

Look No Further for Oracle Documentation
December 9, 2013
Oracle prides itself on its Secure Enterprise Search that is advertised as offering secure, high quality search that easily works across all information sources on the enterprise format. The search product digs deep in local, private, and shared files housed on databases, intranets, document management systems, applications, and portals. With great ease it crawls and indexes results, guaranteeing that the first items in the results list are the most relevant. Also the Secure Enterprise Search offers analytics on search results and usage patterns.
Oracle provides current and prospective clients with “Oracle Secure Enterprise Search Documentation.” Oracle has released the 11g version of the Secure Enterprise Search with the following key assets:
· “Highly secure crawling, indexing, and searching
· A simple, intuitive search interface with browsing and display of search results by automatically-extracted topic and metadata attribute clusters
· Excellent search quality, with the most relevant items for a query shown first, even when the query spans diverse public or private data sources
· Analytics on search results and understanding of usage patterns
· Sub-second query performance
· Ease of administration and maintenance leveraging your existing IT expertise.”
Oracle continues to be one of the reliable enterprise searches, but like most software these days it faces strong competition from open source technology.
Whitney Grace, December 09, 2013
Sponsored by ArnoldIT.com, developer of Augmentext
Search and Crowdsourcing: Verbase via Hong Kong
December 6, 2013
Short honk: You may wonder what a crowd sourced search engine is. If you poke around the mainstream Web indexes like Google and Bing, there are some tantalizing clues. Blekko and DuckDuckGo have used the word “crowd sourced” to entice users. With a bit more digging you may come across a search engine from Verbase. The news release, issued in October 2013, explains the notion in this way:
Powered by human intelligence, Verbase delivers more direct results for text-based searches, and enables users to add comments and original content to search results. Verbase is currently receiving over 50,000 unique monthly visitors to its site.
Google is mostly algorithms, most of the time. Rumors of humans tinkering with the giant’s findability system drift around, but Google likes nests of numerical recipes. Humans are, well, human, slow, and often prone to playing volleyball and sleeping.

A Verbase results screen for the query “Fulcrum Technologies Ful/Text”.
The Verbase approach uses three methods:
- A search box that offers category filters. (These look like the Blekko “slash” functions.)
- What the company calls an “automatic user ranking algorithm” that considers “engagement.” (Perhaps this means clicking and the time spent in a results list?)
- A “micro content” function that allows a user to create content. (Does this echo Vivisimo’s approach on steroids?)
According to the news release:
Founded by serial entrepreneur Antoine Sorel Neron, Verbase is a semantic search engine powered by human intelligence that relieves user frustration associated with spam, advertising, and irrelevant search results.
Several observations:
First, Google’s utility is not what it used to be. Search is not about precision and recall. Search is the source of money that funds synthetic biology investments and systems that are tuned to deliver brand advertising. Verbase is one company willing to point out that Google generates results that are sometimes less than useful to online searchers.
Second, Verbase is, like many other Web search companies, hitting some hot buttons to generate interest; for example, crowd sourcing. This is a good idea if methods exist to cope with the issues associated with uncontrolled indexing and content.
Third, the location of the company appears to be Hong Kong. Is this one more example of the center of technology starting to tip somewhere other than longitude of Highway 101?
The system is worth a look. My test queries returned useful results. The graphic approach reminded me of Exalead’s Web search system from three or four years ago. I noted that the system handled an odd ball product name “Ful/Text” reasonably well. Some competitors’ systems insisted that I really wanted “full text.” Wrong.
Verbase brought a smile to my face by returning results that I judged “relevant.” Worth a test drive.
Stephen E Arnold, December 6, 2013
A Search Library for Python
December 6, 2013
Python is one of the many programming languages available. Programmers rely on already existing libraries and open source to help them create new projects. Bitbucket points our attention to “Whoosh-Python Search Library” that appears to be a powerful open source solution to satisfy you search woes.
The article states:
“Whoosh is a fast, featureful full-text indexing and searching library implemented in pure Python. Programmers can use it to easily add search functionality to their applications and websites. Every part of how Whoosh works can be extended or replaced to meet your needs exactly.”
What can Whoosh do? It has fielded indexing, fast indexing and retrieval, a powerful query language, the only production quality pure Python spell-checker, pluggable scoring algorithm, and a Pythonic API. Whoosh was built to handle situations where the programmer needs to avoid creating native libraries, make a research platform, provides one deeply-integrated search solution, and has an easy-to-use interface.
Whoosh started out as a search solution for proprietary software. Matt Chaput designed it for Side Effects Software Inc.’s animation software Houdini. Side Effects Software allowed Chaput to release the library to the open source community and many Python programmers probably consider it an early Christmas gift.
Whitney Grace, December 06, 2013
Sponsored by ArnoldIT.com, developer of Augmentext
Yahoo and Search: Innovation or PR?
December 4, 2013
I read “You Are the Query: Yahoo’s Bold Quest to Reinvent Search.” The write up explains that “search” is important to Yahoo. The buzzwords personalization and categorization make an appearance. There is no definition of “search.” So the story suggests that the new direction may be a “feed”, a stream of information. The passage I noted is:
So what is Yahoo building? To wit, the company is working on a new “personalization platform,” according to the LinkedIn profile of one Yahoo senior director. Cris Luiz Pierry, the director who headed up Yahoo’s now-shuttered Flipboard clone Livestand, writes that he is heading up a “stealth project,” and that he is “building the best content discovery and recommendation engine on the Web, across all of our regions.” Pierry also has an in-the-weeds search background, with experience in core Web search, ranking algorithms, and e-commerce software — which may come in handy when dealing with monetization.
A stealth search project. Didn’t Fulcrum Technologies operate in this way between 1983 and its run up to a much needed initial public offering in the early 1990s? Wasn’t the newcomer SRCH2 in stealth mode earlier in 2013?
The hook to the new approach may be nestled within this comment in the article:
That search experience would likely be layered on top of another company’s Web crawler, like Microsoft’s Bing, which took over those operations for Yahoo in 2010, as part of a 10-year deal. (More on that later.) Beginning in 2008.
Indexing the Web is an expensive proposition. No commercial publisher can afford it. Google is able to pull it off via its Yahoo-inspired ad model. Yandex is struggling to find monetization methods that allow it to keep its indexes fresh. But other Web indexers have had to cut back on coverage. Exalead’s Web index is thin gruel. Blekko has lost its usefulness for me. In fact, looking for information is now more difficult that it has been for a number of years.
Another interesting comment in the article jumped off the screen for me; to wit:
We firmly believe that the Search Product of tomorrow will not be anything alike [sic] the product that we are used to today,” says the job description for the search architect. The posting also name-checks Search Direct, Yahoo’s version of Google Instant, as the “first step” in changing the landscape of search. After testing out a few queries on Yahoo’s home page, the feature, which looks up queries without requiring the user to hit “search,” looks to be dormant.
The write up concludes with this speculative paragraph:
Some theories: The company could be planning a Bing exit strategy for 2015 or earlier, and look to partner with another Web crawler, aka Google. Some reports have said Mayer has been cozying up to her former company on that front. Or Yahoo could be rebuilding its own core search capabilities, though that’s the unlikeliest of scenarios because that would be a nightmare for the company’s margins. Or Yahoo could even be beefing up its team just enough to gain more authority within the Bing partnership, in case it wanted to advise Bing on what to do on the back end.
What I find interesting is that the term “search” is not really defined in this write up or most of the information I see that address findability. I am not sure what “search” means for Yahoo. The company has a history of listing sites by categories. Then the company indexed Web sites. Then the company used other vendors’ results. What’s next? I am not sure.
Observations? I have a few:
First, anyone looking for specific information has a tough job on their hands today. In a conversation with two experts in information retrieval, both mentioned that finding historical information via Web search systems was getting more difficult.
Second, queries run by different researchers return different results. The notion of comparative searching is tricky.
Third, with library funding shrinking, access to commercial databases is dwindling. For example, in Kentucky, patrons cannot locate a company news release from the 1980s using public library services.
The article about Yahoo is less about search and more about public relations. Is Yahoo or any vendor able to do something “new” in search? Without defining the term “search,” does it matter to the current generation of experts?
Personally I don’t want to influence a query. I want to locate information that is germane to a query that I craft and submit to an information retrieval system. Then I want to review results lists for relevant content and I want to read that information, analyze the high value information, synthesize it, and move on about my business.
I want to control the query. I don’t want personalization, feeds, or predictive analytics clouding the process. Does “search” mean thinking or taking what a company wants to provide to advance its own agenda?
Stephen E Arnold, December 4, 2013
SchemaLogic Profile Available
December 3, 2013
A new profile is available on the Xenky site today. SchemaLogic is a controlled vocabulary management system. The system combines traditional vocabulary management with an organization wide content management system specifically for indexing words and phrases. The analysis provides some insight into how a subsystem can easily boost the cost of a basic search system’s staff and infrastructure.
Taxonomy became a chrome trimmed buzzword almost a decade ago. Indexing has been around a long time, and indexing has a complete body of practices and standards for the practitioner to use when indexing content objects.
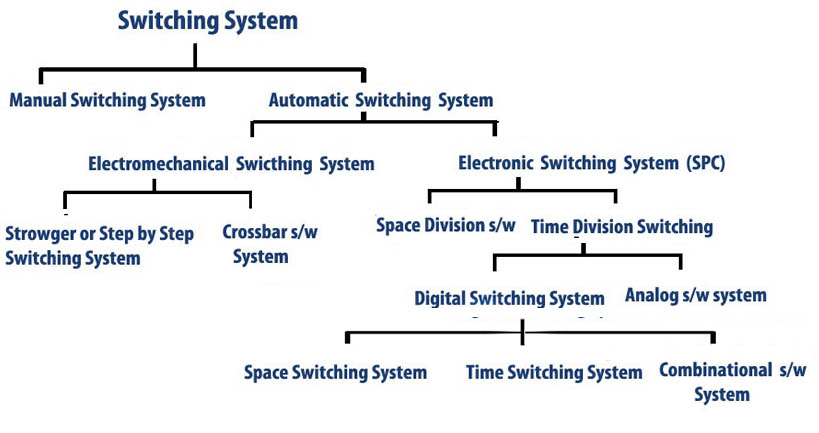
Just what an organization needs to make sense of its text, images, videos, and other digital information/data. At a commercial database publsihing company, more than a dozen people can be involved in managing a controlled term list and classification coding scheme. When a term is misapplied, finding a content object can be quite a challenge. If audio or video are misindexed, the content object may require a human to open, review, and close files until the required imnage or video can be located. Indexing is important, but many MBAs do not understand the cost of indexing until a needed content object cannot be found; for example, in a legal discovery process related to a patent matter. A happy quack to http://swissen.in/swictingsys.php for the example of a single segment of a much larger organization centric taxonomy. Consider managing a controlled term list with more than 20,000 terms and a 400 node taxononmy across a Fortune 500 company or for the information stored in your laptop computer.
Even early birds in the search and content processing sector like Fulcrum Technologies and Verity embraced controlled vocabularies. A controlled term list contains forms of words and phrases and often the classification categories into which individual documents can be tagged.
The problem was that lists of words had to be maintained. Clever poobahs and mavens created new words to describe allegedly new concepts. Scientists, engineers, and other tech types whipped up new words and phrases to help explain their insights. And humans, often loosey goosey with language, shifted meanings. For example, when I was in college a half century ago, there was a class in “discussion.” Today that class might be called “collaboration.” Software often struggles with these language realities.
What happens when “old school” search and content processing systems try to index documents?
The systems can “discover” terms and apply them. Vendors with “smart software” use a range of statistical and linguistic techniques to figure out entities, bound phrases, and concepts. Other approaches include sucking in dictionaries and encyclopedias. The combination of a “knowledgebase” like Wikipedia and other methods works reasonably well.
Healthcare.gov Blog: Content Gap?
November 20, 2013
Healthcare.gov has a blog. You can find it at this link. There is a link for October posts. There is a link for September posts. I was not able to access the full set of posts for either month. Here’s what I saw:

I thought the content would be at this link.
Oversight, content management problem, content removal, or my error? Interesting. It is tough to search when content is not available for indexing.
I wanted to read the posts to the blog before and after the launch. No joy. Should I be suspicious?
Stephen E Arnold
Thunderstone Thunders In With An Upgrade
November 18, 2013
While this might not be at the top of anyone’s Black Friday shopping list, it is good to know that ‘Thunderstone Offers Version 9 Of The Thunderstone Search Appliance” according to PR Web. Thunderstone is a little known research and development company that prides itself on providing comprehensive intelligent information and retrieval management solutions. One might recognize their Texis software that provides high-grade text retrieval and publishing.
Thunderstone’s products are used in various fields from multimedia management; help desk support, automated categorization, litigation support, and Web content searching.
The last field is of the greatest interest to us, because the Thunderstone Search Appliance could push the company into a wider range of clients. The upgrade promises to support all of its sister software with improved administrative interface, faster searching, query auto complete, content caching, and a walk log for analysis. Those are just the basic upgraded features.
Thunderstone includes the following benefits with their search software:
· “A one-time, perpetual license that saves customers 40-60 percent (or more) compared to Thunderstone’s closest competitor.
· Two years of included maintenance, easily extended for additional years at affordable annual rates.
· Superior technical support from software engineers readily accessible to customers by phone, email and message board.
· No restrictions on indexing third-party websites for user-empowering applications and for competitive intelligence purposes.
· Ability to fully search targeted repositories (file servers, web servers, intranet/portal servers, database servers, application databases, etc.) and to handle files that exceed 30 MB in size.
· An attractive Product Investment Protection Program that makes upgrading a breeze, applying 100 percent of the initial Thunderstone product’s purchase price to any desired upgrade.
· Availability as a virtual appliance image to run under a hypervisor to allow for more efficient hardware utilization and manageability.”
These are not bad options. However, having never worked with Thunderstone or even heard of it before this press release we have to question its performance capabilities. Does it really do as advertised or is an extended amount of development needed for implementation?
Whitney Grace, November 18, 2013
Sponsored by ArnoldIT.com, developer of Augmentext
MarkLogic Recognized for Database Management
November 13, 2013
We already knew that MarkLogic is good at search. Now the company is being recognized for its database management chops, we learn from “MarkLogic Featured in the Gartner Magic Quadrant for Operational Database Management Systems” at BWW Geeks World.
The press release tells us:
“MarkLogic has been positioned for its ability to execute and is the only Enterprise NoSQL database vendor featured in the report that integrates search and application services. . . .
MarkLogic is the only schema-agnostic Enterprise NoSQL database that integrates semantics, search and application services with the enterprise features customers require for production applications. This combination helps enterprises make better-informed decisions and create robust, scalable applications to drive revenue, streamline operations, manage risk and make the world safer. MarkLogic features ACID transactions, horizontal scaling, real-time indexing, high availability, disaster recovery, and government-grade security.”
CEO Gary Bloom does not let us forget his company’s search success. He points out that they also captured a place on Gartner‘s 2013 Magic Quadrant for Enterprise Search roster, and that they are the only company to be included in both reports. He understandably takes this achievement as evidence that MarkLogic is on the right track with its integrated approach. The company focuses on scalability, enterprise-readiness, and leveraging the latest technology. Founded in 2001, MarkLogic is headquartered in Silicon Valley and maintains offices around the world.
Cynthia Murrell, November 13, 2013
Sponsored by ArnoldIT.com, developer of Augmentext
Xenky Vendor Profiles: Siderean Software Now Available
November 12, 2013
If you are a fan of semantic methods, you may find the Siderean Software profile a useful case study. You can find the write up, among others, at this location. The chatter at conferences about semantic methods is finally burning out. Nevertheless, semantic methods bubble beneath the surface of many modern search systems. The Siderean case is an example of what types of content processing operations are required to perform “deep indexing” or “rich metadata extraction.” The first step, as you will learn, is to have content tagged. That means SGML or XML.
The question becomes, “How do I get my content into these formats?” The answer, for many budgets, is a deal breaker. One the content is processable, then a number of manipulations are possible. Think of Siderean’s system as delivering the type of flip and flop of data that Excel provides in its pivot table. Now ask yourself, “How often do I use a pivot table?” Exactly.
Remember. I am posting pre-publication drafts of analyses that may have been used, recycled, or just ripped off by various “real” publishers over the years. If there are errors in these drafts, you can “correct” them by adding a comment to this post in Beyond Search. The archive of case studies or profiles will not be updated.
I am providing these for personal use. If a frisky soul wants to use them for commercial purposes, I will take some type of action. If you were in my lecture at the enterprise search conference in New York last week, you will know that I called attention to one of the most slippery of the azure chip consulting firms. I showed a slide that listed the same “expert” twice on a $3,500 report. Not bad, since the outfit’s expert did not create the information in the report.
Stephen E Arnold, November 12, 2013
Perspective Search Now Part of Jive Platform
November 6, 2013
Perceptive Software is working with social collaboration firm Jive, we learn from “Perceptive Software Brings Enterprise Search App to Jive Apps Market” at PRWeb. Perceptive Search has been integrated into Jive’s platform, and is available as an app through the Jive Apps Market. The press release reports:
“The Perceptive Enterprise Search App provides companies using Jive with a powerful enterprise search tool to eliminate information silos and aggregate content across multiple repositories, including SharePoint, ECM solutions, traditional file shares, legacy Lotus Notes databases, and others. The app is fully functional right out of the box, readily indexing—and giving users access to—content across multiple repositories and scaling to accommodate spikes in volume.
“The app empowers users to explore data relationships through analytical, reporting and visualization features, giving businesses more opportunity to identify trends and drive value from their content. Such value may be realized in the form of more efficient product development, customer service, marketing and more.”
Perceptive CTO Brian Anderson notes that his company uses Jive with Perspective Search for their own employees, and reports that the app has sped up their own searches. The platform’s analysis, reporting, and visualization features remove those chores from users’ to-do lists, allowing more time to act on resulting insights, he says.
Acquired by Lexmark in 2010, Perceptive Software offers a range of process- and content-management solutions. In business since 1995, Perceptive serves clients in a wide range of industries. The company is headquartered in Shawnee, Kansas and, according to their About page, is currently hiring.
Folks at Jive Software are convinced that “social business is the future.” This is why they employ the latest technology to help clients cultivate crowdsourcing, collaboration, and customer engagement, forces they say are bound to improve the business world for both customers and workers. Founded in 2012, Jive already has five far-flung offices, including their headquarters in Palo Alto, California.
Cynthia Murrell, November 06, 2013
Sponsored by ArnoldIT.com, developer of Augmentext
-

- Subscribe to Beyond Search
Feature archive
News archive

-