

Governance Information for Office 365
August 18, 2014
Short honk: I am not sure what governance means. But search and content processing vendors bandy about words better than Serena Williams hits tennis balls. If you are governance hungry and use Office 365, Concept Searching has an “online information source” for you. More information is at http://bit.ly/1teO5fA. My hunch is that you will learn to license some smart software to index documents. What happens when there is no Internet connection? Oh, no big deal.
Stephen E Arnold, August 18, 2014
Attensity Leverages Biz360 Invention
August 4, 2014
In 2010, Attensity purchased Biz360. The Beyond Search comment on this deal is at http://bit.ly/1p4were. One of the goslings reminded me that I had not instructed a writer to tackle Attensity’s July 2014 announcement “Attensity Adds to Patent Portfolio for Unstructured Data Analysis Technology.” PR-type “stories” can disappear, but for now you can find a description of “Attensity Adds to Patent Portfolio for Unstructured Data Analysis Technology” at http://reut.rs/1qU8Sre.
My researcher showed me a hard copy of 8,645,395, and I scanned the abstract and claims. The abstract, like many search and content processing inventions, seemed somewhat similar to other text parsing systems and methods. The invention was filed in April 2008, two years before Attensity purchased Biz360, a social media monitoring company. Attensity, as you may know, is a text analysis company founded by Dr. David Bean. Dr. Bean employed various “deep” analytic processes to figure out the meaning of words, phrases, and documents. My limited understanding of Attensity’s methods suggested to me that Attensity’s Bean-centric technology could process text to achieve a similar result. I had a phone call from AT&T regarding the utility of certain Attensity outputs. I assume that the Bean methods required some reinforcement to keep pace with customers’ expectations about Attensity’s Bean-centric system. Neither the goslings nor I are patent attorneys. So after you download 395, seek out a patent attorney and get him/her to explain its mysteries to you.
The abstract states:
A system for evaluating a review having unstructured text comprises a segment splitter for separating at least a portion of the unstructured text into one or more segments, each segment comprising one or more words; a segment parser coupled to the segment splitter for assigning one or more lexical categories to one or more of the one or more words of each segment; an information extractor coupled to the segment parser for identifying a feature word and an opinion word contained in the one or more segments; and a sentiment rating engine coupled to the information extractor for calculating an opinion score based upon an opinion grouping, the opinion grouping including at least the feature word and the opinion word identified by the information extractor.
This invention tackles the Mean Joe Green of content processing from the point of view of a quite specific type of content: A review. Amazon has quite a few reviews, but the notion of an “shaped” review is a thorny one. See, for example, http://bit.ly/1pz1q0V.) The invention’s approach identifies words with different roles; some words are “opinion words” and others are “feature words.” By hooking a “sentiment engine” to this indexing operation, the Biz360 invention can generate an “opinion score.” The system uses item, language, training model, feature, opinion, and rating modifier databases. These, I assume, are either maintained by subject matter experts (expensive), smart software working automatically (often evidencing “drift” so results may not be on point), or a hybrid approach (humans cost money).

The Attensity/Biz360 system relies on a number of knowledge bases. How are these updated? What is the latency between identifying new content and updating the knowledge bases to make the new content available to the user or a software process generating an alert or another type of report?
The 20 claims embrace the components working as a well oiled content analyzer. The claim I noted is that the system’s opinion score uses a positive and negative range. I worked on a sentiment system that made use of a stop light metaphor: red for negative sentiment and green for positive sentiment. When our system could not figure out whether the text was positive or negative we used a yellow light.

The approach used for a US government project a decade ago, used a very simple metaphor to communicate a situation without scores, values, and scales. Image source: http://bit.ly/1tNvkT8
Attensity said, according the news story cited above:
By splitting the unstructured text into one or more segments, lexical categories can be created and a sentiment-rating engine coupled to the information can now evaluate the opinions for products, services and entities.
Okay, but I think that the splitting of text into segment was a function of iPhrase and search vendors converting unstructured text into XML and then indexing the outputs.
Attensity’s Jonathan Schwartz, General Counsel at Attensity is quoted in the news story as asserting:
“The issuance of this patent further validates the years of research and affirms our innovative leadership. We expect additional patent issuances, which will further strengthen our broad IP portfolio.”
Okay, this sounds good but the invention took place prior to Attensity’s owning Biz360. Attensity, therefore, purchased the invention of folks who did not work at Attensity in the period prior to the filing in 2008. I understand that company’s buy other companies to get technology and people. I find it interesting that Attensity’s work “validates” Attensity’s research and “affirms” Attensity’s “innovative leadership.”
I would word what the patent delivers and Attensity’s contributions differently. I am no legal eagle or sentiment expert. I do like less marketing razzle dazzle, but I am in the minority on this point.
Net net: Attensity is an interesting company. Will it be able to deliver products that make the licensees’ sentiment score move in a direction that leads to sustaining revenue and generous profits. With the $90 million in funding the company received in 2014, the 14-year-old company will have some work to do to deliver a healthy return to its stakeholders. Expert System, Lexalytics, and others are racing down the same quarter mile drag strip. Which firm will be the winner? Which will blow an engine?
Stephen E Arnold, August 4, 2014
Training Your Smart Search System
August 2, 2014
With the increasing chatter about smart software, I want to call to your attention this article, “Improving the Way Neural Networks Learn.” Keep in mind that some probabilistic search systems have to be trained on content that closely resembles the content the system will index. The training is important, and training can be time consuming. The licensee has to create a training set of data that is similar to what the software will index. Then the training process is run, a human checks the system outputs, and makes “adjustments.” If the training set is not representative, the indexing will be off. If the human makes corrections that are wacky, then the indexing will be off. When the system is turned loose, the resulting index may return outputs that are not what the user expected or the outputs are incorrect. Whether the system uses knows enough to recognize incorrect results varies from human to human.
If you want to have a chat with your vendor regarding the time required to train or re-train a search system relying on sample content, print out this article. If the explanation does not make much sense to you, you can document off query results sets, complain to the search system vendor, or initiate a quick fix. Note that quick fixes involve firing humans believed to be responsible for the system, initiate a new search procurement, or pretend that the results are just fine. I suppose there are other options, but I have encountered these three approach seasoned with either legal action or verbal grousing to the vendor. Even when the automated indexing is tuned within an inch of its life, accuracy is likely to start out in the 85 to 90 percent range and then degrade.
Training can be a big deal. Ignoring the “drift” that occurs when the smart software has been taught or learned something that distorts the relevance of results can produce some sharp edges.
Stephen E Arnold, August 2, 2014
Meme Attention Deficit
April 27, 2014
I read “Algorithm Distinguishes Memes from Ordinary Information.” The article reports that algorithms can pick out memes. A “meme”, according to Google, is “an element of a culture or system of behavior that may be considered to be passed from one individual to another by nongenetic means, especially imitation.” The passage that caught my attention is:
Having found the most important memes, Kuhn and co studied how they have evolved in the last hundred years or so. They say most seem to rise and fall in popularity very quickly. “As new scienti?c paradigms emerge, the old ones seem to quickly lose their appeal, and only a few memes manage to top the rankings over extended periods of time,” they say.
The factoid that reminded me how far smart software has yet to travel is:
To test whether these phrases are indeed interesting topics in physics, Kuhn and co asked a number of experts to pick out those that were interesting. The only ones they did not choose were: 12. Rashba, 14. ‘strange nonchaotic’ and 15. ‘in NbSe3′. Kuhn and co also checked Wikipedia, finding that about 40 per cent of these words and phrases have their own corresponding entries. Together this provides compelling evidence that the new method is indeed finding interesting and important ideas.
Systems produce outputs that are not yet spot on. I concluded that scientists, like marketers, like whizzy new phrases and ideas. Jargon, it seems, is an important part of specialist life.
Stephen E Arnold, April 27, 2014
US Government Content Processing: A Case Study
March 24, 2014
I know that the article “Sinkhole of Bureaucracy” is an example of a single case example. Nevertheless, the write up tickled my funny bone. With fancy technology, USA.gov, and the hyper modern content processing systems used in many Federal agencies, reality is stranger than science fiction.
This passage snagged my attention:
inside the caverns of an old Pennsylvania limestone mine, there are 600 employees of the Office of Personnel Management. Their task is nothing top-secret. It is to process the retirement papers of the government’s own workers. But that system has a spectacular flaw. It still must be done entirely by hand, and almost entirely on paper.
One of President Obama’s advisors is quote as describing the manual operation as “that crazy cave.”
And the fix? The article asserts:
That failure imposes costs on federal retirees, who have to wait months for their full benefit checks. And it has imposed costs on the taxpayer: The Obama administration has now made the mine run faster, but mainly by paying for more fingers and feet. The staff working in the mine has increased by at least 200 people in the past five years. And the cost of processing each claim has increased from $82 to $108, as total spending on the retirement system reached $55.8 million.
One of the contractors operating the system is Iron Mountain. You may recall that this outfit has a search system and caught my attention when Iron Mountain sold the quite old Stratify (formerly Purple Yogi automatic indexing system to Autonomy).
My observations:
- Many systems have a human component that managers ignore, do not know about, or lack the management horsepower to address. When search systems or content processing systems generate floods of red ink, human processes are often the culprit
- The notion that modern technology has permeated organizations is false. The cost friction in many companies is directly related to small decisions that grow like a snowball rolling down a hill. When these processes reach the bottom, the mess is no longer amusing.
- Moving significant information from paper to a digital form and then using those data in a meaningful way to answer questions is quite difficult.
Do managers want to tackle these problems? In my experience, keeping up appearances and cost cutting are more important than old fashioned problem solving. In a recent LinkedIn post I pointed out that automatic indexing systems often require human input. Forgetting about those costs produces problems that are expensive to fix. Simple indexing won’t bail out the folks in the cave.
Stephen E Arnold, March 24, 2014
Stephen E Arnold, March 24, 2014
SchemaLogic Profile Available
December 3, 2013
A new profile is available on the Xenky site today. SchemaLogic is a controlled vocabulary management system. The system combines traditional vocabulary management with an organization wide content management system specifically for indexing words and phrases. The analysis provides some insight into how a subsystem can easily boost the cost of a basic search system’s staff and infrastructure.
Taxonomy became a chrome trimmed buzzword almost a decade ago. Indexing has been around a long time, and indexing has a complete body of practices and standards for the practitioner to use when indexing content objects.
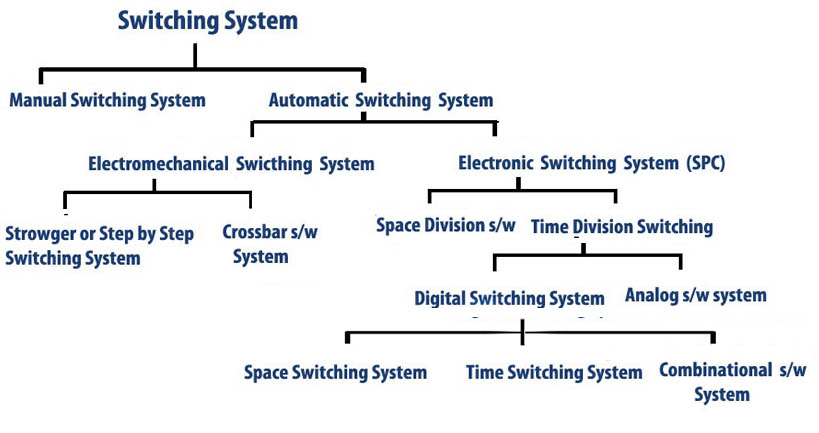
Just what an organization needs to make sense of its text, images, videos, and other digital information/data. At a commercial database publsihing company, more than a dozen people can be involved in managing a controlled term list and classification coding scheme. When a term is misapplied, finding a content object can be quite a challenge. If audio or video are misindexed, the content object may require a human to open, review, and close files until the required imnage or video can be located. Indexing is important, but many MBAs do not understand the cost of indexing until a needed content object cannot be found; for example, in a legal discovery process related to a patent matter. A happy quack to http://swissen.in/swictingsys.php for the example of a single segment of a much larger organization centric taxonomy. Consider managing a controlled term list with more than 20,000 terms and a 400 node taxononmy across a Fortune 500 company or for the information stored in your laptop computer.
Even early birds in the search and content processing sector like Fulcrum Technologies and Verity embraced controlled vocabularies. A controlled term list contains forms of words and phrases and often the classification categories into which individual documents can be tagged.
The problem was that lists of words had to be maintained. Clever poobahs and mavens created new words to describe allegedly new concepts. Scientists, engineers, and other tech types whipped up new words and phrases to help explain their insights. And humans, often loosey goosey with language, shifted meanings. For example, when I was in college a half century ago, there was a class in “discussion.” Today that class might be called “collaboration.” Software often struggles with these language realities.
What happens when “old school” search and content processing systems try to index documents?
The systems can “discover” terms and apply them. Vendors with “smart software” use a range of statistical and linguistic techniques to figure out entities, bound phrases, and concepts. Other approaches include sucking in dictionaries and encyclopedias. The combination of a “knowledgebase” like Wikipedia and other methods works reasonably well.
New Version of Media Mining Indexer (6.2) from SAIL LABS Technology
November 9, 2013
The release titled SAIL LABS Announces New Release Of Media Mining Indexer 6.2 from SAIL LABS Technology on August 5, 2013 provides some insight into the latest version of the Media Mining Indexer. SAIL LABS Technology considers itself as an innovator in creating solutions for vertical markets, and enhancing technologies surrounding advanced language understanding abilities.
The newest release offers such features as:
“Improved named entity detection of names via unified lists across languages… improved topic models for all languages… improved text preprocessing for Greek, Hebrew, Italian, Frasi, US and international English…support of further languages: Catalan, Swedish, Portuguese, Bahasa (Indonesia), Italian, Farsi and Romanian…improved communication with Media Mining Server to relate recognized speakers to their respective profiles.”
Gerhard Backfried, Head of Research at SAIL LABS, called the latest release a “quantum leap forward” considering the system’s tractability, constancy and ability to respond to clients needs. The flagship product is based on SAIL LABS speech recognition technology, which as won awards, and offers a suite of ideal components for multimedia processing, and the transformation of audio and video data into searchable information. The features boast the ability to convert speech to text accurately with Automatic Speech Recognition and the ability to detect different speakers with Speaker Change Detection.
Chelsea Kerwin, November 09, 2013
Sponsored by ArnoldIT.com, developer of Augmentext
Database Indexing Explained
July 29, 2013
Finally, everything you need to explain database indexing to your mom over breakfast. Stack Overflow hosts the discussion, “How Does Database Indexing Work?” The original question, posed by a user going by Zenph Yan, asks for an answer at a “database agnostic level.” The lead answer, also submitted by Zenph Yan, makes for a respectable article all by itself. (Asked and answered by the same user? Odd, perhaps, but that is actively encouraged at Stack Overflow.)
Yan clearly defines the subject at hand:
“Indexing is a way of sorting a number of records on multiple fields. Creating an index on a field in a table creates another data structure which holds the field value, and pointer to the record it relates to. This index structure is then sorted, allowing Binary Searches to be performed on it.
“The downside to indexing is that these indexes require additional space on the disk, since the indexes are stored together in a table using the MyISAM engine, this file can quickly reach the size limits of the underlying file system if many fields within the same table are indexed.”
Yan’s explanation also describes why indexing is needed, how it works (with examples), and when it is called for. It is worth checking out for those pondering his question. A couple other users contributed links to helpful resources. Der U suggests another Stack Overflow discussion, “What do Clustered and Non Clustered Index Actually Mean?“, while one, dohaivu, recommends the site, Use the Index, Luke.
Cynthia Murrell, July 29, 2013
Sponsored by ArnoldIT.com, developer of Augmentext
Tag Management Systems Use Governance to Improve Indexing
March 18, 2013
An SEO expert advocates better indexing in the recent article “Top 5 Arguments For Implementing a Tag Management Solution” on Search Engine Watch. The article shares that because of increased functionality and matured capabilities of such systems, tag management is set for a “blowout year” in 2013.
Citing such reasons as ease of modifying tags and cost reduction, it is easy to see how businesses will begin to adopt these systems if they haven’t already. I found the point on code portability and becoming vendor agnostic most appealing:
“As the analytics industry matures, many of us are faced with sharing information between different systems, which can be a huge challenge with respect to back-end integrations. Tag management effectively bridges the gap between several front-end tagging methodologies that can be used to leverage existing development work and easily port information from one script or beacon to another.”
I think this is a very interesting concept and I love the notion of governance as a way to improve indexing. I am reminded of the original method from the days of the library at Ephesus. Next month, the same author will tackle the most common arguments against implementing a tag management system. We will keep an eye out.
Andrea Hayden, March 18, 2013
Sponsored by ArnoldIT.com, developer of Beyond Search
LucidWorks Interviews Update
March 8, 2013
We had a report of Lucid Imagination and LucidWorks links on an index page not resolving on an index page. If you are looking for these interviews, here’s a snapshot of the interviews we have conducted since 2009 with LucidWorks’ professionals.
Mark Bennett
LucidWorks, March 4, 2013
Miles Kehoe
LucidWorks, January 29, 2013
Paul Doscher
LucidWorks, April 16, 2012
Brian Pinkerton
LucidWorks, December 21, 2010
Marc Krellenstein
Lucid Imagination, March 17, 2009
Remember. LucidWorks is the new name for Lucid Imagination.
Tony Safina, March 8, 2013
-

- Subscribe to Beyond Search
Feature archive
News archive

-