idc.com/getdoc.jsp?containerId=236514), I noted a catchphrase conflict. I ran the query “unified information access” and got a hit on Wikipedia. The phrase seems to have been coined by Sue Feldman, an IDC expert in search. The phrase “unified information access” is also strongly linked to Attivio within a Google search results list. In our research for the IDC Attivio profile, Attivio had made extensive use of the phrase for several years.
What was interesting was that we noticed that Sinequa, a vendor of enterprise search technology, was using the same phrase. You can see Sinequa’s use of the phrase in the banner of the Sinequa Web site.
Other companies are using the phrase as well; for example, BA-Insight, Endeca, Exalead, MarkLogic, PerfectSearch, and Palantir.
What is the value of a phrase if a number of vendors use it to describe what their systems deliver? Does this create confusion? Can Attivio’s strong grip on the phrase be eroded? Like “search enabled applications,” a phrase can lose its meaning when a number of companies use it. The words “search,” “information,” “big data,” “taxonomy,” and “semantics” have become almost impossible to define. Marketers “assume” that the words are understood by the reader or listener. Are they?
Search and content processing vendors continue to “look alike.” Little wonder. Each company seems to be piggybacking on other wordsmiths’ positioning ideas. Unlike Apple Samsung, there is no physical product involved. The words, therefore, are probably more easily repurposed and shaped. Does this help one understand what a company’s products actually do?
My view is that search, analytics, and content processing vendors are repeating the marketing approach which helped make traditional enterprise search vendors into almost identical systems.
Are the systems identical? In my experience, the systems are quite different, but licensees do not know what difference is meaningful until the license deal has been signed and the license fee paid. Is differentiation no longer important? I thought a unique selling proposition was important, but with vendors recycling terminology, perhaps the USP is old school, and, therefore, irrelevant.
Stephen E Arnold, September 12, 2012
Sponsored by Augmentext
Making Data Easy with Training Wheels? The Nielsen Dust Up
July 31, 2012
In the Honk newsletter, I have been plugging away at some of the flights of fancy that surround big data, next generation analytics, and all things predictive. I am nervous about “training wheels” on complex mathematical processes. Like the fill-in-the-blanks functions in Excel, a person without a foundation in math can fiddle around until the software spits out a number which “looks good.” In one of my jobs, my boss was a master at “the flow.” The idea was that numbers can be shaped to support a particular point. I recall his comment to me in 1974, “Most of our clients are not smart enough to work through the math. We have to generate outputs which flow.” The idea is one that troubled me. I moved on to greener and less slippery pastures and I kept that notion of “flow” squarely in mind. Numbers should not cause the person looking at a chart or a table to say, “Wow, that number looks weird.” Hence, flow allows the reasoning process to be guided.
I just read a story which I hope is not accurate. I want to document my coming across the item, however. I think it will be an interesting touchstone and search and content processing companies race to be come players in big data and analytics. The story appeared in the Hollywood Reporter, a publication about which I know little. The headline caught my attention because it resonates with advertising and advertising automatically evokes the Google logo for me. “Nielsen Sued for Billions over Allegedly Manipulated TV Ratings” carries a hard hitting subtitle too: “In a huge new lawsuit, the business of TV ratings is fingered for rampant corruption by India’s largest TV news network.” I know even less about India than the Hollywood Reporter.
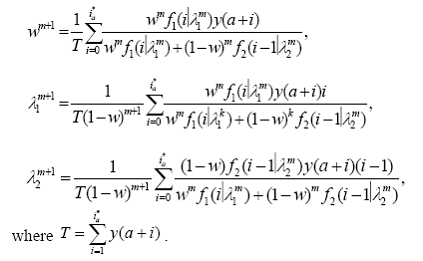
Fancy math underlies the products and services of many analytics firms which offer products and services to licensees that make interacting with data a matter of pointing and clicking. A happy quack for the equation to http://goo.gl/lBlXV
Here’s the passage I noted:
In a 194-page lawsuit filed in New York court late last week, NDTV accuses Nielsen of violating the Foreign Corrupt Practices Act by manipulating viewership data in favor of channels that are willing to provide bribes to its officials. According to NDTV, rampant manipulation of viewership data has been going on for eight years, and when presented with evidence earlier this year, top executives at Nielsen pledged to make changes. But the Indian news giant says these promises have been false ones.
Like most litigation, the story will unfold slowly and perhaps not at all. The i2 Group Palantir litigation is a relatively recent example. Based on my experience with the boss who wanted numbers to flow, I can see how the possibility of tweaking could be useful to some companies. However, with the dismal state of math skills, how can I now of the problem was a result of human intent, human error, or a training wheels type system driven over rocky terrain. I can’t and I bet that most people thinking about this situation cannot either.
What is interesting to me, however, are these notions:
- How many other fancy math systems are open to similar allegations from their licensees?
- Will this type of legal action cause some of the vendors pitching fancy math and predictive systems to modify their marketing materials to include more caveats and real world anchors instead of bold assertions?
- How will the legal system deal with fancy math litigation? I don’t know many attorneys. The handful with which I have some experience have been quick to point out that math, engineering, and science were not their strengths. Logic and reasoning were their strong suits.
With many search and content processing companies embracing fancy math, sentiment analysis, smart indexing and other math-based functions, will a search vendor find itself in the hot seat? I hope not but the market wants to buy fancy math. Understanding the fancy math may drive demand for individuals who can figure out if the systems and methods do what the licensee believes they do.
Oh, I like the word “billions.” Big money adds to the drama of analytics risk management in my opinion.
Stephen E Arnold, July 31, 2012
Now Business Intelligence Is Dead
July 18, 2012
I received a “news item” from Information Enterprise Software, an HTML email distributed by InformationWeek Software. The story was labeled “Commentary.” I did not think that “real” journalists engaged in “commentary.” Isn’t there “real” news out there to “cover” or “make.”
Read the article. Navigate to “If BI Is Dead, What’s Next?” The “commentary” is hooked to an azure chip consultant report called “BI Is Dead! Long Live BI” which costs a modest $250. You can buy this document from Constellation Research here. First, let’s look at the summary of the report and then consider the commentary. I want to wrap up with some blunt talk about analytic baloney which is winging through the air.
Here’s the abstract so get your credit card ready:
We [Constellation Research] suggest a dozen best practices needed to move Business Intelligence (BI) software products into the next decade. While five “elephants” occupy the lion’s share of the market, the real innovation in BI appears to be coming from smaller companies. What is missing from BI today is the ability for business analysts to create their own models in an expressive way. Spreadsheet tools exposed this deficiency in BI a long time ago, but their inherent weakness in data quality, governance and collaboration make them a poor candidate to fill this need. BI is well-positioned to add these features, but must first shed its reliance on fixed-schema data warehouses and read-only reporting modes. Instead, it must provide businesspeople with the tools to quickly and fully develop their models for decision-making.
I like the animal metaphors. I must admit I thought more in terms of baloney, but that’s just an addled goose’s reaction to “real” journalism.
The point is that business intelligence (I really dislike the BI acronym) can do a heck of a lot more. So what’s dead? Excel? Nah. Business intelligence? Nah. A clean break with the past which involved SAS, SPSS, and Cognos type systems? Nah.

Information about point and click business intelligence should be delivered in this type of vehicle. A happy quack to the marketing wizard at Oscar Mayer for the image at http://brentbrown98.hubpages.com/hub/12-of-the-Worst-Sports-Logos-Ever
So what?
Answer: Actually not a darned thing. What this report has going for it is a shocking headline. Sigh.
Now to the “commentary.” Look a pay to play report is okay. The report is a joint work of InformationWeek and the Constellation report. Yep, IDC is one of the outfits involved in the study. The “commentary” is pretty much a commercial. Is this “real” journalism? Nah, it is a reaction to a lousy market for consulting studies and an attempt to breathe controversy into a well known practice area.
Here’s the passage I noted:
We all saw the hand wringing in recent years over BI not living up to its promise, with adoption rates below 20% or even 10% of potential users at many enterprises. But that’s “probably the right level” given the limitations of legacy BI tools, says Raden. I couldn’t agree more, and I’ve previously called for better ease of use, ease of deployment, affordability, and ease of administration. What’s largely missing from the BI landscape, says Raden, is the ability for business users to create their own data models. Modeling is a common practice, used to do what-if simulation and scenario planning. Pricing models, for instance, are used to predict sales and profits if X low-margin product is eliminated in hopes of retaining customers with products A, B, and C.
So what we are learning is that business intelligence systems have to become easier to use. I find this type of dumbing down a little disturbing. Nothing can get a person into more business trouble faster than fiddling around with numbers and not understanding what the implications of a decision are. Whether it is the fancy footwork of a Peregrine or just the crazy US government data about unemployment, a failure to be numerically literature can have big consequences.
-

- Subscribe to Beyond Search
Feature archive
News archive

-